Questões de Concurso Público IBGE 2016 para Tecnologista - Estatística
Foram encontradas 42 questões
Seja X uma variável aleatória mista com função densidade de probabilidade dada por:
fx(x) = 1/x2 para 1< x ≤ 4 , P(X = 1 ) = 0,25, sendo igual azero caso contrário.
Então os valores de P ( X ≤ 2 ) e E (X2) , esperança matemática de X ao quadrado, são respectivamente iguais a:
A capacidade de um time de futebol de marcar gols em uma única partida é uma variável aleatória. A tabela a seguir apresenta a probabilidade de certo time marcar um número mínimo (Y) de gols em uma partida:
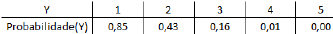
Isso significa que o número médio de gols marcados por esse
time em uma única partida de futebol é igual a:
Seja X uma variável aleatória contínua e Y= G(X) uma função de X tal que, no domínio da fx(x), densidade da X, as derivadas de 1ª e de 2ª ordem da G(X) são estritamente negativas. Considerando,
fy(y)= função densidade de probabilidade de Y;
fx-1(x) = função inversa da densidade de X;
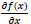 = derivada de f(x) com respeito à x;
= derivada de f(x) com respeito à x;
E(X) = esperança matemática de X;
h[f(X)] = função composta de f com h.
Então é correto afirmar que:
Suponha que uma amostra de tamanho n = 5 é extraída de umapopulação Normal, com média desconhecida, obtendo asseguintes observações:
X1 = 3, X2 = 5, X3 = 6, X4 = 9 e X5 = 12
São dados ainda os seguintes valores, retirados da tabela da distribuição Qui-Quadrado:
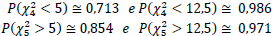
Se a população tem variância verdadeira σ2 = 4 em nova amostra (n=5), a probabilidade de se observar uma variância amostral maior do que a anterior é de:
A distribuição das alturas dos indivíduos de uma população é aproximadamente Normal, com média 1,70 m e variância 0,01. Adicionalmente, não havendo, na população, pessoas com alturas inferiores a 1,50 m nem superiores a 1,90 m, essa distribuição é truncada nos extremos.
São fornecidas também as seguintes informações:
ɸ (1)≅ 0,84 e ɸ (2) ≅ 0,98
ɸ (z) = função distribuição acumulada da Normal Padrão
Então a probabilidade de que um indivíduo da população,
sorteado ao acaso, tenha altura entre 1,60 m e 1,80 m é:
Para estimar, por máxima verossimilhança (MV) ou pelo método dos momentos (MM), o único parâmetro de dada distribuição de probabilidades, seleciona-se uma amostra de tamanho n.
A função densidade da distribuição é:
fx(x) = θxθ-1 , para 0 < x < 1 e zero caso contrário.Além disso, considere:
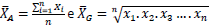
Então, os estimadores de MV e de MM (com base na média da distribuição) para θ são, respectivamente:
Considere os estimadores a seguir, tendo em vista a média populacional μ , a partir de uma amostra de tamanho n.
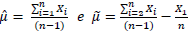
Se a variância populacional é finita, sobre as propriedades de 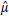 e
e 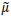 correto afirmar que:
correto afirmar que:
Com o objetivo de estimar, por intervalo, a verdadeira média populacional de uma distribuição, é extraída uma amostra aleatória de tamanho n = 26. Sendo a variância desconhecida, calcula-se o valor de 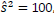 além da média amostral X = 8 de grau de confiança pretendido é de 95%. Somam-se a todas essas informações os valores tabulados:
além da média amostral X = 8 de grau de confiança pretendido é de 95%. Somam-se a todas essas informações os valores tabulados:
Φ(1,65) ≅ 0,95 Φ(1,96) ≅ 0,975 T25(1,71) ≅ 0,95
T26(1,70) ≅ 0,95 T25(2,06) ≅ 0,975 T26(2,05) ≅ 0,975
Onde, 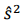 = estimador não-viesado da variância populacional;
= estimador não-viesado da variância populacional;
Φ(z) = fç distribuição acumulada da Normal-padrão;
Tn(t)= fç distribuição acumulada da T-Student com n graus de liberdade.
Então os limites do intervalo de confiança desejado são:
Um teste de hipótese será feito com base numa distribuição normal, com média desconhecida e variância σ2 =64 Uma amostra de tamanho n = 16 é extraída e sua média calculada,sendo X = 7 O conjunto de hipóteses a ser testado é:
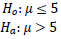
Considere ainda que a região crítica do teste é RC = (9 ,+ ∞) que, caso Ho seja falsa, o μ verdadeiro seria igual a 8.Além disso, são fornecidos os seguintes dados sobre a função distribuição acumulada da normal-padrão.
Φ(0,5) ≅ 0,69 Φ(1) ≅ 0,84 Φ(1,5) ≅ 0,93 Φ(2) ≅ 0,98
Logo, as probabilidades dos erros do Tipo I, do Tipo II e do p-valor (bilateral) do teste são, respectivamente, iguais a:
Os principais métodos para a estimação de parâmetros em modelos de regressão linear são os de Mínimos Quadrados Ordinários (MQO), o do Melhor Estimador Linear Não Tendencioso (BLUE) e o de Máxima Verossimilhança (MV).
Sobre esses métodos, é correto afirmar que:
Um econometrista resolve propor e estimar um modelo de regressão linear simples como forma de estimar o efeito da temperatura sobre o volume de venda de sorvetes. Emprega,para esse fim, a formulação:
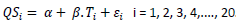
Onde QS é a quantidade de sorvetes (em milhares), T é a temperatura (célsius) e é ε o termo de erro do modelo.
Apenas estatísticas descritivas básicas sobre QS e T são dadas, como 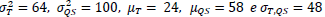 Onde, variâncias (σ2), médias (μ) e covariância (σT,Q,S).
Onde, variâncias (σ2), médias (μ) e covariância (σT,Q,S).
Supondo-se válidos todos os pressupostos clássicos, a partir das
informações disponíveis, verifica-se que:
Após estimar um modelo de regressão linear múltipla, por MQO, um econometrista repara que, por algum motivo, a tabela contendo os resultados da análise da variância ficou incompleta, conforme abaixo:

Apesar dos valores acima omitidos, é correto afirmar que:
Um modelo de regressão linear múltipla é estimado por MQO (Mínimos Quadrados Ordinários), conforme a equação:
Yi = α + β.Xi + γ.Wi + εi
As estimativas estão colocadas na tabela abaixo, com algumas
omissões:
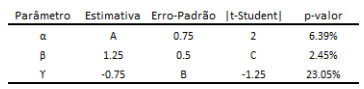
Com base nas estatísticas disponíveis e no cálculo dos valores
omitidos, é correto afirmar que:
Para modelar o comportamento de determinada proporção é proposto um modelo de regressão com variável dependente do tipo qualitativa. A forma funcional apresentada é:
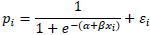
Sobre esse tipo de modelo e formulação, é correto afirmar que: