Questões de Concurso Sobre banco de dados
Foram encontradas 15.979 questões
No que se refere aos sistemas gerenciadores de banco de dados (SGBDs) e à linguagem SQL, julgue o item seguinte.
O comando SQL que deve ser utilizado para alternar, por exemplo, o telefone do psicólogo JOÃO para (61) 91234‑5678 está apresentado a seguir.
UPDATE JOÃO
SET TELEFONE = ‘(61) 91234‑5678’;
No que se refere aos sistemas gerenciadores de banco de dados (SGBDs) e à linguagem SQL, julgue o item seguinte.
DBWn (Database Writer Process) e LGWR (Log Writer Process) são alguns dos processos de segundo plano do SGBD Oracle.
No que se refere aos sistemas gerenciadores de banco de dados (SGBDs) e à linguagem SQL, julgue o item seguinte.
Ao definir o parâmetro innodb_file_per_table do MySQL para “ON” haverá uma melhora na velocidade de leitura, já que não existirão mais atualizações das estatísticas InnoDB.
No que se refere aos sistemas gerenciadores de banco de dados (SGBDs) e à linguagem SQL, julgue o item seguinte.
No SGBD PostgreSQL, uma das finalidades do arquivo pg_hba.conf é permitir a configuração do banco de dados para acesso remoto.
Bancos de dados em memória são inerentemente mais seguros contra falhas de energia que bancos de dados em disco, pois eles armazenam todos os dados em uma cache volátil que é sincronizada automaticamente com o armazenamento persistente.
Em bancos de dados NoSQL distribuídos, o uso de replicação embasada em quórum pode introduzir latência adicional nas operações de escrita, uma vez que um número específico de réplicas deve confirmar a operação antes que ela seja considerada bem-sucedida, o que pode impactar o tempo de resposta do sistema.
Um data lake funciona como uma arquitetura de armazenamento que requer que todos os dados sejam estruturados e limpos antes de serem armazenados.
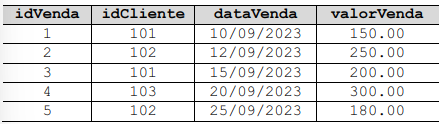
A operação para adicionar uma coluna nova à tabela vendas é realizada por meio de DML.
A execução do comando SQL a seguir apresentará a soma de todas as vendas cujo valor excede 150.00.
SELECT SUM(valorVenda) FROM vendas WHERE valorVenda > 150.00;
As tarefas de eliminar registros da tabela vendas e de criar um índice para otimização de consultas devem ser executadas com DDL.
A integridade referencial garante que os valores de chaves estrangeiras correspondam aos valores válidos na tabela referenciada, mas não impede que essas chaves sejam nulas, desde que a coluna permita valores nulos.
No âmbito da modelagem dimensional, as tabelas de fato armazenam medidas quantitativas que representam eventos de negócios, enquanto as tabelas dimensão contêm dados descritivos que auxiliam na interpretação e na análise das métricas da tabela de fato.
Para que uma tabela de funcionários, que inclua o departamento e o gerente do departamento, esteja na terceira forma normal, é necessário que ela seja dividida para que as informações do gerente estejam armazenadas em uma tabela separada, eliminando-se a dependência transitiva entre funcionário e gerente.
O comando SHOW OPEN TABLES WHERE In_use > 0; é usado para exibir apenas as tabelas que estejam em uso no esquema ativo no momento da execução da consulta.

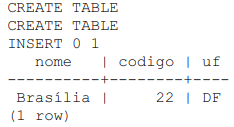
No script precedente, desenvolvido em SQL no PostgreSQL, a substituição dos caracteres #XPTO por References fará que a execução do script apresente o seguinte resultado.
Na abordagem ETL, os dados são carregados no mesmo estado em que foram extraídos e são transformados no estágio posterior ao carregamento.
Na ingestão de dados, a arquitetura lambda utiliza o processamento em lote para fornecer visualizações das informações e utiliza a atualização em tempo real para ajudar os gestores a visualizarem dados críticos e urgentes.
No armazenamento de dados em Big Data, valor é o critério que observa a integração de informações coletadas em diferentes fontes, com vistas a enriquecer as análises.
O Hadoop é uma solução para Big Data e foi desenvolvido para armazenar e processar dados em diferentes máquinas com alta velocidade e baixo custo, permitindo a integração de dados por meio da orquestração deles.
Os bancos de dados em memória apresentam baixa latência, respostas em tempo real e baixo throughput.