Questões de Concurso
Foram encontradas 8.629 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2024
Banca:
IBFC
Órgão:
TRF - 5ª REGIÃO
Prova:
IBFC - 2024 - TRF - 5ª REGIÃO - Técnico Judiciário - Área de Apoio Especializado - Especialidade Desenvolvimento de Sistemas da Informação |
Q2386389
Engenharia de Software
Ao optar por utilizar a ferramenta de
versionamento Git, em um projeto de software,
deve-se criar um repositório Git em um diretório
local, desta forma, assinale a alternativa que
apresenta o comando Git que deve ser utilizado
para criar este novo repositório local.
Ano: 2024
Banca:
IBFC
Órgão:
TRF - 5ª REGIÃO
Prova:
IBFC - 2024 - TRF - 5ª REGIÃO - Técnico Judiciário - Área de Apoio Especializado - Especialidade Desenvolvimento de Sistemas da Informação |
Q2386388
Engenharia de Software
O versionamento de código é fundamental hoje
para o desenvolvimento de sistemas, ainda
mais quando estamos trabalhando em equipe,
desta forma, o Git se popularizou como uma das
ferramentas de versionamento mais utilizadas
no dia a dia dos desenvolvedores. Desta forma,
assinale a alternativa que apresenta o comando
Git utilizado para criar uma nova branch e
mudar para ela.
Ano: 2024
Banca:
IBFC
Órgão:
TRF - 5ª REGIÃO
Prova:
IBFC - 2024 - TRF - 5ª REGIÃO - Técnico Judiciário - Área de Apoio Especializado - Especialidade Desenvolvimento de Sistemas da Informação |
Q2386387
Engenharia de Software
Assinale a alternativa que preencha correta e
respectivamente as lacunas.
¹______ é a prática de integrar código frequentemente em um repositório compartilhado, enquanto ²______ é a extensão desse conceito, permitindo que as alterações de código sejam entregues automaticamente em ambientes de produção de forma contínua e confiável.
¹______ é a prática de integrar código frequentemente em um repositório compartilhado, enquanto ²______ é a extensão desse conceito, permitindo que as alterações de código sejam entregues automaticamente em ambientes de produção de forma contínua e confiável.
Ano: 2024
Banca:
IBFC
Órgão:
TRF - 5ª REGIÃO
Prova:
IBFC - 2024 - TRF - 5ª REGIÃO - Técnico Judiciário - Área de Apoio Especializado - Especialidade Desenvolvimento de Sistemas da Informação |
Q2386380
Engenharia de Software
Analise as afirmativas abaixo e dê valores
Verdadeiro (V) ou Falso (F).
( ) O teste de segurança é uma técnica que não avalia a resistência do software a ameaças e ataques, visando não identificar vulnerabilidades e garantir a proteção dos dados.
( ) Teste de Unidade é uma técnica que verifica obrigatoriamente em todos os componentes de um software para garantir que tudo funcione conforme esperado, dispensando completamente o teste de partes menores isoladas (unidades).
( ) O teste de aceitação do usuário (UAT) é conduzido exclusivamente pelos desenvolvedores para garantir que o sistema atenda aos padrões de qualidade internos da equipe de desenvolvimento.
Assinale a alternativa que apresenta a sequência correta de cima para baixo.
( ) O teste de segurança é uma técnica que não avalia a resistência do software a ameaças e ataques, visando não identificar vulnerabilidades e garantir a proteção dos dados.
( ) Teste de Unidade é uma técnica que verifica obrigatoriamente em todos os componentes de um software para garantir que tudo funcione conforme esperado, dispensando completamente o teste de partes menores isoladas (unidades).
( ) O teste de aceitação do usuário (UAT) é conduzido exclusivamente pelos desenvolvedores para garantir que o sistema atenda aos padrões de qualidade internos da equipe de desenvolvimento.
Assinale a alternativa que apresenta a sequência correta de cima para baixo.
Ano: 2024
Banca:
OBJETIVA
Órgão:
Prefeitura de Nova Roma do Sul - RS
Prova:
OBJETIVA - 2024 - Prefeitura de Nova Roma do Sul - RS - Assistente Social |
Q2385648
Engenharia de Software
As inteligências artificiais vêm conquistando cada vez mais o interesse do público, principalmente devido à ascensão de ferramentas como o ChatGPT. Em relação à inteligência artificial (IA) e ao ChatGPT, assinalar a alternativa CORRETA:
Ano: 2024
Banca:
IV - UFG
Órgão:
Prefeitura de Inhumas - GO
Prova:
CS-UFG - 2024 - Prefeitura de Inhumas - GO - Administrador de Rede e Segurança da Informação |
Q2383864
Engenharia de Software
O algoritmo de Machine Learning de classificação,
fundamentado em modelos de probabilidade que
incorporam suposições de independência forte, é conhecido
como
Ano: 2024
Banca:
CESPE / CEBRASPE
Órgão:
ITAIPU BINACIONAL
Prova:
CESPE / CEBRASPE - 2024 - ITAIPU BINACIONAL - Profissional de Nível Universitário Júnior - Função: Analista de Sistemas |
Q2383463
Engenharia de Software
Em qualidade de software, a dimensão responsável por garantir
que o produto gere valor para o usuário final é denominada
Ano: 2024
Banca:
CESPE / CEBRASPE
Órgão:
ITAIPU BINACIONAL
Prova:
CESPE / CEBRASPE - 2024 - ITAIPU BINACIONAL - Profissional de Nível Universitário Júnior - Função: Analista de Sistemas |
Q2383462
Engenharia de Software
Assinale a opção que apresenta o comando utilizado no Git para
versionar o projeto com um pacote de alterações.
Ano: 2024
Banca:
CESPE / CEBRASPE
Órgão:
ITAIPU BINACIONAL
Prova:
CESPE / CEBRASPE - 2024 - ITAIPU BINACIONAL - Profissional de Nível Universitário Júnior - Função: Analista de Sistemas |
Q2383456
Engenharia de Software
De acordo com o IFPUG (International Function Point Users
Group), assinale a opção que apresenta a sequência em que
ocorrem as etapas do método de medição de tamanho
funcional (FSM).
Ano: 2024
Banca:
CESPE / CEBRASPE
Órgão:
ITAIPU BINACIONAL
Prova:
CESPE / CEBRASPE - 2024 - ITAIPU BINACIONAL - Profissional de Nível Universitário Júnior - Função: Analista de Sistemas |
Q2383453
Engenharia de Software
No RUP, formular o escopo do projeto e planejar e preparar um
caso de negócios são atividades essenciais da
Ano: 2024
Banca:
CESPE / CEBRASPE
Órgão:
ITAIPU BINACIONAL
Prova:
CESPE / CEBRASPE - 2024 - ITAIPU BINACIONAL - Profissional de Nível Universitário Júnior - Função: Analista de Sistemas |
Q2383450
Engenharia de Software
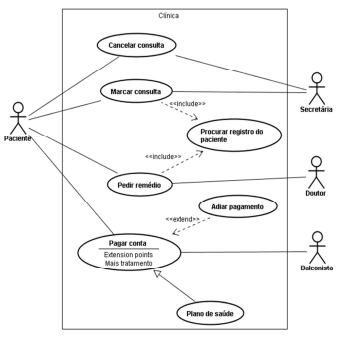
Com relação ao caso de uso acima, que está descrito em UML, assinale a opção correta.
Ano: 2024
Banca:
CESPE / CEBRASPE
Órgão:
ITAIPU BINACIONAL
Prova:
CESPE / CEBRASPE - 2024 - ITAIPU BINACIONAL - Profissional de Nível Universitário Júnior - Função: Engenheiro Eletricista |
Q2383395
Engenharia de Software
Assinale a opção que apresenta os três pilares do Scrum que
apoiam o conceito de trabalhar iterativamente.
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383287
Engenharia de Software
No aprendizado não supervisionado, os dados de treinamento não têm rótulos. O objetivo é agrupar instâncias
semelhantes em clusters. Nesse contexto, suponha que
se deseja executar um algoritmo de agrupamento para
tentar detectar grupos de visitantes semelhantes em um
blog. Em nenhum momento é informado ao algoritmo a
que grupo um visitante pertence, mas ele encontra essas conexões sem ajuda. Por exemplo, o algoritmo pode
notar que 40% dos visitantes são homens que adoram
histórias em quadrinhos e, geralmente, leem o blog à noite, enquanto 20% são jovens amantes de ficção científica
que visitam o blog durante os fins de semana, e assim
por diante. Deseja-se, nesse caso, usar um algoritmo de
agrupamento hierárquico para subdividir cada grupo em
grupos menores, o que pode ajudar a direcionar as postagens do blog para cada grupo específico.
Nesse cenário, qual é o algoritmo mais apropriado para fazer o agrupamento desejado?
Nesse cenário, qual é o algoritmo mais apropriado para fazer o agrupamento desejado?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383285
Engenharia de Software
As árvores de decisão são um modelo de aprendizado de máquina que opera por meio da construção de uma estrutura
em forma de árvore para tomar decisões e que oferece uma compreensão clara da lógica de decisão e da hierarquia de
características que contribuem para as predições finais. Elas são versáteis e podem ser usadas tanto para tarefas de
classificação quanto para as de regressão.
Nesse contexto, considere a construção de uma árvore de regressão usando a classe DecisionTreeRegressor do ScikitLearn e seu treinamento em um conjunto de dados quadrático com max_depth=2, conforme mostrado a seguir:
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor(max_depth=2)
tree_reg.fit(X, y)
A árvore resultante é representada na Figura a seguir.
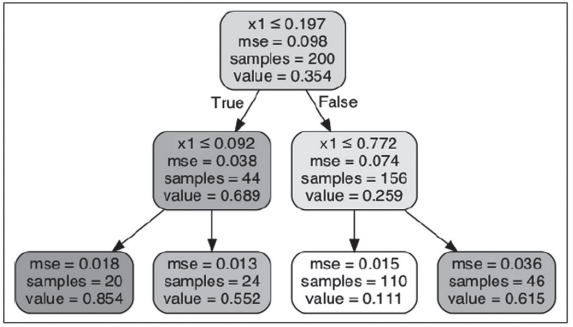
GÉRON, A. Hands-on machine learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniquesto Build Intelligent Systems. 2 ed. Sebastopol, CA: O’Reilly Media, Inc.: 2019, p. 183.
Considerando-se o cenário apresentado e que se deseja fazer uma predição para uma nova instância, com x1 = 0.6, qual será o valor predito?
Nesse contexto, considere a construção de uma árvore de regressão usando a classe DecisionTreeRegressor do ScikitLearn e seu treinamento em um conjunto de dados quadrático com max_depth=2, conforme mostrado a seguir:
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor(max_depth=2)
tree_reg.fit(X, y)
A árvore resultante é representada na Figura a seguir.
GÉRON, A. Hands-on machine learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniquesto Build Intelligent Systems. 2 ed. Sebastopol, CA: O’Reilly Media, Inc.: 2019, p. 183.
Considerando-se o cenário apresentado e que se deseja fazer uma predição para uma nova instância, com x1 = 0.6, qual será o valor predito?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383283
Engenharia de Software
Em uma nota técnica do Ipea sobre emprego público nos
governos subnacionais brasileiros, no ano de 2016, aparece menção sobre o fato de as bases utilizadas possuirem outliers, ou valores atípicos.
A construção de um modelo preditivo a partir dos dados dessas bases, usando árvores aleatórias, Random Forests,
A construção de um modelo preditivo a partir dos dados dessas bases, usando árvores aleatórias, Random Forests,
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383281
Engenharia de Software
Um cientista de dados está utilizando máquinas de vetor
de suporte (SVM) em um projeto de classificação, pois
deseja evitar o overfitting do modelo aos dados de treinamento.
Qual das seguintes técnicas auxilia a prevenir o overfitting em SVM?
Qual das seguintes técnicas auxilia a prevenir o overfitting em SVM?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383280
Engenharia de Software
Em um projeto de classificação de textos, um modelo de
machine learning foi aplicado em um conjunto de teste
e apresentou os seguintes resultados: uma precisão de
80% e uma revocação de 70%.
Com base nessas informações e considerando-se apenas a parte inteira da porcentagem, qual é o F1 Score desse modelo?
Com base nessas informações e considerando-se apenas a parte inteira da porcentagem, qual é o F1 Score desse modelo?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383279
Engenharia de Software
Um pesquisador possui um conjunto de dados consistindo
em características diversas, features, e suas respectivas
classificações, labels. Ele deseja dividir esse conjunto de
dados em conjuntos distintos, para treinamento e para
teste, com o objetivo de validar a eficácia de um modelo
de aprendizado de máquina.
Nesse contexto, qual função do SciKit-learn ele deve utilizar para realizar essa divisão de maneira eficiente e adequada?
Nesse contexto, qual função do SciKit-learn ele deve utilizar para realizar essa divisão de maneira eficiente e adequada?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383278
Engenharia de Software
Uma cientista de dados percebeu que, ao processar alguns documentos, seria melhor remover palavras que
aparecem em quase todo texto, as stop-words.
Para começar sua lista de stop-words, ela pode escolher listar todos os
Para começar sua lista de stop-words, ela pode escolher listar todos os
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383277
Engenharia de Software
O método de POS-tagging, ou Part of Speech tagging, é
uma tarefa do processamento de linguagem natural em
que