Questões de Concurso Público Prefeitura de Vitória - ES 2024 para Analista em Gestão Pública - Estatístico
Foram encontradas 60 questões
Ano: 2024
Banca:
FGV
Órgão:
Prefeitura de Vitória - ES
Prova:
FGV - 2024 - Prefeitura de Vitória - ES - Analista em Gestão Pública - Estatístico |
Q3052440
Estatística
Texto associado
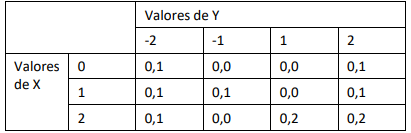
Use os dados a seguir para responder à próxima questão.
Duas variáveis aleatórias discretas X e Y têm a seguinte função de
probabilidade conjunta
Assim, por exemplo, P[ X = 0; Y = 2] = 0,1.
A covariância entre X e Y é igual a
Ano: 2024
Banca:
FGV
Órgão:
Prefeitura de Vitória - ES
Prova:
FGV - 2024 - Prefeitura de Vitória - ES - Analista em Gestão Pública - Estatístico |
Q3052441
Estatística
Numa população, 10% das pessoas sofrem de uma certa doença
W.
Se uma amostra aleatória simples de tamanho 4 dessa população for observada, a probabilidade de que duas ou mais sofram da doença W é aproximadamente igual a
Se uma amostra aleatória simples de tamanho 4 dessa população for observada, a probabilidade de que duas ou mais sofram da doença W é aproximadamente igual a
Ano: 2024
Banca:
FGV
Órgão:
Prefeitura de Vitória - ES
Prova:
FGV - 2024 - Prefeitura de Vitória - ES - Analista em Gestão Pública - Estatístico |
Q3052442
Estatística
Considere uma variável aleatória contínua X com função de
densidade de probabilidade dada por
f(x) = Kx2, se 0 < x < 3,
f(x) = 0, nos demais casos,
sendo k constante.
A média de X é igual a
f(x) = Kx2, se 0 < x < 3,
f(x) = 0, nos demais casos,
sendo k constante.
A média de X é igual a
Ano: 2024
Banca:
FGV
Órgão:
Prefeitura de Vitória - ES
Prova:
FGV - 2024 - Prefeitura de Vitória - ES - Analista em Gestão Pública - Estatístico |
Q3052443
Estatística
Se Z1, Z2, ... Zn são n variáveis aleatórias independentes e
identicamente distribuídas N(0, 1), então a variável 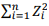 tem
distribuição
tem
distribuição
tem
distribuição
Ano: 2024
Banca:
FGV
Órgão:
Prefeitura de Vitória - ES
Prova:
FGV - 2024 - Prefeitura de Vitória - ES - Analista em Gestão Pública - Estatístico |
Q3052444
Estatística
Uma amostra aleatória simples x1, x2,..., x25, de tamanho 25 foi
obtida de uma variável populacional normalmente distribuída com
média μ desconhecida e variância σ2 = 100. A média amostral
obtida foi 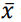 = 60.
= 60.
Lembre-se de que, se Z tem distribuição normal padrão, então P [ Z < 1.96 ] = 0,975.
Um intervalo de 95% de confiança μ será então dado por
= 60. Lembre-se de que, se Z tem distribuição normal padrão, então P [ Z < 1.96 ] = 0,975.
Um intervalo de 95% de confiança μ será então dado por
Ano: 2024
Banca:
FGV
Órgão:
Prefeitura de Vitória - ES
Prova:
FGV - 2024 - Prefeitura de Vitória - ES - Analista em Gestão Pública - Estatístico |
Q3052445
Estatística
Uma amostra aleatória simples de tamanho 100 foi obtida para
estimar uma proporção p populacional de indivíduos que
apresentam uma característica A. Como resultado, 36 indivíduos
amostrais apresentaram a característica A.
Lembre-se que de, se Z tem distribuição normal padrão, então P [ Z < 1.96 ] = 0,975. Usando a estimativa de p no lugar do valor desconhecido, um intervalo de 95% de confiança para p será dado aproximadamente por
Lembre-se que de, se Z tem distribuição normal padrão, então P [ Z < 1.96 ] = 0,975. Usando a estimativa de p no lugar do valor desconhecido, um intervalo de 95% de confiança para p será dado aproximadamente por
Ano: 2024
Banca:
FGV
Órgão:
Prefeitura de Vitória - ES
Prova:
FGV - 2024 - Prefeitura de Vitória - ES - Analista em Gestão Pública - Estatístico |
Q3052446
Estatística
Uma amostra aleatória simples X1, X2,..., Xn será obtida de uma
densidade dada por f(x) = θe-θx, se x > 0, θ > 0, f(x) = 0, nos demais
casos.
O estimador de máxima verossimilhança de θ é dado por
O estimador de máxima verossimilhança de θ é dado por
Ano: 2024
Banca:
FGV
Órgão:
Prefeitura de Vitória - ES
Prova:
FGV - 2024 - Prefeitura de Vitória - ES - Analista em Gestão Pública - Estatístico |
Q3052447
Estatística
O tamanho da amostra aleatória simples necessário para que
possamos garantir, com 99% de confiança, que o valor da média
amostral não se afaste do valor da média populacional por mais de
5% do valor do desvio padrão populacional será, no mínimo,
aproximadamente igual a
[Lembre-se de que, se Z tem distribuição normal padrão, então P [ Z < 2,58 ] = 0,995]
[Lembre-se de que, se Z tem distribuição normal padrão, então P [ Z < 2,58 ] = 0,995]
Ano: 2024
Banca:
FGV
Órgão:
Prefeitura de Vitória - ES
Prova:
FGV - 2024 - Prefeitura de Vitória - ES - Analista em Gestão Pública - Estatístico |
Q3052448
Estatística
Para testar a hipótese nula de que uma proporção populacional p
de sucessos é menor ou igual a 0,5 contra a hipótese alternativa
de que p é maior do que 0,5, uma amostra aleatória simples de
tamanho 100 será observada e o critério que rejeita a hipótese
nula se a proporção de sucessos amostral for maior do que 0,64
será usado.
A probabilidade de erro tipo I máxima com esse critério é aproximadamente igual a
A probabilidade de erro tipo I máxima com esse critério é aproximadamente igual a
Ano: 2024
Banca:
FGV
Órgão:
Prefeitura de Vitória - ES
Prova:
FGV - 2024 - Prefeitura de Vitória - ES - Analista em Gestão Pública - Estatístico |
Q3052449
Estatística
Para testar H0: μ ≤ 30 versus H1: μ > 30, em que μ é a média de
uma variável populacional suposta normalmente distribuída com
variância 64, uma amostra aleatória simples de tamanho 100 será
obtida.
Lembre-se de que, se Z tem distribuição normal padrão, P[ Z > 1,64 ] ≈ 0,05.
O teste uniformemente mais potente de tamanho α = 0,05 rejeitará H0 se o valor da média amostral observada for maior ou igual a
Lembre-se de que, se Z tem distribuição normal padrão, P[ Z > 1,64 ] ≈ 0,05.
O teste uniformemente mais potente de tamanho α = 0,05 rejeitará H0 se o valor da média amostral observada for maior ou igual a
Ano: 2024
Banca:
FGV
Órgão:
Prefeitura de Vitória - ES
Prova:
FGV - 2024 - Prefeitura de Vitória - ES - Analista em Gestão Pública - Estatístico |
Q3052450
Estatística
Avalie se as afirmativas a seguir, acerca das características de um
bom estimador são falsas (F) ou verdadeiras (V).
( ) Um bom estimador de um parâmetro θ deve ser não tendencioso para θ.
( ) Um bom estimador de um parâmetro θ deve ter a maior variância possível.
( ) Um bom estimador de um parâmetro θ deve ter erro médio quadrático máximo.
As afirmativas são, respectivamente,
( ) Um bom estimador de um parâmetro θ deve ser não tendencioso para θ.
( ) Um bom estimador de um parâmetro θ deve ter a maior variância possível.
( ) Um bom estimador de um parâmetro θ deve ter erro médio quadrático máximo.
As afirmativas são, respectivamente,
Ano: 2024
Banca:
FGV
Órgão:
Prefeitura de Vitória - ES
Prova:
FGV - 2024 - Prefeitura de Vitória - ES - Analista em Gestão Pública - Estatístico |
Q3052451
Estatística
Para testar a hipótese nula H0 de igualdade entre 5 médias
populacionais a seguinte tabela ANOVA foi obtida (alguns dados
estão omitidos). Há um total de 100 observações.
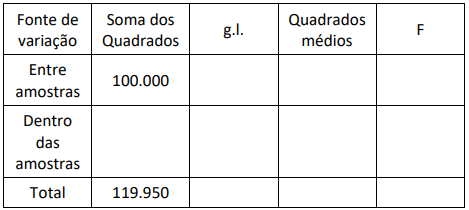
Sob a hipótese nula, o valor da estatística F é então aproximadamente igual a
Sob a hipótese nula, o valor da estatística F é então aproximadamente igual a
Ano: 2024
Banca:
FGV
Órgão:
Prefeitura de Vitória - ES
Prova:
FGV - 2024 - Prefeitura de Vitória - ES - Analista em Gestão Pública - Estatístico |
Q3052452
Estatística
Para testar a hipótese nula de igualdade entre duas médias
populacionais de variáveis aleatórias X e Y normalmente
distribuídas com variâncias supostas iguais e desconhecidas, duas
amostras independentes foram observadas, uma para a variável X,
outra para a variável Y.
Os dados obtidos estão resumidos na tabela a seguir.

O valor da estatística T usual, nesse caso, é aproximadamente igual a
Os dados obtidos estão resumidos na tabela a seguir.
O valor da estatística T usual, nesse caso, é aproximadamente igual a
Ano: 2024
Banca:
FGV
Órgão:
Prefeitura de Vitória - ES
Prova:
FGV - 2024 - Prefeitura de Vitória - ES - Analista em Gestão Pública - Estatístico |
Q3052453
Estatística
No cálculo do índice de preços de Laspeyres, se n é o número de
itens, pt,i é o preço de um item qualquer no período "atual", p0,i é
o preço de um item qualquer no período base, qt,i é a quantidade
de um item qualquer no período atual, e q0,i é a quantidade de um
item qualquer no período base, então o referido índice será dado
pela fórmula
Ano: 2024
Banca:
FGV
Órgão:
Prefeitura de Vitória - ES
Prova:
FGV - 2024 - Prefeitura de Vitória - ES - Analista em Gestão Pública - Estatístico |
Q3052454
Programação
Os formatos de dados XML, JSON e CSV são amplamente usados
para armazenamento e troca de informações, cada um com
características distintas.
Assinale a opção que descreve corretamente uma diferença entre os padrões XML, JSON e CSV.
Assinale a opção que descreve corretamente uma diferença entre os padrões XML, JSON e CSV.
Ano: 2024
Banca:
FGV
Órgão:
Prefeitura de Vitória - ES
Prova:
FGV - 2024 - Prefeitura de Vitória - ES - Analista em Gestão Pública - Estatístico |
Q3052455
Banco de Dados
O processo de ETL (Extract, Transform, and Load) é importante na
integração de dados, especialmente em projetos de data
warehousing e business intelligence. Ele envolve três etapas
principais, que são fundamentais para garantir a integridade e a
qualidade dos dados permitindo análises precisas e insights
valiosos.
No processo ETL, a etapa de transformação
No processo ETL, a etapa de transformação
Ano: 2024
Banca:
FGV
Órgão:
Prefeitura de Vitória - ES
Prova:
FGV - 2024 - Prefeitura de Vitória - ES - Analista em Gestão Pública - Estatístico |
Q3052456
Engenharia de Software
No aprendizado de máquina, técnicas de classificação e
agrupamento têm objetivos distintos.
Assinale a opção que descreve corretamente uma diferença fundamental entre técnicas de agrupamento e técnicas de classificação.
Assinale a opção que descreve corretamente uma diferença fundamental entre técnicas de agrupamento e técnicas de classificação.
Ano: 2024
Banca:
FGV
Órgão:
Prefeitura de Vitória - ES
Prova:
FGV - 2024 - Prefeitura de Vitória - ES - Analista em Gestão Pública - Estatístico |
Q3052457
Estatística
Os classificadores Naive Bayes são amplamente utilizados em
aprendizado de máquina devido à sua simplicidade e eficácia.
Assim, é correto afirmar que os classificadores Naive Bayes
Assim, é correto afirmar que os classificadores Naive Bayes
Ano: 2024
Banca:
FGV
Órgão:
Prefeitura de Vitória - ES
Prova:
FGV - 2024 - Prefeitura de Vitória - ES - Analista em Gestão Pública - Estatístico |
Q3052458
Engenharia de Software
No processamento de linguagem natural (PLN), a redução de
dimensionalidade é vital para simplificar dados textuais e melhorar
o desempenho dos algoritmos de aprendizado de máquina.
Diversos métodos são usados para esse fim, cada um com suas
próprias características.
Na redução de dimensionalidade em PLN, a técnica utilizada é chamada
Na redução de dimensionalidade em PLN, a técnica utilizada é chamada
Ano: 2024
Banca:
FGV
Órgão:
Prefeitura de Vitória - ES
Prova:
FGV - 2024 - Prefeitura de Vitória - ES - Analista em Gestão Pública - Estatístico |
Q3052459
Engenharia de Software
A otimização de hiperparâmetros é crucial na construção de
modelos de Machine Learning, pois pode afetar significativamente
o desempenho do modelo. Diversas técnicas de busca são usadas
para encontrar a melhor combinação de hiperparâmetros, e
entender quais são eficazes para esse propósito é essencial para
aprimorar a precisão do modelo.
A técnica apropriada na otimização de hiperparâmetros para um modelo de aprendizado supervisionado, considerando tanto a eficiência quanto a eficácia é a
A técnica apropriada na otimização de hiperparâmetros para um modelo de aprendizado supervisionado, considerando tanto a eficiência quanto a eficácia é a