Questões de Concurso Comentadas sobre banco de dados
Foram encontradas 13.377 questões
Sobre os diversos tipos de triggers no PL/SQL do SGBD Oracle, analise as afirmativas a seguir e assinale (V) para a verdadeira e (F) para a falsa.
( ) Se o trigger for criado em uma tabela ou visão, o evento de gatilho será composto de instruções SQL do tipo DDL e será chamado de trigger de transição cruzada.
( ) Um trigger condicional pode ser um trigger do tipo DML ou de sistema que possui uma cláusula WHEN que especifica uma condição SQL que avalia para cada linha afetada pelas instruções presentes no trigger.
( ) Quando um trigger é acionado, as tabelas às quais ele faz referência podem estar passando por alterações feitas por instruções SQL nas transações iniciadas por outros usuários. As instruções SQL executadas com prioridade em relação as instruções SQL independentes.
As afirmativas são, respectivamente,
Com relação aos tipos de junção suportadas pelo Oracle, analise as afirmativas a seguir e assinale (V) para a verdadeira e (F) para a falsa.
( ) Uma semi-junção é uma junção de uma tabela a si mesma. Esta tabela aparece duas vezes na FROM cláusula e é seguida por aliases de tabela que qualificam os nomes das colunas na condição de junção. Para realizar uma semi-junção, o Oracle Database combina e retorna linhas da tabela que satisfazem a condição de junção.
( ) Uma junção interna estende o resultado de uma junção simples. Essa junção retorna todas as linhas que satisfazem a condição de junção e retorna algumas ou todas as linhas de uma tabela para as quais nenhuma linha da outra satisfaz a condição de junção.
( ) Uma anti-junção retorna linhas do lado esquerdo do predicado para as quais não há linhas correspondentes no lado direito do predicado. Ou seja, ele retorna linhas que não correspondem (NOT IN) à subconsulta do lado direito.
As afirmativas são, respectivamente,
Com relação às vantagens do particionamento no banco de dados Oracle v23c, analise as afirmativas a seguir e assinale (V) para a verdadeira e (F) para a falsa.
( ) Permite que operações de gerenciamento de dados, como, por exemplo, carregamento de dados, criação e reconstrução de índices e operações de backup e restore, apenas no nível de tabela inteira. Isso resulta em tempos significativamente reduzidos para executar essas operações.
( ) Melhora o desempenho das consultas SQL. Muitas vezes, os resultados de uma consulta podem ser obtidos acessando um subconjunto de partições, em vez de acessar a tabela inteira. Para algumas consultas, técnica chamada de remoção de partição pode fornecer ganhos de ordem de magnitude no desempenho.
( ) Aumenta a disponibilidade de bancos de dados de missão crítica se tabelas e índices críticos forem divididos em partições para reduzir as janelas de manutenção. A execução paralela de consultas SQL oferece vantagens específicas para otimizar e minimizar os tempos de execução. A execução paralela é suportada exclusivamente para consultas SQL do tipo DDL.
As afirmativas são, respectivamente,
( ) OLAP é otimizado para transações em tempo real e não é adequado para análises de grandes conjuntos de dados.
( ) Cubos OLAP são estruturas multidimensionais que armazenam dados de maneira organizada para facilitar análises multidimensionais.
( ) Os dados em um cubo OLAP são armazenados de forma linear e unidimensional para facilitar consultas mais rápidas.
Assinale a alternativa que apresenta a sequência correta de cima para baixo.
O ______ é a assimilação e compreensão de informações adquiridas, enquanto a ______ envolve a capacidade de aplicar esse ______ de maneira adaptativa, analítica e inovadora para resolver problemas e tomar decisões eficazes em diferentes contextos.
Assinale a alternativa que preencha correta e respectivamente as lacunas.
É um repositório centralizado de dados que integra informações de várias fontes, transformando e armazenando esses dados de maneira otimizada para análise e geração de relatórios, possibilitando a tomada de decisões estratégicas fundamentadas dentro de uma organização.
Julgue o item a seguir.
No modelo relacional de bancos de dados, a
normalização não é necessária, pois os SGBDs modernos
são capazes de otimizar automaticamente todas as
operações de banco de dados, eliminando a necessidade
de estruturar os dados em formas normais para evitar
redundâncias e dependências.
Julgue o item a seguir.
Em bancos de dados relacionais, um Sistema de
Gerenciamento de Banco de Dados (SGBD) é responsável
por gerenciar e controlar o acesso aos dados. O SGBD
oferece uma interface para a criação, manipulação e
recuperação de dados armazenados, administrando
aspectos como estrutura dos dados, segurança,
integridade, desempenho e disponibilidade.
Julgue o item a seguir.
Na linguagem SQL, utilizada para interagir com bancos de
dados relacionais, os comandos são divididos em
categorias, incluindo DML (Data Manipulation Language)
e DDL (Data Definition Language). DML é usado para
manipular dados (como INSERT, UPDATE, DELETE)
enquanto DDL é usado para definir e gerenciar a estrutura
dos objetos do banco de dados (como CREATE, ALTER,
DROP).
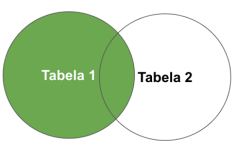
O comando SQL responsável por retornar todos os registros da tabela da esquerda e os registros correspondentes da tabela direita é
O principal motivador para paralelizar uma rotina é
Como viabilizar o compartilhamento efetivo de dados e informações das cadeias agropecuárias entre instituições de governo e dessas com a sociedade? Esta foi a principal questão que os participantes do 1º Painel de Cadeias Agropecuárias e Dados Abertos buscaram responder na tarde de quinta-feira (2/12), durante webinar realizado pelo Instituto de Pesquisa Econômica Aplicada (Ipea).
Disponível em: https://www.ipea.gov.br/portal/categorias/45-todas-as-noticias/noticias/11394-especialistas-debatem-abertura- -e-integracao-de-dados-de-cadeias-agropecuarias?highlight= WyJhYmFzdGVjaW1lbnRvIiwiYWd1YSIsIidcdTAwZTFndWEiLCJhZ3VhJywiXQ==. Acesso em: 5 jan. 2024.
Considerando-se o questionamento apresentado no texto e sabendo-se que, quando da integração de conjuntos de dados de múltiplas fontes, matching é uma questão relevante, o problema de identificação de entidades em múltiplas fontes de dados remete ao desafio de
Qual das seguintes técnicas de normalização numérica é mais adequada para esse conjunto de dados?
A deduplicação de dados é útil, por exemplo, no domínio da medicina, em que há grandes conjuntos de dados genômicos que são analisados para identificar padrões e mutações associadas a doenças específicas. Nesse cenário, a deduplicação é vital para assegurar a precisão das análises, pois, se amostras de DNA de um mesmo paciente são coletadas e sequenciadas em diferentes momentos e locais, pode haver uma repetição inadvertida dessas amostras no banco de dados. Nesse contexto, a deduplicação de dados é crucial para a integridade da pesquisa, pois dados duplicados podem levar a interpretações errôneas, como a superestimação da prevalência de uma mutação genética rara.
A técnica de deduplicação de dados consiste em um processo de
Qual técnica de desidentificação de dados sensíveis é a mais adequada para preservar a privacidade dos indivíduos processados, permitindo, ainda, a análise sociodemográfica dos bairros?