Questões de Concurso Sobre banco de dados
Foram encontradas 15.585 questões
Ano: 2022
Banca:
FAURGS
Órgão:
SES-RS
Prova:
FAURGS - 2022 - SES-RS - Analista de Desenvolvimento de Sistemas - Edital nº 15 |
Q1889214
Banco de Dados
Associe os termos dos 5Vs de Big Data às suas respectivas características.
(1) Volume
(2) Velocidade
(3) Variedade
(4) Veracidade
(5) Valor
( ) Dados autênticos e verdadeiros.
( ) Processamento ágil.
( ) Utilidade dos dados.
( ) Fontes de dados muito heterogêneas.
( ) Grande quantidade de dados gerados.
A sequência correta de preenchimento dos parênteses, de cima para baixo, é
(1) Volume
(2) Velocidade
(3) Variedade
(4) Veracidade
(5) Valor
( ) Dados autênticos e verdadeiros.
( ) Processamento ágil.
( ) Utilidade dos dados.
( ) Fontes de dados muito heterogêneas.
( ) Grande quantidade de dados gerados.
A sequência correta de preenchimento dos parênteses, de cima para baixo, é
Ano: 2022
Banca:
FAURGS
Órgão:
SES-RS
Prova:
FAURGS - 2022 - SES-RS - Analista de Desenvolvimento de Sistemas - Edital nº 15 |
Q1889213
Banco de Dados
Observe a figura localizada abaixo, que apresenta um exemplo de composição.
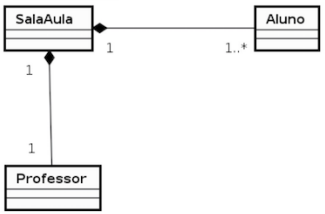
Com base na figura, qual é a afirmativa correta?
Ano: 2022
Banca:
FAURGS
Órgão:
SES-RS
Prova:
FAURGS - 2022 - SES-RS - Analista de Desenvolvimento de Sistemas - Edital nº 15 |
Q1889209
Banco de Dados
Em um Hackaton, inscrevem-se equipes que participam de um desafio. Cada equipe pode ter de 3 a 5 pessoas
(participantes). Para auxiliar as equipes, o evento conta com mentores em diferentes especialidades. Quando
necessitar de auxílio, um membro da equipe registra a solicitação de mentoria. Nessa solicitação deve constar o
participante que solicitou auxílio, o mentor solicitado e a hora da solicitação. Ao final da competição, cada participante
recebe um certificado em que constam seus dados pessoais e de sua equipe. Cada mentor recebe um certificado onde
constam seus dados pessoais e o nome das equipes que solicitaram seu auxílio.
Utilizando o modelo entidade-relacionamento (ER), o analista modelou conceitualmente uma base de dados que atende esses requisitos informacionais. Essa base está representada no diagrama conceitual abaixo, conforme a notação gráfica adotada em Heuser (2009), a qual é baseada na proposta de Peter Chen. Considere que os atributos indicados são os necessários, e que as cardinalidades dos relacionamentos capturam corretamente as restrições do domínio.
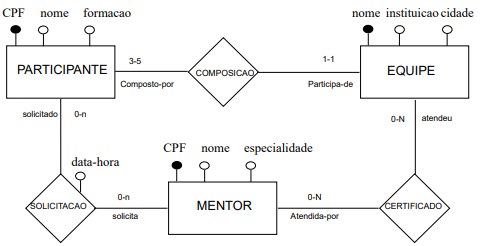
Considerando a modelagem ER acima, qual ou quais relacionamentos são dispensáveis, e poderiam ser eliminados sem prejuízo para os requisitos informacionais a serem atendidos por esse banco de dados?
Utilizando o modelo entidade-relacionamento (ER), o analista modelou conceitualmente uma base de dados que atende esses requisitos informacionais. Essa base está representada no diagrama conceitual abaixo, conforme a notação gráfica adotada em Heuser (2009), a qual é baseada na proposta de Peter Chen. Considere que os atributos indicados são os necessários, e que as cardinalidades dos relacionamentos capturam corretamente as restrições do domínio.
Considerando a modelagem ER acima, qual ou quais relacionamentos são dispensáveis, e poderiam ser eliminados sem prejuízo para os requisitos informacionais a serem atendidos por esse banco de dados?
Ano: 2022
Banca:
FAURGS
Órgão:
SES-RS
Prova:
FAURGS - 2022 - SES-RS - Analista de Desenvolvimento de Sistemas - Edital nº 15 |
Q1889208
Banco de Dados
Considere a tabela ELEITORES descrita pela DDL abaixo (padrão SQL99 ou superior). O significado dos atributos é de
conhecimento comum para eleitores no Brasil: número do título de eleitor, nome do eleitor, endereço onde o
eleitor informou estar domiciliado (incluindo número e complemento), cidade desse domicílio e respectiva unidade
federativa (UF), CEP correspondente a esse domicílio, zona e seção eleitoral desse eleitor.
create table eleitores
(titulo char(12) not null primary key,
nome varchar(250) not null,
endereco varchar(500) not null,
cidade varchar(200) not null,
UF char(2) not null,
cep char(7) not null,
zona char(3) not null,
secao char(4) not null);
Considere as formas normais abaixo, tais como definida por Codd para o modelo relacional.
I - Primeira forma normal (1FN).
II - Segunda forma normal (2FN).
II - Terceira forma normal (3FN).
Quais formas normais essa tabela respeita?
create table eleitores
(titulo char(12) not null primary key,
nome varchar(250) not null,
endereco varchar(500) not null,
cidade varchar(200) not null,
UF char(2) not null,
cep char(7) not null,
zona char(3) not null,
secao char(4) not null);
Considere as formas normais abaixo, tais como definida por Codd para o modelo relacional.
I - Primeira forma normal (1FN).
II - Segunda forma normal (2FN).
II - Terceira forma normal (3FN).
Quais formas normais essa tabela respeita?
Ano: 2022
Banca:
FAURGS
Órgão:
SES-RS
Prova:
FAURGS - 2022 - SES-RS - Administrador de Banco de Dados - Edital nº 15 |
Q1889099
Banco de Dados
Um grupo de tabelas com permissão apenas de leitura
ou consulta que, entre outras informações, mantém
dados sobre: perfis de usuários, papéis e privilégios;
restrições de integridade; índices; alocação de espaço;
descrição de objetos; estrutura geral da base de dados.
Assinale a alternativa que nomeia corretamente o conceito descrito acima, no contexto de um Sistema Gerenciador de Bancos de Dados.
Assinale a alternativa que nomeia corretamente o conceito descrito acima, no contexto de um Sistema Gerenciador de Bancos de Dados.
Ano: 2022
Banca:
FAURGS
Órgão:
SES-RS
Prova:
FAURGS - 2022 - SES-RS - Administrador de Banco de Dados - Edital nº 15 |
Q1889098
Banco de Dados
Qual é o comando que recria uma visão (view) existente
ao alterá-la ao invés de apagá-la, podendo também
ser utilizado para atribuir uma nova permissão e/ou
privilégios?
Ano: 2022
Banca:
FAURGS
Órgão:
SES-RS
Prova:
FAURGS - 2022 - SES-RS - Administrador de Banco de Dados - Edital nº 15 |
Q1889097
Banco de Dados
Sobre a linguagem SQL, é correto afirmar que
Ano: 2022
Banca:
FAURGS
Órgão:
SES-RS
Prova:
FAURGS - 2022 - SES-RS - Administrador de Banco de Dados - Edital nº 15 |
Q1889096
Banco de Dados
Qual é o predicado da Linguagem SQL que tem semântica
semelhante ao predicado unique, isto é, retorna verdadeiro se a subconsulta não contém linhas duplicadas,
mas considera dois valores nulos como não diferentes?
Ano: 2022
Banca:
FAURGS
Órgão:
SES-RS
Prova:
FAURGS - 2022 - SES-RS - Administrador de Banco de Dados - Edital nº 15 |
Q1889095
Banco de Dados
A etapa que tem por objetivo transformar o modelo
conceitual em um modelo lógico que posteriormente
será utilizado para a implementação em um Sistema
Gerenciador de Bancos de Dados específico é denominado
de projeto
Ano: 2022
Banca:
FAURGS
Órgão:
SES-RS
Prova:
FAURGS - 2022 - SES-RS - Administrador de Banco de Dados - Edital nº 15 |
Q1889094
Banco de Dados
Considere as afirmações abaixo sobre backup em
Sistemas Gerenciadores de Bancos de Dados.
I - Os backups consistentes, também conhecidos como cold backups, são realizados com a base de dados desligada, isto é, não há transações ativas, garantindo assim que todas as transações previamente realizadas estejam consistentes.
II - Os backups inconsistentes, também conhecidos como hot backups, são realizados com a base de dados aberta e gerando transações, o que faz com que o sistema dependa dos arquivos de log para uma posterior recuperação.
III- Enquanto os backups físicos contêm dados e/ou definições de objetos, os backups lógicos contêm os arquivos dos bancos de dados como, por exemplo, arquivos de dados, arquivos de log ou arquivos de controle.
Quais estão corretas?
I - Os backups consistentes, também conhecidos como cold backups, são realizados com a base de dados desligada, isto é, não há transações ativas, garantindo assim que todas as transações previamente realizadas estejam consistentes.
II - Os backups inconsistentes, também conhecidos como hot backups, são realizados com a base de dados aberta e gerando transações, o que faz com que o sistema dependa dos arquivos de log para uma posterior recuperação.
III- Enquanto os backups físicos contêm dados e/ou definições de objetos, os backups lógicos contêm os arquivos dos bancos de dados como, por exemplo, arquivos de dados, arquivos de log ou arquivos de controle.
Quais estão corretas?
Ano: 2022
Banca:
FAURGS
Órgão:
SES-RS
Prova:
FAURGS - 2022 - SES-RS - Administrador de Banco de Dados - Edital nº 15 |
Q1889093
Banco de Dados
Qual é a afirmativa correta sobre recuperação de falhas
em bancos de dados?
Ano: 2022
Banca:
FAURGS
Órgão:
SES-RS
Prova:
FAURGS - 2022 - SES-RS - Administrador de Banco de Dados - Edital nº 15 |
Q1889092
Banco de Dados
Numere a segunda coluna de acordo com a primeira,
associando os termos dos 5Vs de Big Data às suas
respectivas definições.
(1) Armazenamento primário
(2) Armazenamento secundário ou on-line
(3) Armazenamento terciário ou off-line
( ) Memória Cache
( ) Disco Óptico
( ) Memória Principal
( ) Disco Magnético
( ) Memória Flash
( ) Fita Magnética
A sequência correta de preenchimento dos parênteses, de cima para baixo, é
(1) Armazenamento primário
(2) Armazenamento secundário ou on-line
(3) Armazenamento terciário ou off-line
( ) Memória Cache
( ) Disco Óptico
( ) Memória Principal
( ) Disco Magnético
( ) Memória Flash
( ) Fita Magnética
A sequência correta de preenchimento dos parênteses, de cima para baixo, é
Ano: 2022
Banca:
FAURGS
Órgão:
SES-RS
Prova:
FAURGS - 2022 - SES-RS - Administrador de Banco de Dados - Edital nº 15 |
Q1889091
Banco de Dados
Sobre os Sistemas de Bancos de Dados cliente, assinale
a alternativa correta.
Ano: 2022
Banca:
FAURGS
Órgão:
SES-RS
Prova:
FAURGS - 2022 - SES-RS - Administrador de Banco de Dados - Edital nº 15 |
Q1889090
Banco de Dados
Sobre Sistemas Gerenciadores de Bancos de Dados
(SGBD), é correto afirmar que
Ano: 2022
Banca:
FAURGS
Órgão:
SES-RS
Prova:
FAURGS - 2022 - SES-RS - Administrador de Banco de Dados - Edital nº 15 |
Q1889087
Banco de Dados
Considere as seguintes afirmações sobre o Dicionário
de Dados (DD) do Sistema de Gerência de Banco de
Dados Oracle (19c ou superior).
I - O DD contém informações sobre usuários, objetos de esquema e estruturas de armazenamento.
II - O DD é modificado toda vez que um comando DDL é executado com sucesso.
III- O Oracle fornece visões sobre porções de interesse do DD, prefixadas por DBA_ e USER_. As visões com prefixo DBA_ são voltadas ao administrador da base de dados e contêm todos os objetos da base. As visões com prefixo USER_ permitem a um usuário específico ver seus objetos e os objetos sobre os quais tem privilégios.
Quais estão corretas?
I - O DD contém informações sobre usuários, objetos de esquema e estruturas de armazenamento.
II - O DD é modificado toda vez que um comando DDL é executado com sucesso.
III- O Oracle fornece visões sobre porções de interesse do DD, prefixadas por DBA_ e USER_. As visões com prefixo DBA_ são voltadas ao administrador da base de dados e contêm todos os objetos da base. As visões com prefixo USER_ permitem a um usuário específico ver seus objetos e os objetos sobre os quais tem privilégios.
Quais estão corretas?
Ano: 2022
Banca:
FAURGS
Órgão:
SES-RS
Prova:
FAURGS - 2022 - SES-RS - Administrador de Banco de Dados - Edital nº 15 |
Q1889086
Banco de Dados
Assinale as seguintes afirmativas sobre Sistemas de
Gerência de Banco de Dados (SGBDs) com V (verdadeiro) ou F (falso).
( ) SGBDs relacionais como o MySQL ou PostgreSQL são voltados a informações estruturadas, e baseadas em esquemas predefinidos. Dão apoio à linguagem de consulta padronizada SQL, mas, sendo de código aberto, não garantem suporte ou manutenção.
( ) SGBDs como Mongo e CouchDB são apropriados para informações semiestruturadas e classificados como baseados em documentos. Para fazer consultas, o Mongo oferece uma linguagem de comandos própria, e no CouchDB são definidas visões com linguagem de scripting.
( ) SGBDs como Redis e Neo4J são classificados como par chave-valor e voltados a informações não estruturadas. Ambos são SGBDs in-memory e, portanto, adequados a aplicações que exigem excelente desempenho.
A sequência correta de preenchimento dos parênteses, de cima para baixo, é
( ) SGBDs relacionais como o MySQL ou PostgreSQL são voltados a informações estruturadas, e baseadas em esquemas predefinidos. Dão apoio à linguagem de consulta padronizada SQL, mas, sendo de código aberto, não garantem suporte ou manutenção.
( ) SGBDs como Mongo e CouchDB são apropriados para informações semiestruturadas e classificados como baseados em documentos. Para fazer consultas, o Mongo oferece uma linguagem de comandos própria, e no CouchDB são definidas visões com linguagem de scripting.
( ) SGBDs como Redis e Neo4J são classificados como par chave-valor e voltados a informações não estruturadas. Ambos são SGBDs in-memory e, portanto, adequados a aplicações que exigem excelente desempenho.
A sequência correta de preenchimento dos parênteses, de cima para baixo, é
Ano: 2022
Banca:
FAURGS
Órgão:
SES-RS
Prova:
FAURGS - 2022 - SES-RS - Administrador de Banco de Dados - Edital nº 15 |
Q1889085
Banco de Dados
Assinale as seguintes afirmativas sobre mecanismos de
bloqueio no Sistema de Gerência de Banco de Dados
Oracle (19c ou superior) com V (verdadeiro) ou F
(falso).
( ) Todo comando DML obtém automaticamente dois tipos de bloqueio: Row Lock (TX – Bloqueio em nível de tupla) e Table Lock (TM – Bloqueio em nível de tabela). Existem diferentes tipos de Table Lock, garantindo compartilhamentos mais ou menos restritivos com outras transações, tais como o Row Share (RS), que oferece o maior grau de concorrência para uma tabela, ou o Exclusive Table Lock (X), que proíbe outras transações de executar qualquer comando DML na tabela.
( ) DDL Lock protege a definição de um objeto do esquema (schema object) resultante de alguma operação DDL sobre o objeto, ou que referencia o objeto. Enquanto o Exclusive DDL Lock bloqueia todo o Dicionário de Dados, o Shared DDL Lock bloqueia apenas o objeto em questão.
( ) System Locks (Bloqueios em nível de sistema) protegem as estruturas internas da base de dados e memória. Esses mecanismos não são acessíveis ao usuário, que não tem controle sobre a ocorrência desse tipo de bloqueio e suas durações. Exemplos são Latches, Mutexes e Internal Locks.
A sequência correta de preenchimento dos parênteses, de cima para baixo, é
( ) Todo comando DML obtém automaticamente dois tipos de bloqueio: Row Lock (TX – Bloqueio em nível de tupla) e Table Lock (TM – Bloqueio em nível de tabela). Existem diferentes tipos de Table Lock, garantindo compartilhamentos mais ou menos restritivos com outras transações, tais como o Row Share (RS), que oferece o maior grau de concorrência para uma tabela, ou o Exclusive Table Lock (X), que proíbe outras transações de executar qualquer comando DML na tabela.
( ) DDL Lock protege a definição de um objeto do esquema (schema object) resultante de alguma operação DDL sobre o objeto, ou que referencia o objeto. Enquanto o Exclusive DDL Lock bloqueia todo o Dicionário de Dados, o Shared DDL Lock bloqueia apenas o objeto em questão.
( ) System Locks (Bloqueios em nível de sistema) protegem as estruturas internas da base de dados e memória. Esses mecanismos não são acessíveis ao usuário, que não tem controle sobre a ocorrência desse tipo de bloqueio e suas durações. Exemplos são Latches, Mutexes e Internal Locks.
A sequência correta de preenchimento dos parênteses, de cima para baixo, é
Ano: 2022
Banca:
FAURGS
Órgão:
SES-RS
Prova:
FAURGS - 2022 - SES-RS - Administrador de Banco de Dados - Edital nº 15 |
Q1889084
Banco de Dados
Suponha que o administrador de um banco de dados
relacional tenha criado os usuários MSILVA, JSOUZA,
LCRUZ e TASSIS com os privilégios default do sistema.
Considere a sequência de comandos SQL (padrão
SQL99 ou superior) executada na ordem especificada
abaixo pelos usuários MSILVA e JSOUZA. Os comandos
executam sem erro.
1 - MSILVA cria uma tabela de nome FUNCIONARIOS usando o comando CREATE TABLE.
2 - MSILVA emite o comando GRANT SELECT, INSERT, DELETE ON FUNCIONARIOS TO JSOUZA WITH GRANT OPTION;
3 - JSOUZA emite o comando GRANT SELECT, INSERT ON FUNCIONARIOS TO LCRUZ;
4 - MSILVA emite o comando REVOKE DELETE, INSERT ON FUNCIONARIOS FROM JSOUZA;
Considere cada situação abaixo, assinalando V (verdadeiro) se o usuário tem o privilégio de realizar o comando especificado, ou F (falso) se não tem esse privilégio.
( ) O usuário LCRUZ pode inserir uma tupla na tabela FUNCIONARIOS.
( ) O usuário JSOUZA pode remover uma tupla da tabela FUNCIONARIOS.
( ) O usuário JSOUZA pode conceder ao usuário TASSIS o privilégio de consultar a tabela FUNCIONARIOS.
A sequência correta de preenchimento dos parênteses, de cima para baixo, é
1 - MSILVA cria uma tabela de nome FUNCIONARIOS usando o comando CREATE TABLE.
2 - MSILVA emite o comando GRANT SELECT, INSERT, DELETE ON FUNCIONARIOS TO JSOUZA WITH GRANT OPTION;
3 - JSOUZA emite o comando GRANT SELECT, INSERT ON FUNCIONARIOS TO LCRUZ;
4 - MSILVA emite o comando REVOKE DELETE, INSERT ON FUNCIONARIOS FROM JSOUZA;
Considere cada situação abaixo, assinalando V (verdadeiro) se o usuário tem o privilégio de realizar o comando especificado, ou F (falso) se não tem esse privilégio.
( ) O usuário LCRUZ pode inserir uma tupla na tabela FUNCIONARIOS.
( ) O usuário JSOUZA pode remover uma tupla da tabela FUNCIONARIOS.
( ) O usuário JSOUZA pode conceder ao usuário TASSIS o privilégio de consultar a tabela FUNCIONARIOS.
A sequência correta de preenchimento dos parênteses, de cima para baixo, é
Ano: 2022
Banca:
FAURGS
Órgão:
SES-RS
Prova:
FAURGS - 2022 - SES-RS - Administrador de Banco de Dados - Edital nº 15 |
Q1889083
Banco de Dados
Assinale as seguintes afirmativas sobre visões em
bancos de dados relacionais com V (verdadeiro) ou F
(falso).
( ) O uso de visões é uma forma de aumentar a segurança da base de dados, pois impede o acesso direto aos dados de uma tabela, fornecendo somente os dados considerados relevantes para o usuário.
( ) As visões podem esconder do programador a complexidade das consultas quanto ao desempenho envolvido para acessar determinadas informações. Por essa razão, podem degradar o desempenho de algumas consultas se comparado ao uso das tabelas originais.
( ) O uso de visões propicia a modularização, na qual consultas críticas e frequentes podem ser escritas de forma mais simples e natural, acessando porções especificadas da base de dados, e dividindo em subconsultas menores e independentes.
A sequência correta de preenchimento dos parênteses, de cima para baixo, é
( ) O uso de visões é uma forma de aumentar a segurança da base de dados, pois impede o acesso direto aos dados de uma tabela, fornecendo somente os dados considerados relevantes para o usuário.
( ) As visões podem esconder do programador a complexidade das consultas quanto ao desempenho envolvido para acessar determinadas informações. Por essa razão, podem degradar o desempenho de algumas consultas se comparado ao uso das tabelas originais.
( ) O uso de visões propicia a modularização, na qual consultas críticas e frequentes podem ser escritas de forma mais simples e natural, acessando porções especificadas da base de dados, e dividindo em subconsultas menores e independentes.
A sequência correta de preenchimento dos parênteses, de cima para baixo, é
Ano: 2022
Banca:
FAURGS
Órgão:
SES-RS
Prova:
FAURGS - 2022 - SES-RS - Administrador de Banco de Dados - Edital nº 15 |
Q1889081
Banco de Dados
Considerando os tipos de índices disponíveis no Oracle
(19c ou superior), analise as sentenças abaixo.
I - Em um índice bitmap, cada chave está associada a um bitmap no qual cada bit corresponde a um possível identificador de tupla (rowid). É recomendado para colunas cujo número de valores distintos é pequeno comparado ao número de tuplas total e que não sofrem muitas modificações.
II - Um índice bitmap de junção (bitmap join index) cria um índice de bitmap na coluna de uma tabela que é frequentemente juntada com outra(s) tabela(s) na mesma coluna. Essa pré-junção economiza recursos (e.g. CPU, memória) quando da execução da junção.
III- Um índice reverso (key reverse index) é um tipo de B-Tree no qual os bytes da chave a ser indexada são fisicamente invertidos. É apropriado em situações que requerem a redução da contenção por blocos de índices.
Quais estão corretas?
I - Em um índice bitmap, cada chave está associada a um bitmap no qual cada bit corresponde a um possível identificador de tupla (rowid). É recomendado para colunas cujo número de valores distintos é pequeno comparado ao número de tuplas total e que não sofrem muitas modificações.
II - Um índice bitmap de junção (bitmap join index) cria um índice de bitmap na coluna de uma tabela que é frequentemente juntada com outra(s) tabela(s) na mesma coluna. Essa pré-junção economiza recursos (e.g. CPU, memória) quando da execução da junção.
III- Um índice reverso (key reverse index) é um tipo de B-Tree no qual os bytes da chave a ser indexada são fisicamente invertidos. É apropriado em situações que requerem a redução da contenção por blocos de índices.
Quais estão corretas?