Analise o script abaixofrom pandas import DataFrameimport ma...
from pandas import DataFrame import matplotlib.pyplot as plt from sklearn.cluster import KMeans Data = {'x': [36,35,23,28,34,32,30,23,36,34,66,55,56,44,51,56,52,51,64,48,4 9,50,36,34,43,46,40,42,52,47],
'y':
[76,52,52,79,60,73,73,58,70,76,52,33,41,45,52,37,36,59,60,51,2 6,21,15,13,21,10,30,28,10,17] }
df = DataFrame(Data,columns=['x','y']) m = KMeans(n_clusters=3).fit(df) d = m.cluster_centers_ plt.xlabel("X") plt.ylabel("Y") plt.scatter(df['x'], df['y'], c= m.labels_.astype(float), s=100, alpha=0.5) plt.scatter(d[:, 0], d[:, 1], c='red', s=250, marker='*') plt.grid() plt.show()
O resultado da execução é
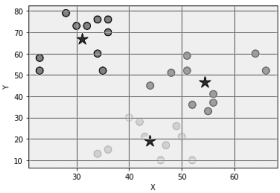
As estrelas indicam
Comentários
Veja os comentários dos nossos alunos
Os centroides são os pontos médios de cada cluster em um conjunto de dados agrupados. Em outras palavras, eles representam a posição média de todos os pontos de dados em um determinado cluster.
Eles são utilizados em algoritmos de agrupamento para determinar o centro de um cluster, ou seja, a localização mais próxima possível de todos os pontos do cluster.
No exemplo de código do enunciado, os centroides são armazenados no atributo cluster_centers_ do modelo KMeans treinado e são plotados como estrelas sobre o gráfico de dispersão dos dados.
Eles são calculados pelo algoritmo KMeans com base nas coordenadas x e y dos pontos de dados. O gráfico é exibido usando o método show.
Letra d
- Importações: Importa bibliotecas necessárias para manipulação de dados (pandas), criação de gráficos (matplotlib) e clustering (scikit-learn).
- Dados: Define os dados a serem utilizados em um dicionário.
- DataFrame: Cria um DataFrame a partir do dicionário de dados.
- K-Means: Aplica o algoritmo de K-Means para dividir os dados em 3 clusters.
- Centróides: Obtém os centróides dos clusters resultantes.
- Configuração do Gráfico: Define rótulos para os eixos x e y.
- Plotagem: Plota os pontos de dados, colorindo-os de acordo com seus clusters, e plota os centróides como estrelas vermelhas.
- Exibição: Adiciona uma grade ao gráfico e o exibe.
# Importa a biblioteca DataFrame do pandas
from pandas import DataFrame
# Importa a biblioteca pyplot do matplotlib para criação de gráficos
import matplotlib.pyplot as plt
# Importa a classe KMeans do scikit-learn para clustering
from sklearn.cluster import KMeans
# Define um dicionário com dados de exemplo
Data = {
'x': [36, 35, 23, 28, 34, 32, 30, 23, 36, 34, 66, 55, 56, 44, 51, 56, 52, 51, 64, 48, 49, 50, 36, 34, 43, 46, 40, 42, 52, 47],
'y': [76, 52, 52, 79, 60, 73, 73, 58, 70, 76, 52, 33, 41, 45, 52, 37, 36, 59, 60, 51, 26, 21, 15, 13, 21, 10, 30, 28, 10, 17]
}
# Cria um DataFrame a partir do dicionário de dados, com colunas 'x' e 'y'
df = DataFrame(Data, columns=['x', 'y'])
# Aplica o algoritmo de K-Means para agrupar os dados em 3 clusters
kmeans = KMeans(n_clusters=3).fit(df)
# Obtém os centróides dos clusters
centroides = kmeans.cluster_centers_
# Configura o gráfico para ter rótulo "X" no eixo x
plt.xlabel("X")
# Configura o gráfico para ter rótulo "Y" no eixo y
plt.ylabel("Y")
# Plota os pontos de dados, colorindo cada ponto com base no cluster ao qual pertence
plt.scatter(df['x'], df['y'], c=kmeans.labels_.astype(float), s=100, alpha=0.5)
# Plota os centróides dos clusters como estrelas vermelhas
plt.scatter(centroides[:, 0], centroides[:, 1], c='red', s=250, marker='*')
# Adiciona uma grade ao gráfico
plt.grid()
# Exibe o gráfico
plt.show()
Clique para visualizar este comentário
Visualize os comentários desta questão clicando no botão abaixo