Questões de Banco de Dados para Concurso
Foram encontradas 12.812 questões
Ano: 2024
Banca:
Instituto Consulplan
Órgão:
DPE-PR
Prova:
Instituto Consulplan - 2024 - DPE-PR - Analista da Defensoria Pública - Informática |
Q2353613
Banco de Dados
Visões (views) são procedimentos fornecidos pelos SGBDs para trabalhar com consultas prontas, como uma tabela virtual,
que não armazena dados. Considerando as características de visões, assinale a afirmativa INCORRETA.
Ano: 2024
Banca:
Instituto Consulplan
Órgão:
DPE-PR
Prova:
Instituto Consulplan - 2024 - DPE-PR - Analista da Defensoria Pública - Informática |
Q2353612
Banco de Dados
Mineração de dados (Data Mining) pode ser definido como o processo de analisar bases de dados de grande porte, a fim de descobrir
informações por meio de consultas. Tendo em vista as fases do processo de KDD (Knowlegde Discovery in Databases, descoberta de
conhecimento nos bancos de dados) utilizado em Data Mining, marque V para as afirmativas verdadeiras e F para as falsas.
( ) Mineração de dados: fase responsável pela escolha dos algoritmos a serem aplicados para a descoberta de informações. Essa escolha depende fundamentalmente dos objetivos do processo de KDD.
( ) Preparação dos dados: nessa fase, os dados necessários para a solução de um problema são selecionados na base de dados. Essa etapa inicia-se a partir do agrupamento organizado de uma grande quantidade de dados de uma ou mais bases de dados, selecionando somente aqueles que são relevantes.
( ) Limpeza dos dados: essa fase consome grande parte do esforço necessário para todo o processo devido à dificuldade de integrar bases de dados heterogêneas.
( ) Interpretação: ao final do processo, o sistema de mineração de dados gera um relatório das descobertas, que passa então a ser interpretado por analistas de mineração. Somente após essa interpretação obtém-se o conhecimento.
A sequência está correta em
( ) Mineração de dados: fase responsável pela escolha dos algoritmos a serem aplicados para a descoberta de informações. Essa escolha depende fundamentalmente dos objetivos do processo de KDD.
( ) Preparação dos dados: nessa fase, os dados necessários para a solução de um problema são selecionados na base de dados. Essa etapa inicia-se a partir do agrupamento organizado de uma grande quantidade de dados de uma ou mais bases de dados, selecionando somente aqueles que são relevantes.
( ) Limpeza dos dados: essa fase consome grande parte do esforço necessário para todo o processo devido à dificuldade de integrar bases de dados heterogêneas.
( ) Interpretação: ao final do processo, o sistema de mineração de dados gera um relatório das descobertas, que passa então a ser interpretado por analistas de mineração. Somente após essa interpretação obtém-se o conhecimento.
A sequência está correta em
Ano: 2024
Banca:
Instituto Consulplan
Órgão:
DPE-PR
Prova:
Instituto Consulplan - 2024 - DPE-PR - Analista da Defensoria Pública - Informática |
Q2353611
Banco de Dados
O comando SQL ALTER TABLE pertence ao grupo de comandos DDL do SQL. São características do comando SQL ALTER TABLE,
EXCETO:
Ano: 2024
Banca:
Instituto Consulplan
Órgão:
DPE-PR
Prova:
Instituto Consulplan - 2024 - DPE-PR - Analista da Defensoria Pública - Informática |
Q2353610
Banco de Dados
Questão 41
SQL é uma linguagem declarativa baseada em álgebra e cálculo relacional, que permite a manipulação de dados com suporte
a estrutura de dados, regras e restrições de integridade. Para que o SQL forneça tantos recursos, seus comandos são divididos
em grupos. Considerando os grupos dos comandos SQL, relacione adequadamente as colunas a seguir.
1. DDL.
2. DML.
3. DCL.
4. DTL.
5. DQL.
( ) Permite a manipulação dos dados, ou seja, inclusão, alteração e exclusão de dados.
( ) Oferece comandos para trabalhar com transações.
( ) Proporciona consulta de dados.
( ) Permite determinar o esquema do banco de dados, bem como alterá-lo, exclui-lo e trabalhar com os metadados.
( ) Permite controlar a licença e a autorização de acesso dos usuários para com os dados.
A sequência está correta em
1. DDL.
2. DML.
3. DCL.
4. DTL.
5. DQL.
( ) Permite a manipulação dos dados, ou seja, inclusão, alteração e exclusão de dados.
( ) Oferece comandos para trabalhar com transações.
( ) Proporciona consulta de dados.
( ) Permite determinar o esquema do banco de dados, bem como alterá-lo, exclui-lo e trabalhar com os metadados.
( ) Permite controlar a licença e a autorização de acesso dos usuários para com os dados.
A sequência está correta em
Ano: 2024
Banca:
Instituto Consulplan
Órgão:
DPE-PR
Prova:
Instituto Consulplan - 2024 - DPE-PR - Analista da Defensoria Pública - Informática |
Q2353601
Banco de Dados
Sobre os tópicos relacionados à tecnologia e informação com suas respectivas categorias de armazenamento e análise de
dados, relacione adequadamente as colunas a seguir.
1. Data Warehouse.
2. Data Mart.
3. Data Lake.
4. Big Data.
5. Business Intelligence e Analytics.
6. Mineração de Dados.
( ) Ambiente de armazenamento de dados centralizado que integra informações de várias fontes para suportar a análise de negócios.
( ) Conjunto de ferramentas, técnicas e processos para coletar, organizar e analisar informações para fins estratégicos.
( ) Subconjunto de um Data Warehouse, geralmente focado em um único departamento ou área de negócios.
( ) Processo de descoberta de padrões, tendências e informações úteis em conjuntos de dados.
( ) Abordagem flexível e escalável para armazenar grandes volumes de dados de diferentes tipos.
( ) Conjuntos de dados extremamente grandes e complexos, muitas vezes além da capacidade de ferramentas de processamento de dados tradicionais.
A sequência está correta em
1. Data Warehouse.
2. Data Mart.
3. Data Lake.
4. Big Data.
5. Business Intelligence e Analytics.
6. Mineração de Dados.
( ) Ambiente de armazenamento de dados centralizado que integra informações de várias fontes para suportar a análise de negócios.
( ) Conjunto de ferramentas, técnicas e processos para coletar, organizar e analisar informações para fins estratégicos.
( ) Subconjunto de um Data Warehouse, geralmente focado em um único departamento ou área de negócios.
( ) Processo de descoberta de padrões, tendências e informações úteis em conjuntos de dados.
( ) Abordagem flexível e escalável para armazenar grandes volumes de dados de diferentes tipos.
( ) Conjuntos de dados extremamente grandes e complexos, muitas vezes além da capacidade de ferramentas de processamento de dados tradicionais.
A sequência está correta em
Ano: 2024
Banca:
SELECON
Órgão:
Prefeitura de Sapezal - MT
Prova:
SELECON - 2024 - Prefeitura de Sapezal - MT - Professor de Informática |
Q2353322
Banco de Dados
No funcionamento de bancos de dados, é de suma
importância preservar a integridade dos dados e de todos os
pontos intermediários em transações. Nesse contexto, há duas
operações envolvidas com o gerenciador de transações.
I. Operação que indica o término bem-sucedido de uma transação. Se a transação for concluída com êxito, o banco de dados é alterado permanentemente.
II. Operação que assinala o término malsucedido de uma transação. Quando ocorrer falha em qualquer uma das operações que fazem parte da transação, o banco de dados retorna ao estado anterior do início da transação.
Essas operações são conhecidas, respectivamente, por:
I. Operação que indica o término bem-sucedido de uma transação. Se a transação for concluída com êxito, o banco de dados é alterado permanentemente.
II. Operação que assinala o término malsucedido de uma transação. Quando ocorrer falha em qualquer uma das operações que fazem parte da transação, o banco de dados retorna ao estado anterior do início da transação.
Essas operações são conhecidas, respectivamente, por:
Ano: 2024
Banca:
FGV
Órgão:
Câmara Municipal de São Paulo - SP
Prova:
FGV - 2024 - Câmara Municipal de São Paulo - SP - Técnico Legislativo - Informática |
Q2352997
Banco de Dados
O Diagrama Entidade-Relacionamento abaixo foi criado utilizando
a notação de Peter Chen:
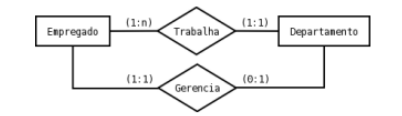
Considere as afirmativas acerca deste diagrama e do modelo Entidade-Relacionamento:
I. No diagrama acima os losangos denominados ‘Trabalha’ e ‘Gerencia’ são denominados de Entidades do modelo;
II. A notação das cardinalidades define seus valores na forma (mínima, máxima);
III. O Modelo Entidade-Relacionamento permite associar atributos tanto a entidades como a relacionamentos.
Está correto apenas o que se afirma em
Considere as afirmativas acerca deste diagrama e do modelo Entidade-Relacionamento:
I. No diagrama acima os losangos denominados ‘Trabalha’ e ‘Gerencia’ são denominados de Entidades do modelo;
II. A notação das cardinalidades define seus valores na forma (mínima, máxima);
III. O Modelo Entidade-Relacionamento permite associar atributos tanto a entidades como a relacionamentos.
Está correto apenas o que se afirma em
Ano: 2024
Banca:
CESPE / CEBRASPE
Órgão:
CNPQ
Prova:
CESPE / CEBRASPE - 2024 - CNPQ - Analista em Ciência e Tecnologia Pleno I - Especialidade: Desenvolvimento e Arquitetura de Software |
Q2352332
Banco de Dados
Julgue o item seguinte, a respeito do desenvolvimento orientado ao comportamento (BDD).
A linguagem ubíqua Cucumber é utilizada para a definição
de cenários iniciais no BDD e permite que a equipe de
negócios faça levantamentos com as partes interessadas
(stakeholders) e os transforme em histórias do usuário
(user story).
Ano: 2024
Banca:
CESPE / CEBRASPE
Órgão:
CNPQ
Prova:
CESPE / CEBRASPE - 2024 - CNPQ - Analista em Ciência e Tecnologia Pleno I - Especialidade: Desenvolvimento e Arquitetura de Software |
Q2352331
Banco de Dados
Julgue o item seguinte, a respeito do desenvolvimento orientado ao comportamento (BDD).
Durante o período do BDD, os planos serão validados pelos
desenvolvedores conforme previsto pelo TDD por meio de
ferramentas de teste como JUnit e Mockito.
Ano: 2024
Banca:
Instituto Consulplan
Órgão:
Prefeitura de Campos dos Goytacazes - RJ
Prova:
Instituto Consulplan - 2024 - Prefeitura de Campos dos Goytacazes - RJ - Analista de Sistemas |
Q2351717
Banco de Dados
O Big data é estruturado seguindo os conceitos dos 5 V’s; assinale-os.
Ano: 2024
Banca:
Instituto Consulplan
Órgão:
Prefeitura de Campos dos Goytacazes - RJ
Prova:
Instituto Consulplan - 2024 - Prefeitura de Campos dos Goytacazes - RJ - Analista de Sistemas |
Q2351716
Banco de Dados
Considere o seguinte cenário em certo banco de dados de uma loja on-line criada no Mysql Workbench:

Determinado profissional deverá criar uma stored procedure chamada CalcularTotalPedido, que recebe um parâmetro PedidoID e calcula o valor total do pedido com base nos detalhes do pedido. Representa corretamente a implementação dessa stored procedure:
Determinado profissional deverá criar uma stored procedure chamada CalcularTotalPedido, que recebe um parâmetro PedidoID e calcula o valor total do pedido com base nos detalhes do pedido. Representa corretamente a implementação dessa stored procedure:
Ano: 2024
Banca:
Instituto Consulplan
Órgão:
Prefeitura de Campos dos Goytacazes - RJ
Prova:
Instituto Consulplan - 2024 - Prefeitura de Campos dos Goytacazes - RJ - Analista de Sistemas |
Q2351715
Banco de Dados
Uma transação é uma unidade de execução do programa que acessa e, possivelmente, atualiza vários itens de dados. Normalmente, uma transação é iniciada por um programa do usuário escrito em linguagem de manipulação de dados (normalmente
SQL) ou linguagem de programação (por exemplo: C++ ou Java), com acessos embutidos ao banco de dados em JDBC ou ODBC.
Em um contexto de transações em bancos de dados, sobre a propriedade de “isolamento”, assinale a afirmativa correta.
Ano: 2024
Banca:
Instituto Consulplan
Órgão:
Prefeitura de Campos dos Goytacazes - RJ
Prova:
Instituto Consulplan - 2024 - Prefeitura de Campos dos Goytacazes - RJ - Analista de Sistemas |
Q2351714
Banco de Dados
Observe o seguinte esquema textual de uma tabela, não necessariamente normalizada, referente a uma base de dados
de livros:
Livro (ISBN,Titulo, AnoPublicacao, IdAutor, NomeAutor, PaísOrigem, IdEditora, NomeEditora)
Em que forma normal se encontra esta tabela?
Livro (ISBN,Titulo, AnoPublicacao, IdAutor, NomeAutor, PaísOrigem, IdEditora, NomeEditora)
Em que forma normal se encontra esta tabela?
Ano: 2024
Banca:
Instituto Consulplan
Órgão:
Prefeitura de Campos dos Goytacazes - RJ
Prova:
Instituto Consulplan - 2024 - Prefeitura de Campos dos Goytacazes - RJ - Analista de Sistemas |
Q2351713
Banco de Dados
Considere a relação entre as entidades “Funcionário”, “Departamento” e “Projeto” em um Modelo Entidade-Relacionamento
(MER) para um sistema de informação de determinada prefeitura, que precisa gerenciar informações sobre funcionários,
departamentos e projetos.
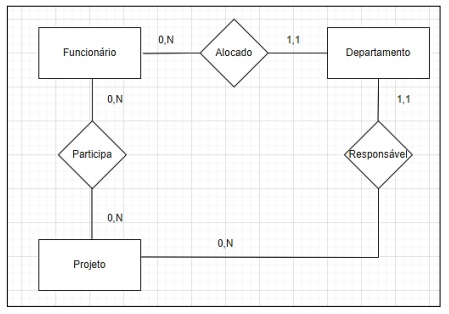
Analise as afirmativas a seguir.
I. A cardinalidade mínima 1 apresentada no diagrama recebe a denominação de “associação obrigatória”, já que ela indica que o relacionamento deve, obrigatoriamente, associar uma ocorrência de entidade a cada ocorrência da entidade em questão.
II. A cardinalidade máxima pode ser usada para classificar relacionamentos binários. É possível classificar os relacionamentos binários em n:n, 1:n e 1:1.
III. A cardinalidade 0 no diagrama indica que pode não haver associação (ninguém associado) a uma ocorrência da entidade a cada ocorrência da entidade em questão.
IV. A cardinalidade máxima indica o número máximo de ocorrências que cada associação deve ter; por exemplo, ao limitar um número máximo de 30 projetos por departamento, troca-se o 0 por 30 na relação projeto-departamento.
Está correto o que se afirma apenas em
Analise as afirmativas a seguir.
I. A cardinalidade mínima 1 apresentada no diagrama recebe a denominação de “associação obrigatória”, já que ela indica que o relacionamento deve, obrigatoriamente, associar uma ocorrência de entidade a cada ocorrência da entidade em questão.
II. A cardinalidade máxima pode ser usada para classificar relacionamentos binários. É possível classificar os relacionamentos binários em n:n, 1:n e 1:1.
III. A cardinalidade 0 no diagrama indica que pode não haver associação (ninguém associado) a uma ocorrência da entidade a cada ocorrência da entidade em questão.
IV. A cardinalidade máxima indica o número máximo de ocorrências que cada associação deve ter; por exemplo, ao limitar um número máximo de 30 projetos por departamento, troca-se o 0 por 30 na relação projeto-departamento.
Está correto o que se afirma apenas em
Ano: 2024
Banca:
FGV
Órgão:
Prefeitura de São José dos Campos - SP
Prova:
FGV - 2024 - Prefeitura de São José dos Campos - SP - Auditor Tributário Municipal |
Q2348991
Banco de Dados
Com relação ao Big Data e suas tecnologias, assinale V para a
afirmativa verdadeira e F para a falsa.
( ) Existem diversas tecnologias para processamento e análise de Big Data, mas a maioria possui algumas características comuns. Ou seja, adotam técnicas de escalonamento e processamento paralelo; utilizam dados não relacionais, e aplicam análises avançadas e visualização de dados.
( ) Existem três tecnologias de Big Data que se destacam: MapReduce, Hadoop e NoSQL. O Hadoop é uma técnica popularizada pelo Google que distribui o processamento de dados em grandes arquivos de dados multiestruturados em um grande cluster que pode ser alcançado dividindo o processamento em pequenas unidades de trabalho que podem ser executadas em paralelo.
( ) O MapReduce é um modelo de programação e uma implementação associada para processar e gerar grandes conjuntos de dados. Os programas escritos neste estilo funcional são automaticamente paralelizados e executados em um grande cluster de máquinas de alto desempenho. O modelo que programadores sem qualquer experiência com sistemas paralelos e distribuídos utilizem facilmente os recursos.
As afirmativas são, respectivamente,
( ) Existem diversas tecnologias para processamento e análise de Big Data, mas a maioria possui algumas características comuns. Ou seja, adotam técnicas de escalonamento e processamento paralelo; utilizam dados não relacionais, e aplicam análises avançadas e visualização de dados.
( ) Existem três tecnologias de Big Data que se destacam: MapReduce, Hadoop e NoSQL. O Hadoop é uma técnica popularizada pelo Google que distribui o processamento de dados em grandes arquivos de dados multiestruturados em um grande cluster que pode ser alcançado dividindo o processamento em pequenas unidades de trabalho que podem ser executadas em paralelo.
( ) O MapReduce é um modelo de programação e uma implementação associada para processar e gerar grandes conjuntos de dados. Os programas escritos neste estilo funcional são automaticamente paralelizados e executados em um grande cluster de máquinas de alto desempenho. O modelo que programadores sem qualquer experiência com sistemas paralelos e distribuídos utilizem facilmente os recursos.
As afirmativas são, respectivamente,
Ano: 2024
Banca:
FGV
Órgão:
Prefeitura de São José dos Campos - SP
Prova:
FGV - 2024 - Prefeitura de São José dos Campos - SP - Auditor Tributário Municipal |
Q2348989
Banco de Dados
Relacione as características de um data warehouse listadas a
seguir com suas descrições, conforme estabelecido por William
Inmon.
1. Orientados a Assunto.
2. Integração.
3. Não Volátil.
4. Variante no Tempo.
( ) O foco de um data warehouse na mudança ao longo do tempo é essencial para descobrir tendências e identificar padrões e relacionamentos ocultos nos negócios, para isso os analistas precisam de grandes quantidades de dados. Isso contrasta muito com o processamento de transações on-line onde os requisitos de desempenho exigem que os dados históricos sejam movidos para arquivos.
( ) Os data warehouses devem colocar dados de fontes diferentes em um formato consistente. Eles devem resolver problemas como nomear conflitos e inconsistências entre unidades de medida.
( ) Significa que, uma vez inseridos no data warehouse, os dados não devem mudar. Essa característica é lógica porque o propósito de um data warehouse é permitir que um analista analise o que ocorreu no passado.
( ) Os data warehousessão projetados para ajudar os profissionais a analisar grandes volumes de dados. Por exemplo, para saber mais sobre os dados de vendas de uma empresa, o analista pode construir um data warehouse que concentre a venda. Usando esse data warehouse, ele poderá responder perguntas como "Quem foi nosso melhor cliente para este item no ano passado?" ou "Quem provavelmente será nosso melhor cliente no próximo ano?"
A relação correta, na ordem dada, é:
1. Orientados a Assunto.
2. Integração.
3. Não Volátil.
4. Variante no Tempo.
( ) O foco de um data warehouse na mudança ao longo do tempo é essencial para descobrir tendências e identificar padrões e relacionamentos ocultos nos negócios, para isso os analistas precisam de grandes quantidades de dados. Isso contrasta muito com o processamento de transações on-line onde os requisitos de desempenho exigem que os dados históricos sejam movidos para arquivos.
( ) Os data warehouses devem colocar dados de fontes diferentes em um formato consistente. Eles devem resolver problemas como nomear conflitos e inconsistências entre unidades de medida.
( ) Significa que, uma vez inseridos no data warehouse, os dados não devem mudar. Essa característica é lógica porque o propósito de um data warehouse é permitir que um analista analise o que ocorreu no passado.
( ) Os data warehousessão projetados para ajudar os profissionais a analisar grandes volumes de dados. Por exemplo, para saber mais sobre os dados de vendas de uma empresa, o analista pode construir um data warehouse que concentre a venda. Usando esse data warehouse, ele poderá responder perguntas como "Quem foi nosso melhor cliente para este item no ano passado?" ou "Quem provavelmente será nosso melhor cliente no próximo ano?"
A relação correta, na ordem dada, é:
Ano: 2024
Banca:
FGV
Órgão:
Prefeitura de São José dos Campos - SP
Prova:
FGV - 2024 - Prefeitura de São José dos Campos - SP - Auditor Tributário Municipal |
Q2348988
Banco de Dados
Com relação à linguagem SQL e seus operadores, avalie se as
afirmativas a seguir são verdadeiras (V) ou falsas (F).
( ) O operador LIKE é usado em uma cláusula WHERE para procurar um padrão especificado em uma coluna. Existem dois curingas frequentemente usados em conjunto com este operador; o sinal de % representa zero, um ou vários caracteres, já o sinal de - representa um único caractere.
( ) O operador IN permite especificar vários valores em uma cláusula WHERE. Ele é uma abreviação para múltiplas condições OR e AND sequenciais. Ao usar a palavra-chave NOT na frente do operador IN, haverá o retorno todos os registros que não são nenhum dos valores de uma lista.
( ) A palavra-chave RIGHT JOIN retorna todos os registros da tabela à direita em uma junção e os registros correspondentes da tabela à esquerda em uma junção. O resultado é zero registro do lado esquerdo, se não houver correspondência.
As afirmativas são, respectivamente,
( ) O operador LIKE é usado em uma cláusula WHERE para procurar um padrão especificado em uma coluna. Existem dois curingas frequentemente usados em conjunto com este operador; o sinal de % representa zero, um ou vários caracteres, já o sinal de - representa um único caractere.
( ) O operador IN permite especificar vários valores em uma cláusula WHERE. Ele é uma abreviação para múltiplas condições OR e AND sequenciais. Ao usar a palavra-chave NOT na frente do operador IN, haverá o retorno todos os registros que não são nenhum dos valores de uma lista.
( ) A palavra-chave RIGHT JOIN retorna todos os registros da tabela à direita em uma junção e os registros correspondentes da tabela à esquerda em uma junção. O resultado é zero registro do lado esquerdo, se não houver correspondência.
As afirmativas são, respectivamente,
Q2348257
Banco de Dados
Quanto aos conceitos utilizados no tratamento de dados e na análise de dados e informações, julgue o item.
Na fase de recuperação, de acordo com o modelo de ciclo de vida dos dados (CVD), há o acesso efetivo aos dados pelos profissionais e pesquisadores, ocorrendo, assim, as atividades de consulta e visualização dos dados.
Na fase de recuperação, de acordo com o modelo de ciclo de vida dos dados (CVD), há o acesso efetivo aos dados pelos profissionais e pesquisadores, ocorrendo, assim, as atividades de consulta e visualização dos dados.
Q2348256
Banco de Dados
Quanto aos conceitos utilizados no tratamento de dados e na análise de dados e informações, julgue o item.
De acordo com o modelo de ciclo de vida dos dados (CVD), na fase de coleta, ocorre o planejamento inicial dos dados, bem como sua descrição por meio de metadados, sua avaliação e sua seleção.
De acordo com o modelo de ciclo de vida dos dados (CVD), na fase de coleta, ocorre o planejamento inicial dos dados, bem como sua descrição por meio de metadados, sua avaliação e sua seleção.
Q2348255
Banco de Dados
Quanto aos conceitos utilizados no tratamento de dados e na análise de dados e informações, julgue o item.
A capacidade de aprender, adaptar, raciocinar, resolver problemas e aplicar conhecimento de forma eficaz em contextos variados é definida como informação.
A capacidade de aprender, adaptar, raciocinar, resolver problemas e aplicar conhecimento de forma eficaz em contextos variados é definida como informação.