Questões de Concurso Sobre banco de dados
Foram encontradas 15.979 questões
• Colunas sublinhadas compõem a chave primária. • Colunas que admitem o valor nulo são exibidas entre colchetes. • Chaves estrangeiras são representadas por meio da cláusula REF:<lista_de_colunas> REF
Nesse contexto, considere a Figura a seguir, que exibe um diagrama E-R.
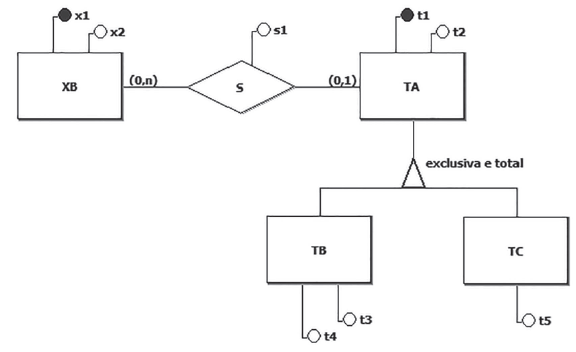
Qual esquema relacional preserva a semântica desse diagrama E-R, sem a necessidade de criação de regras de integridade adicionais?
Segundo as regras e as práticas da modelagem dimensional, e usando a granularidade mais baixa, que atributos devem constar da tabela fato?
Uma forma de garantir que os dados desse protótipo estejam sempre completamente atualizados em relação aos dados reais, com baixo impacto tanto na operação quanto no desempenho do sistema corporativo original, é
•o campo CNPJ é chave primária e contém 14 caracteres, sendo que os caracteres devem se ater aos numéricos [“0” a “9”], e o caractere zero “0” não pode ser ignorado, seja qual for a posição dele (início, meio ou fim da chave); •o campo NOME contém 20 caracteres e aceita valor nulo; •o campo PAIS contém 15 caracteres e não aceita valor nulo.
Nesse contexto, o comando SQL2008 que cria uma tabela com as características descritas acima é
O DBA atendeu adequadamente a esse pedido do programador por meio de uma restrição em SQL 2008 do tipo
SELECT * FROM T1 LEFT JOIN T2 USING (CHAVE);
Essa consulta resultou em 214 linhas.
Por motivos de segurança, ele fez outra consulta semelhante, apenas trocando o LEFT JOIN por um JOIN, e essa segunda consulta resultou em 190 linhas.
O que pode explicar corretamente a quantidade diferente de linhas nas consultas realizadas?
No que se refere a data warehouse, data mining e sistema de mensageria, julgue o próximo item.
Uma consulta de um sistema gerenciador de banco de dados
(SGBD) pode encontrar tendências úteis em um conjunto
de dados, ao passo que o data mining fornece operações
de análises mais abstratas, em alto nível, com o uso de
algoritmos especializados.
No que se refere a data warehouse, data mining e sistema de mensageria, julgue o próximo item.
Em empresas que possuem várias plataformas de hardware
e software e que carecem de padronização e integração
de dados, o data warehouse pode fornecer um modelo
de dados comum para suas diferentes áreas de interesse,
independentemente da fonte de dados.
Julgue o item que se segue, quanto aos conceitos de tuning e de segurança em banco de dados.
O comando REVOKE remove privilégios de acesso de usuário
à tabela do banco de dados.
Julgue o item que se segue, quanto aos conceitos de tuning e de segurança em banco de dados.
A criação de usuários em um sistema gerenciador de banco de
dados está associada a uma role, ou seja, cada usuário deve ser
associado a uma única role.
Julgue o item que se segue, quanto aos conceitos de tuning e de segurança em banco de dados.
O processo de otimização de consulta se caracteriza pela
escolha de uma estratégia mais eficiente para o processamento
de uma consulta SQL.
Julgue o item que se segue, quanto aos conceitos de tuning e de segurança em banco de dados.
Um índice denso possui o campo chave primária e, no segundo
campo, um ponteiro para o bloco de memória do disco.
Julgue o próximo item a respeito da administração e do gerenciamento de banco de dados.
O esquema de banco de dados é o espaço destinado ao
armazenamento do banco de dados; fisicamente, os dados são
armazenados em datafiles, que alocam imediatamente o espaço
especificado na sua criação
Julgue o próximo item a respeito da administração e do gerenciamento de banco de dados.
Restrição de domínio é o conjunto de possíveis valores que um
atributo pode receber.
Julgue o próximo item a respeito da administração e do gerenciamento de banco de dados.
Uma tabela está na BCNF (boyce-codd normal form) quando
os seus campos apresentarem uma dependência funcional com
tabelas estrangeiras.
Julgue o próximo item a respeito da administração e do gerenciamento de banco de dados.
Trigger é uma instrução que o sistema gerenciador de banco
de dados executa automaticamente como resultado de um
evento sempre que houver uma tentativa de modificar os dados
de uma tabela que é protegida por ele.
Com relação à arquitetura e à estrutura de banco de dados, julgue o próximo item.
Em um sistema gerenciador de banco de dados, a chave
estrangeira se caracteriza por um atributo que existe para
substituir a chave primária na entidade estrangeira.
Com relação à arquitetura e à estrutura de banco de dados, julgue o próximo item.
Em banco de dados, uma superchave se caracteriza por um
conjunto de um ou mais atributos que permitem identificar uma
única entidade em um conjunto de entidades.
Com relação à arquitetura e à estrutura de banco de dados, julgue o próximo item.
No modelo de entidade-relacionamento, uma entidade é
representada por um conjunto de atributos, os quais são
propriedades descritivas possuídas por membro de um
conjunto de entidades.
Com relação à arquitetura e à estrutura de banco de dados, julgue o próximo item.
Em uma arquitetura em duas camadas, a aplicação é
particionada em um componente que reside no servidor de
dados e outro no servidor de desenvolvimento de código.