Questões de Concurso Público DATAPREV 2012 para Analista de Tecnologia da Informação - Análise de Informações
Foram encontradas 17 questões
Ano: 2012
Banca:
Quadrix
Órgão:
DATAPREV
Prova:
Quadrix - 2012 - DATAPREV - Analista de Tecnologia da Informação - Análise de Informações |
Q443945
Estatística
Utilize as informações dadas a seguir, se necessário, para resolver as questões de conhecimentos específicos.
Nível de Valores críticos de z Valores críticos de z
significância para testes unilaterais para testes bilaterais 0,10 -1,28 ou 1,28 - 1,645 e 1,645 0,05 - 1,64 ou 1,645 -1,96 e 1,96 0,01 - 2,33 ou 2,33 - 2,58 e 2,58 0,005 - 2,58 ou 2,58 - 2,81 e 2,81 0,002 - 2,88 ou 2,88 - 3,08 e 3,08
1. √3 = 1,733333.. .. 2. A área subentendida pela curva normal à direita de z = 1,92 é 0,4726 3. A área subentendida pela curva normal à direita de z = 1,25 é 0,1056 4. x 2(0,99) = 11,3 5. x 2(0,95) = 7,81
Considere o vetor Xn = (X1, X2, ..., Xn ) tal que: logX1 + logx2 + logx3 + ....+ logxn = (n + 1) -1 .
Para cada n ∈ N dado, Xn tem uma média geométrica (Xn)g.
Qual o valor de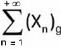
Nível de Valores críticos de z Valores críticos de z
significância para testes unilaterais para testes bilaterais 0,10 -1,28 ou 1,28 - 1,645 e 1,645 0,05 - 1,64 ou 1,645 -1,96 e 1,96 0,01 - 2,33 ou 2,33 - 2,58 e 2,58 0,005 - 2,58 ou 2,58 - 2,81 e 2,81 0,002 - 2,88 ou 2,88 - 3,08 e 3,08
1. √3 = 1,733333.. .. 2. A área subentendida pela curva normal à direita de z = 1,92 é 0,4726 3. A área subentendida pela curva normal à direita de z = 1,25 é 0,1056 4. x 2(0,99) = 11,3 5. x 2(0,95) = 7,81
Considere o vetor Xn = (X1, X2, ..., Xn ) tal que: logX1 + logx2 + logx3 + ....+ logxn = (n + 1) -1 .
Para cada n ∈ N dado, Xn tem uma média geométrica (Xn)g.
Qual o valor de
Ano: 2012
Banca:
Quadrix
Órgão:
DATAPREV
Prova:
Quadrix - 2012 - DATAPREV - Analista de Tecnologia da Informação - Análise de Informações |
Q443946
Estatística
O boxplot é um gráfico construído com base no resumo dos cinco números, constituído por:
Ano: 2012
Banca:
Quadrix
Órgão:
DATAPREV
Prova:
Quadrix - 2012 - DATAPREV - Analista de Tecnologia da Informação - Análise de Informações |
Q443947
Estatística
Os valores conjuntos das variáveis x e y foram plotados em um gráfico representado a seguir por um círculo tangente aos eixos coordenados, e cuja abscissa máxima é igual a 6 √2 , em unidade de medida conveniente.
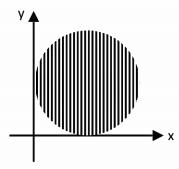
Em relação ao conjunto de dados indicado, a média quadrática simples de um par desse conjunto é um número que atinge valor máximo igual a:
Em relação ao conjunto de dados indicado, a média quadrática simples de um par desse conjunto é um número que atinge valor máximo igual a:
Ano: 2012
Banca:
Quadrix
Órgão:
DATAPREV
Prova:
Quadrix - 2012 - DATAPREV - Analista de Tecnologia da Informação - Análise de Informações |
Q443949
Estatística
Para uma seqüência { an }, considere a seqüência { An }, de medias aritméticas, ou seja, An = a1 + a2 + ... + an /n .
Se An tende a um valor A para n → + ∞, então A é igual a:
Se An tende a um valor A para n → + ∞, então A é igual a:
Ano: 2012
Banca:
Quadrix
Órgão:
DATAPREV
Prova:
Quadrix - 2012 - DATAPREV - Analista de Tecnologia da Informação - Análise de Informações |
Q443950
Estatística
Considere as afirmações a seguir.
I. Se duas amostras aleatórias de tamanhos N1 e N2 são extraídas de populações normais cujos desvios são σ1 = σ2 e se ambas têm médias X1 e X2 e desvios S1 e S2, respectivamente, então para testar a hipótese H0 de que as amostras proveem da mesma população, adota-se o escore t dado por:
t = ( X1 - X2 )/σ(1/N1 + 1/N2)0,5, em que
σ = [(N1S12 + N2 s22)/(N1 + N2 - 2)]0,5
II. Na distribuição de "Student", o número de graus de liberdade é igual a N1 + N2 - 2.
III.Na distribuição de qui-quadrado o valor máximo ocorre para X2 = v - 2, para v ≥ 2.
IV. O número de graus de liberdade de uma estatística, v, é definido como o número N de observações independentes da amostra menos o número k dos parâmetros populacionais que devem ser estimados por meio de observações amostrais.
V. Suponha um conjunto de N elementos, dos quais k apresenta uma certa característica. Se forem extraídos n elementos sem reposição do conjunto, temos uma distribuição hipergeométrica com probabilidade P[ X = x ]
dada por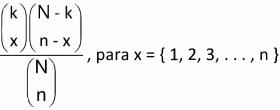
Dentre as afirmações feitas, quantas são falsas?
I. Se duas amostras aleatórias de tamanhos N1 e N2 são extraídas de populações normais cujos desvios são σ1 = σ2 e se ambas têm médias X1 e X2 e desvios S1 e S2, respectivamente, então para testar a hipótese H0 de que as amostras proveem da mesma população, adota-se o escore t dado por:
t = ( X1 - X2 )/σ(1/N1 + 1/N2)0,5, em que
σ = [(N1S12 + N2 s22)/(N1 + N2 - 2)]0,5
II. Na distribuição de "Student", o número de graus de liberdade é igual a N1 + N2 - 2.
III.Na distribuição de qui-quadrado o valor máximo ocorre para X2 = v - 2, para v ≥ 2.
IV. O número de graus de liberdade de uma estatística, v, é definido como o número N de observações independentes da amostra menos o número k dos parâmetros populacionais que devem ser estimados por meio de observações amostrais.
V. Suponha um conjunto de N elementos, dos quais k apresenta uma certa característica. Se forem extraídos n elementos sem reposição do conjunto, temos uma distribuição hipergeométrica com probabilidade P[ X = x ]
dada por
Dentre as afirmações feitas, quantas são falsas?
Ano: 2012
Banca:
Quadrix
Órgão:
DATAPREV
Prova:
Quadrix - 2012 - DATAPREV - Analista de Tecnologia da Informação - Análise de Informações |
Q443951
Estatística
Considere as seguintes afirmações:
I. A média amostrai e a variância amostrai corrigida são dois estimadores imparciais e eficientes.
II. A mediana e a estatística da amostra 0,5(Q1 + Q2), em que Q1 e Q2 são os quartis mais baixo e mais alto da amostra, respectivamente, são dois estimadores imparciais e ineficientes.
III. O desvio padrão da amostra e o corrigido são estimadores parciais e ineficientes.
IV. O desvio médio e a amplitude semi-interquartílica são estimadores parciais e ineficientes.
V. A moda e a mediana são estimadores imparciais e eficientes.
Dentre as afirmações dadas, quantas são verdadeiras?
I. A média amostrai e a variância amostrai corrigida são dois estimadores imparciais e eficientes.
II. A mediana e a estatística da amostra 0,5(Q1 + Q2), em que Q1 e Q2 são os quartis mais baixo e mais alto da amostra, respectivamente, são dois estimadores imparciais e ineficientes.
III. O desvio padrão da amostra e o corrigido são estimadores parciais e ineficientes.
IV. O desvio médio e a amplitude semi-interquartílica são estimadores parciais e ineficientes.
V. A moda e a mediana são estimadores imparciais e eficientes.
Dentre as afirmações dadas, quantas são verdadeiras?
Ano: 2012
Banca:
Quadrix
Órgão:
DATAPREV
Prova:
Quadrix - 2012 - DATAPREV - Analista de Tecnologia da Informação - Análise de Informações |
Q443952
Estatística
Uma amostra de 150 brocas de aço rápido da empresa SÓAÇO apresentou vida média de 1400 horas e desvio padrão de 120 horas. Outra amostra de 200 brocas do mesmo material, da empresa BROCAÇO, apresentou vida média de 1200 horas e desvio padrão de 80 horas. Para um limite de confiança de 95%, a diferença entre as vidas médias das brocas está contida no intervalo:
(Dados zc = 1,96 e √10 = 3,17)
(Dados zc = 1,96 e √10 = 3,17)
Ano: 2012
Banca:
Quadrix
Órgão:
DATAPREV
Prova:
Quadrix - 2012 - DATAPREV - Analista de Tecnologia da Informação - Análise de Informações |
Q443953
Estatística
Considere uma amostra de 100 amortecedores produzidos por uma empresa submetida a diversas cargas, sendo obtida uma carga média, antes de seus rompimentos, de 1570 kg, com desvio padrão de 120 kg.
Sendo μ a carga média de todos os amortecedores produzidos pela empresa, pretende-se testar a hipótese H0: μ = 1600 kg, face à hipótese alternativa H1: μ ≠ 1600.
Para as informações dadas, pode-se afirmar que:
Sendo μ a carga média de todos os amortecedores produzidos pela empresa, pretende-se testar a hipótese H0: μ = 1600 kg, face à hipótese alternativa H1: μ ≠ 1600.
Para as informações dadas, pode-se afirmar que:
Ano: 2012
Banca:
Quadrix
Órgão:
DATAPREV
Prova:
Quadrix - 2012 - DATAPREV - Analista de Tecnologia da Informação - Análise de Informações |
Q443955
Estatística
Uma variável aleatória X tem função de densidade dada por: f(x) = mx,para 0 < x < 4 e f(x) = 0, caso contrário o valor de m, a probabilidade P de X estar entre 2 e 4 e a função de distribuição da variável aleatória são dados por:
Ano: 2012
Banca:
Quadrix
Órgão:
DATAPREV
Prova:
Quadrix - 2012 - DATAPREV - Analista de Tecnologia da Informação - Análise de Informações |
Q443956
Estatística
A tabela a seguir indica os valores de pedágios cobrados em cada estrada que liga as cidades A, B, C e D.
De A para B De B para C De C para D R$ 4,50 R$ 5,00 R$ 5,00 R$ 6,00 R$ 2,00 R$ 7,00 R$ 6,50 R$ 7,00 --------------
Se dois automóveis partirem das cidades A e D para se encontrar na cidade B, escolhendo caminhos ao acaso, qual a probabilidade de que os motoristas paguem o mesmo valor de pedágio?
De A para B De B para C De C para D R$ 4,50 R$ 5,00 R$ 5,00 R$ 6,00 R$ 2,00 R$ 7,00 R$ 6,50 R$ 7,00 --------------
Se dois automóveis partirem das cidades A e D para se encontrar na cidade B, escolhendo caminhos ao acaso, qual a probabilidade de que os motoristas paguem o mesmo valor de pedágio?
Ano: 2012
Banca:
Quadrix
Órgão:
DATAPREV
Prova:
Quadrix - 2012 - DATAPREV - Analista de Tecnologia da Informação - Análise de Informações |
Q443958
Estatística
Um grande banco encomendou uma pesquisa sobre o tempo de atendimento em seus caixas e foi informado de que a duração, em minutos, de cada atendimento seguia uma distribuição exponencial com parâmetro α = 0,16. Sabendo que, se a duração de cada atendimento for maior que 20 minutos, o banco poderá ser multado por órgãos superiores, qual a probabilidade, aproximada, de que a multa seja aplicada? Dado: e -0,8 = 0,45
Ano: 2012
Banca:
Quadrix
Órgão:
DATAPREV
Prova:
Quadrix - 2012 - DATAPREV - Analista de Tecnologia da Informação - Análise de Informações |
Q443959
Estatística
Seja m > 0 e considerando uma variável aleatória X, com função de distribuição F, tal que:
F(x) = 1 - 1/xm, se x > 1 e
F(x) = 0 para os demais valores de x.
Sobre E(Xk) e E( |X |k) é correto afirmar que:
F(x) = 1 - 1/xm, se x > 1 e
F(x) = 0 para os demais valores de x.
Sobre E(Xk) e E( |X |k) é correto afirmar que:
Ano: 2012
Banca:
Quadrix
Órgão:
DATAPREV
Prova:
Quadrix - 2012 - DATAPREV - Analista de Tecnologia da Informação - Análise de Informações |
Q443960
Estatística
Um fabricante de cosméticos lançou um novo tipo de esmalte e verificou que as quantidades vendidas (n)
diariamente em cinco regiões (A, B, C, D e E) estavam relacionadas ao preço (p), segundo a tabela a seguir.
A B C D E
p R$5,00 R$5,25 R$5,50 R$6,00 R$6,25
n 920 860 820 730 700
Pretendendo determinar um preço final de venda, o fabricante espera obter lucro diário máximo, tendo em vista que as despesas diárias são de R$ 1200,00 e que o custo de fabricação de cada unidade é igual a R$ 1,50. Para tanto ele determinou uma equação linear de demanda utilizando a seguinte tabela:
Pi ni Pi2 Piui
5,00 920 25,00 4600
5,25 860 27,56 4515
5,50 820 30,25 4510
6,00 730 36,00 4380
6,25 700 39,06 4375
Qual deve ser o preço de venda, por unidade, para o lucro máximo? (Considere que: 188/1,07 - 176)
diariamente em cinco regiões (A, B, C, D e E) estavam relacionadas ao preço (p), segundo a tabela a seguir.
A B C D E
p R$5,00 R$5,25 R$5,50 R$6,00 R$6,25
n 920 860 820 730 700
Pretendendo determinar um preço final de venda, o fabricante espera obter lucro diário máximo, tendo em vista que as despesas diárias são de R$ 1200,00 e que o custo de fabricação de cada unidade é igual a R$ 1,50. Para tanto ele determinou uma equação linear de demanda utilizando a seguinte tabela:
Pi ni Pi2 Piui
5,00 920 25,00 4600
5,25 860 27,56 4515
5,50 820 30,25 4510
6,00 730 36,00 4380
6,25 700 39,06 4375
Qual deve ser o preço de venda, por unidade, para o lucro máximo? (Considere que: 188/1,07 - 176)
Ano: 2012
Banca:
Quadrix
Órgão:
DATAPREV
Prova:
Quadrix - 2012 - DATAPREV - Analista de Tecnologia da Informação - Análise de Informações |
Q443961
Estatística
Determine o coeficiente de correlação linear e avalie se a correlação é ou não é forte entre as variáveis X e Y, cujos valores são dados na tabela seguinte.
X 1 3 4 6 8 9 11 14 Y 1 2 4 4 5 7 8 9
Dados: √14 ≅ √33 ≅5,7
X 1 3 4 6 8 9 11 14 Y 1 2 4 4 5 7 8 9
Dados: √14 ≅ √33 ≅5,7
Ano: 2012
Banca:
Quadrix
Órgão:
DATAPREV
Prova:
Quadrix - 2012 - DATAPREV - Analista de Tecnologia da Informação - Análise de Informações |
Q443962
Estatística

A Prefeitura de uma cidade, visando à obtenção de menor custo de manutenção do seu sistema de iluminação pública, comprou lâmpadas cuja vida média é de 1.500 horas, e cujo desvio é de 150 horas. Para tanto instalou três lâmpadas em cada poste, de modo que, se uma delas queimar, outra começa a funcionar. Admitindo que as vidas médias são normalmente distribuídas, qual é a probabilidade de que não haja manutenção de um poste por pelo menos 5.000 horas?
Obs: se os três lâmpadas deixarem de funcionar, há manutenção.
Ano: 2012
Banca:
Quadrix
Órgão:
DATAPREV
Prova:
Quadrix - 2012 - DATAPREV - Analista de Tecnologia da Informação - Análise de Informações |
Q443963
Estatística

Um fornecedor de lâmpadas sabe que, em seu processo de produção, 2% das lâmpadas são descartadas por não terem funcionamento adequado. Em função disso, ele adota a estratégia de embutir no preço final de cada lâmpada um valor que corresponde à probabilidade, em unidades reduzidas, de que 3% ou mais de alguma lâmpada seja refugada para cada 400 produzidas. Que valor é esse, se o preço de venda de cada lâmpada é igual a R$ 60,00?
Ano: 2012
Banca:
Quadrix
Órgão:
DATAPREV
Prova:
Quadrix - 2012 - DATAPREV - Analista de Tecnologia da Informação - Análise de Informações |
Q443964
Estatística
A análise dos componentes principais é um método de se expressarem os dados multivariados. Ela permite que o pesquisador reoriente os dados para que algumas poucas primeiras dimensões expliquem tantas informações quanto possível. A análise de componentes principais é também útil na identificação e compreensão dos padrões de associação entre as variáveis. Considere as cinco afirmações seguintes, sobre a análise dos componentes principais:
I. O primeiro componente principal, Z1 é dado pela combinação linear das variáveis originais X = [ X1 X2, ..., Xp] com maior variância possível.
II. Todos os componentes principais subsequentes são escolhidos para que não sejam correlacionados a todos os componentes principais anteriores.
III. Em razão de a análise de componentes principais buscar maximizar a variância, ela pode ser altamente sensível às diferenças de escala entre variáveis. Assim, é uma boa ideia padronizar os dados e representá-los por Xs.
IV. A solução para o problema dos componentes principais é obtida realizando-se uma decomposição de autovalor da matriz de correlação. Cada autovetor, indicado por Ui, representa a direção de um desses eixos principais. O vetor u controla os pesos usados para formar a combinação linear de Xs, que resulta em zi= Xs.Ui.
VI. No caso mais geral, só faz sentido utilizar a análise dos componentes principais quando os dados não são independentes. Barlett fornece um teste de qui- quadrado para determinar a esfericidade dos dados, 2 representado por X 2 = - [ n - 1 + (2p + 6)/5]ln | R|, com 2 (p2 - p)/2 graus de liberdade, onde p é o número de variáveis, n é o tamanho da amostra, e R é a matriz de correlação.
Dentre as seis afirmações dadas, quantas são falsas?
I. O primeiro componente principal, Z1 é dado pela combinação linear das variáveis originais X = [ X1 X2, ..., Xp] com maior variância possível.
II. Todos os componentes principais subsequentes são escolhidos para que não sejam correlacionados a todos os componentes principais anteriores.
III. Em razão de a análise de componentes principais buscar maximizar a variância, ela pode ser altamente sensível às diferenças de escala entre variáveis. Assim, é uma boa ideia padronizar os dados e representá-los por Xs.
IV. A solução para o problema dos componentes principais é obtida realizando-se uma decomposição de autovalor da matriz de correlação. Cada autovetor, indicado por Ui, representa a direção de um desses eixos principais. O vetor u controla os pesos usados para formar a combinação linear de Xs, que resulta em zi= Xs.Ui.
VI. No caso mais geral, só faz sentido utilizar a análise dos componentes principais quando os dados não são independentes. Barlett fornece um teste de qui- quadrado para determinar a esfericidade dos dados, 2 representado por X 2 = - [ n - 1 + (2p + 6)/5]ln | R|, com 2 (p2 - p)/2 graus de liberdade, onde p é o número de variáveis, n é o tamanho da amostra, e R é a matriz de correlação.
Dentre as seis afirmações dadas, quantas são falsas?