Questões de Concurso Sobre banco de dados
Foram encontradas 16.314 questões
Q2303487
Banco de Dados
Sistemas que se utilizam da estrutura de um
banco de dados relacional, em sua concepção,
devem ter o que se chama de normalização. A
literatura vigente aponta 1FN, 2FN, 3FN e 4FN. A
forma que implementa uma forma de verificação
de dependência funcional Multivalorada é a:
Q2303481
Banco de Dados
Você está planejando uma plataforma de Banco
de Dados que deverá armazenar informações,
como as apresentadas na figura que segue.
Com base nestas informações, e conhecedor de
que você deve escolher um modelo de Banco de
Dados especializado, pois necessita de
desempenho e simplicidade, você optou por
escolher o tipo de Banco de Dados:

Com base nas informações, assinale a alternativa correta.
Com base nas informações, assinale a alternativa correta.
Ano: 2023
Banca:
IV - UFG
Órgão:
Prefeitura de Morrinhos - GO
Prova:
CS-UFG - 2023 - Prefeitura de Morrinhos - GO - Técnico em Suporte de Tecnologia da Informação |
Q2301361
Banco de Dados
No modelo de banco de dados relacional, em que consiste
uma chave primária?
Ano: 2023
Banca:
CONSULPAM
Órgão:
CISCOPAR
Prova:
CONSULPAM - 2023 - CISCOPAR - Analista em Informática |
Q2299271
Banco de Dados
São estratégias para mapear herança em um banco de
dados relacional, EXCETO:
Ano: 2023
Banca:
CONSULPAM
Órgão:
CISCOPAR
Prova:
CONSULPAM - 2023 - CISCOPAR - Analista em Informática |
Q2299270
Banco de Dados
Um Banco de Dados consiste em um conjunto de
dados interrelacionados, agrupados internamente de
acordo com o seu significado no mundo real. Acerca
dos componentes que formam um BD, avalie as
sentenças a seguir:
I- Em um BD, os dados são valores que descrevem objetos e fatos do negócio e/ou problema trabalhado.
II- Os índices de um BD são estruturas de dados que agilizam a consulta aos dados armazenados, realizadas pelos usuários e/ou sistemas.
III- O catálogo de um BD armazena as informações sobre o esquema do banco de dados e seus objetos, além de informações estatísticas para a otimização de consultas aos dados.
Estão CORRETAS as sentenças:
I- Em um BD, os dados são valores que descrevem objetos e fatos do negócio e/ou problema trabalhado.
II- Os índices de um BD são estruturas de dados que agilizam a consulta aos dados armazenados, realizadas pelos usuários e/ou sistemas.
III- O catálogo de um BD armazena as informações sobre o esquema do banco de dados e seus objetos, além de informações estatísticas para a otimização de consultas aos dados.
Estão CORRETAS as sentenças:
Ano: 2023
Banca:
CONSULPAM
Órgão:
CISCOPAR
Prova:
CONSULPAM - 2023 - CISCOPAR - Analista em Informática |
Q2299269
Banco de Dados
Considere o diagrama relacional abaixo, no qual
ilustra o projeto de um banco de dados para uma loja
virtual:
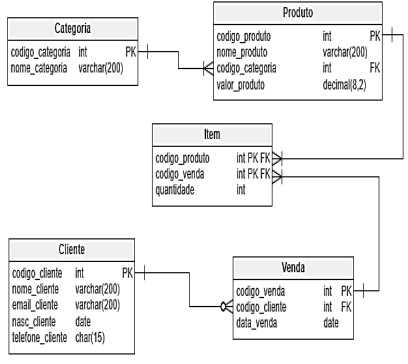
Diante do cenário apresentado, assinale a alternativa CORRETA.
Diante do cenário apresentado, assinale a alternativa CORRETA.
Ano: 2023
Banca:
OBJETIVA
Órgão:
CANOASTEC - RS
Provas:
OBJETIVA - 2023 - CANOASTEC - RS - Analista de Projetos e Sistemas
|
OBJETIVA - 2023 - CANOASTEC - RS - Analista de Infraestrutura de Tecnologia da Informação e Comunicação |
Q2297725
Banco de Dados
João é o responsável por um banco de dados em um
ambiente instável. Essa instabilidade lhe força a,
eventualmente, precisar recuperar o estado do banco de
dados para um determinado momento do dia. Na última
ocorrência desse tipo, João teve que voltar o banco para a
situação em que o sistema estava exatamente às 10h28 da
manhã. Diante desse cenário, o tipo de backup que João
deve sempre ter em mãos é o:
Ano: 2023
Banca:
SELECON
Órgão:
Prefeitura de Campo Verde - MT
Prova:
SELECON - 2023 - Prefeitura de Campo Verde - MT - Técnico em Informática |
Q2297043
Banco de Dados
Quando em uma tabela de um banco de dados há atributos
contendo mais de um valor na mesma tupla, ou atributos
multivalorados, existindo grupos de atributos compostos ou com
possíveis múltiplos campos, diz-se, em relação à normalização,
que a tabela está:
Ano: 2023
Banca:
SELECON
Órgão:
Prefeitura de Campo Verde - MT
Prova:
SELECON - 2023 - Prefeitura de Campo Verde - MT - Técnico em Informática |
Q2297034
Banco de Dados
Observe a seguinte estrutura de tabela existente em um
Banco de Dados Relacional do Banco XYZ:
TABELA(numcli, nomecli, saldo_conta, limite_credito)
Na qual: numcli é o número do cliente no banco e também é a chave primária da TABELA; nomecli é o nome do cliente, saldo_conta é o saldo total na conta do cliente e limite_credito é o limite de crédito do cliente no Banco.
Usando um comando da DML do SQL, caso se deseje alterar o limite de crédito atual dos clientes para 1000 reais, desde que este cliente tenha seu saldo da conta igual a 500 reais e também menor que o limite de crédito atual (antes da atualização), o comando SQL para essa operação vai ser:
TABELA(numcli, nomecli, saldo_conta, limite_credito)
Na qual: numcli é o número do cliente no banco e também é a chave primária da TABELA; nomecli é o nome do cliente, saldo_conta é o saldo total na conta do cliente e limite_credito é o limite de crédito do cliente no Banco.
Usando um comando da DML do SQL, caso se deseje alterar o limite de crédito atual dos clientes para 1000 reais, desde que este cliente tenha seu saldo da conta igual a 500 reais e também menor que o limite de crédito atual (antes da atualização), o comando SQL para essa operação vai ser:
Ano: 2023
Banca:
FAU
Órgão:
Prefeitura de Laranjeiras do Sul - PR
Prova:
FAU - 2023 - Prefeitura de Laranjeiras do Sul - PR - Analista de Sistemas |
Q2296758
Banco de Dados
Qual componente do Microsoft SQL Server
é usado para armazenar e executar
procedimentos armazenados, funções e
gatilhos?
Ano: 2023
Banca:
FAU
Órgão:
Prefeitura de Laranjeiras do Sul - PR
Prova:
FAU - 2023 - Prefeitura de Laranjeiras do Sul - PR - Analista de Sistemas |
Q2296749
Banco de Dados
Qual é o processo principal envolvido na
preparação dos dados para carregamento em
um data warehouse?
Ano: 2023
Banca:
CPCON
Órgão:
UEPB
Prova:
CPCON - 2023 - UEPB - Analista de Sistemas - Banco de Dados |
Q2295826
Banco de Dados
Os bancos de dados NoSQL (Not Only SQL) são sistemas de gerenciamento de banco de dados cujos esquemas de armazenamento de
dados se diferenciam dos tradicionais bancos de dados relacionais. Eles foram propostos para atender às necessidades de
escalabilidade, flexibilidade de esquema e alto desempenho em ambientes de aplicações modernas. Existem várias soluções de bancos
de dados NoSQL e, dentre as mais conhecidas, temos as seguintes soluções:
I- Redis: armazena os dados em memória e permite um acesso extremamente rápido aos dados armazenados.
II- MongoDB: armazena os dados em formato BSON (binário JSON) e oferece uma estrutura flexível sem esquema rígido, permitindo que qualquer estrutura de dados possa ser modelada e manipulada facilmente.
III- Neo4j: otimizado para lidar com dados altamente conectados e complexos, como redes sociais, sistemas de recomendação, análise de dados e outras aplicações em que a estrutura dos dados é fundamental.
Respectivamente, a qual categoria de sistemas de banco de dados NoSQL as soluções I, II e III pertencem?
I- Redis: armazena os dados em memória e permite um acesso extremamente rápido aos dados armazenados.
II- MongoDB: armazena os dados em formato BSON (binário JSON) e oferece uma estrutura flexível sem esquema rígido, permitindo que qualquer estrutura de dados possa ser modelada e manipulada facilmente.
III- Neo4j: otimizado para lidar com dados altamente conectados e complexos, como redes sociais, sistemas de recomendação, análise de dados e outras aplicações em que a estrutura dos dados é fundamental.
Respectivamente, a qual categoria de sistemas de banco de dados NoSQL as soluções I, II e III pertencem?
Ano: 2023
Banca:
CPCON
Órgão:
UEPB
Prova:
CPCON - 2023 - UEPB - Analista de Sistemas - Banco de Dados |
Q2295824
Banco de Dados
As tabelas ALUNOS, TURMAS e HISTORICO, descritas a seguir, representam os alunos de um dado curso, as turmas oferecidas emum dado período e o histórico dos alunos nas turmas, fizeram parte, respectivamente. As definições SQL(aplicada a um banco de dadosPostgreSQL11) destas tabelas estão especificadas abaixo.
ξ CREATE TABLE ALUNOS (matricula char(5) not null primary key, nome varchar(100) not null);
ξ CREATE TABLE TURMAS (cod_turma char(5) not null primary key, periodo_turma char(5) not null);
ξ CREATE TABLE HISTORICO (matric_alu char(5) not null, cod_turma char(5) not null, nota numeric(3,1), primary key(matric_alu,cod_turma), CONSTRAINT foreign key fk_aluno (matric_alu) references ALUNOS (matricula), foreign key fk_turma (cod_turma) references TURMAS (cod_turma));
Observe as instâncias abaixo das tabelas ALUNOS e HISTORICO.
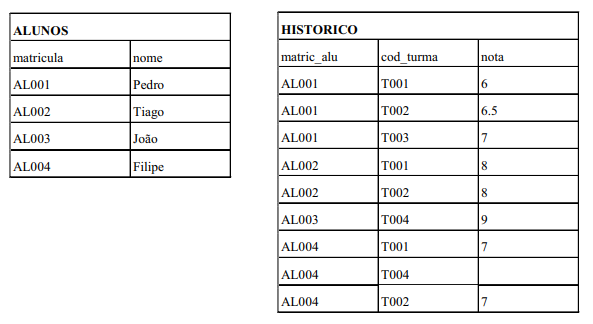
Assinale quantos registros a seguinte consulta SQL, aplicada a um banco de dados PostgreSQL11, retornará.
SELECT nome FROM ALUNOS JOIN HISTORICO ON (ALUNOS.matricula = HISTORICO.matric_alu) WHERE nota > 6 GROUPBYmatricula, nome HAVING COUNT(distinct nota) > 1;
ξ CREATE TABLE ALUNOS (matricula char(5) not null primary key, nome varchar(100) not null);
ξ CREATE TABLE TURMAS (cod_turma char(5) not null primary key, periodo_turma char(5) not null);
ξ CREATE TABLE HISTORICO (matric_alu char(5) not null, cod_turma char(5) not null, nota numeric(3,1), primary key(matric_alu,cod_turma), CONSTRAINT foreign key fk_aluno (matric_alu) references ALUNOS (matricula), foreign key fk_turma (cod_turma) references TURMAS (cod_turma));
Observe as instâncias abaixo das tabelas ALUNOS e HISTORICO.
Assinale quantos registros a seguinte consulta SQL, aplicada a um banco de dados PostgreSQL11, retornará.
SELECT nome FROM ALUNOS JOIN HISTORICO ON (ALUNOS.matricula = HISTORICO.matric_alu) WHERE nota > 6 GROUPBYmatricula, nome HAVING COUNT(distinct nota) > 1;
Ano: 2023
Banca:
CPCON
Órgão:
UEPB
Prova:
CPCON - 2023 - UEPB - Analista de Sistemas - Banco de Dados |
Q2295823
Banco de Dados
O PostgreSql possui um recurso fundamental que permite a recuperação de dados em caso de falhas ou interrupções do sistema,
conhecido como WAL(Write Ahead Logging) ou registro prévio da escrita. O WAL é uma abordagem padrão para registrar transações.
São benefícios do uso do WAL:
I- A garantia de que as alterações feitas em um banco de dados sejam persistentes, mesmo em caso de falhas do sistema, como queda de energia, falha do servidor ou falha no hardware.
II- O custo de sincronizar o registro é muito menor do que o custo de descarregar as páginas de dados.
III- Requer pouco espaço de armazenamento para o log de gravação, pois não ocupa um espaço significativo em disco, mesmo para banco de dados de grande porte com alto volume de transações.
IV- O log de gravação pode ser usado para criar backups incrementais eficientes e para facilitar a replicação assíncrona de dados entre servidores.
Está CORRETO o que se afirma em:
I- A garantia de que as alterações feitas em um banco de dados sejam persistentes, mesmo em caso de falhas do sistema, como queda de energia, falha do servidor ou falha no hardware.
II- O custo de sincronizar o registro é muito menor do que o custo de descarregar as páginas de dados.
III- Requer pouco espaço de armazenamento para o log de gravação, pois não ocupa um espaço significativo em disco, mesmo para banco de dados de grande porte com alto volume de transações.
IV- O log de gravação pode ser usado para criar backups incrementais eficientes e para facilitar a replicação assíncrona de dados entre servidores.
Está CORRETO o que se afirma em:
Ano: 2023
Banca:
CPCON
Órgão:
UEPB
Prova:
CPCON - 2023 - UEPB - Analista de Sistemas - Banco de Dados |
Q2295822
Banco de Dados
Sobre backup de dados, considere o conceito: "A cada novo backup são copiados somente a diferença entre as versões correntes e
anteriores dos arquivos enquanto são criados hardlinks para os arquivos que não foram alterados desde o último backup". Esta
estratégia de armazenamento diz respeito a qual tipo de backup de dados?
Ano: 2023
Banca:
CPCON
Órgão:
UEPB
Prova:
CPCON - 2023 - UEPB - Analista de Sistemas - Banco de Dados |
Q2295821
Banco de Dados
Existe uma cláusula do comando SELECT, considerando os SGBDs MariaDB e PostgreSQL, cujo resultado das funções de agregação
pode ser utilizado em condições para filtragem de registros. Qual é essa cláusula?
Ano: 2023
Banca:
CPCON
Órgão:
UEPB
Prova:
CPCON - 2023 - UEPB - Analista de Sistemas - Banco de Dados |
Q2295820
Banco de Dados
Para descobrir o número de projetos institucionais com títulos que terminam com a letra X, o analista de banco de dados pensou em
resolver a consulta com os comandos SQL abaixo (padrão SQL2 ou superior).
I- SELECTCOUNT(titulo) FROM PROJETO WHERE titulo BEGIN '%X';
II- SELECTCOUNT(*) FROM PROJETO WHERE SUBSTR(titulo, -1) = 'X';
III- SELECTCOUNT(*) FROM PROJETO WHERE titulo LIKE '%X';
IV- SELECTCOUNT(titulo) FROM PROJETO WHERE SUBSTR(titulo, 0) = 'X';
O resultado desejado será observado APENAS na execução de:
I- SELECTCOUNT(titulo) FROM PROJETO WHERE titulo BEGIN '%X';
II- SELECTCOUNT(*) FROM PROJETO WHERE SUBSTR(titulo, -1) = 'X';
III- SELECTCOUNT(*) FROM PROJETO WHERE titulo LIKE '%X';
IV- SELECTCOUNT(titulo) FROM PROJETO WHERE SUBSTR(titulo, 0) = 'X';
O resultado desejado será observado APENAS na execução de:
Ano: 2023
Banca:
CPCON
Órgão:
UEPB
Prova:
CPCON - 2023 - UEPB - Analista de Sistemas - Banco de Dados |
Q2295819
Banco de Dados
Foi solicitado a um analista de banco de dados para que desenvolvesse uma consulta que retornasse todos os cursos, cujo nome fosse
iniciado pela letra 'C', juntamente com seus respectivos campus. Considerando as tabelas 'Curso' e 'Campus' a seguir, relacionadas
pelas colunas 'id_campus', assinale a alternativa que apresenta a consulta SQL, quando aplicada a um banco de dados MariaDB, que o
analista de banco de dados deverá implementar.
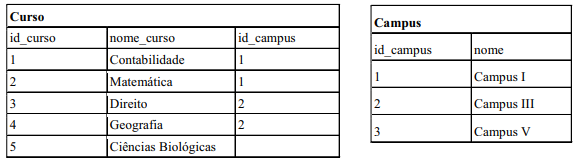
Ano: 2023
Banca:
CPCON
Órgão:
UEPB
Prova:
CPCON - 2023 - UEPB - Analista de Sistemas - Banco de Dados |
Q2295818
Banco de Dados
Considerando os comandos aceitos pelo SGBD MariaDB, analise o seguinte comando SQL e assinale a alternativa que apresenta o
resultado retornado após sua execução.

Ano: 2023
Banca:
CPCON
Órgão:
UEPB
Prova:
CPCON - 2023 - UEPB - Analista de Sistemas - Banco de Dados |
Q2295817
Banco de Dados
Assinale a alternativa que indica, CORRETAMENTE, o valor resultante da execução da consulta SQL apresentada abaixo, quando
aplicada a um banco de dados PostgreSQL 11, que possui tabelas de nomes Campus e Cursos, preenchidas com as seguintes
informações.
SELECTavg(Cursos.orcamento)/count(*) FROM Cursos INNER JOIN Campus on Campus.sigla = Cursos.sigla_campus;
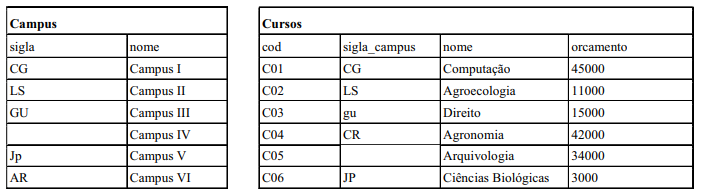
SELECTavg(Cursos.orcamento)/count(*) FROM Cursos INNER JOIN Campus on Campus.sigla = Cursos.sigla_campus;