Questões de Concurso
Comentadas para ipea
Foram encontradas 547 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Infraestrutura de Tecnologia da Informação |
Q2383185
Redes de Computadores
No nível mais baixo da rede de comunicação de dados, a
entrega dos pacotes não é confiável. Esses pacotes podem ser perdidos ou destruídos quando os erros de transmissão interferem com os dados, quando o hardware de
transmissão falha ou quando as redes ficam muito sobrecarregadas. Para resolver essa questão, a arquitetura da
internet fornece um protocolo de comunicação que assegura a entrega de mensagens fim a fim, com controle de
erro e controle de fluxo.
Esse protocolo é o
Esse protocolo é o
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Infraestrutura de Tecnologia da Informação |
Q2383184
Redes de Computadores
O Internet Protocol Version 6 (IPv6) permite a configuração de vários endereços simultâneos por conexão e rede.
Um endereço de destino de um datagrama pode ser classificado em uma de três categorias. Em uma dessas categorias, o destino é um conjunto de computadores, possivelmente em vários locais, e o datagrama é entregue a
cada um dos integrantes do conjunto.
Essa categoria é a
Essa categoria é a
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Infraestrutura de Tecnologia da Informação |
Q2383183
Redes de Computadores
O protocolo Spanning Tree, STP, é usado principalmente para evitar loops da camada 2 e tempestades de
broadcast, e também é usado para redundância de rede.
Os switches de uma rede local, quando habilitados com
o STP, executam o algoritmo spanning tree para eleger
o root bridge. O switch eleito será responsável por enviar
mensagens de configuração junto com outras informações para os switches diretamente conectados a ele que,
por sua vez, encaminharão essas mensagens para seus
switches vizinhos.
Tais mensagens são conhecidas como
Tais mensagens são conhecidas como
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Infraestrutura de Tecnologia da Informação |
Q2383182
Redes de Computadores
As Virtual LAN (VLAN) são usadas para segmentar, logicamente, uma rede local em diferentes domínios de
broadcast. Dessa forma, os dispositivos em uma VLAN
agem como se estivessem em sua própria rede independente, mesmo quando compartilham uma infraestrutura
comum com outras VLAN. Um padrão do IEEE permite a
definição, a operação e a administração de topologias de
VLAN dentro de uma infraestrutura de rede local.
Esse padrão é o IEEE
Esse padrão é o IEEE
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Infraestrutura de Tecnologia da Informação |
Q2383181
Redes de Computadores
A rede sem fio wi-fi é vulnerável a vários tipos de ataques.
Nesse tipo de rede, ao contrário do tráfego de dados, que
pode ser criptografado para proporcionar um nível de confidencialidade, os quadros de controle e de gerenciamento
devem ser transmitidos em texto claro, não criptografados.
Embora esses quadros não possam ser criptografados, é
importante protegê-los contra falsificação para aumento
da segurança da rede sem fio.
Um padrão do IEEE que possibilita proteger alguns quadros de controle e gerenciamento, como os quadros de Disassociation e Deauthentication, é o
Um padrão do IEEE que possibilita proteger alguns quadros de controle e gerenciamento, como os quadros de Disassociation e Deauthentication, é o
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Infraestrutura de Tecnologia da Informação |
Q2383180
Redes de Computadores
Um roteador IPv4 utiliza sua tabela de rotas estática para
tomar decisões sobre encaminhamento de pacotes. Considere que esse roteador recebeu um pacote IPv4 com o
endereço de destino 200.240.173.167. A Tabela de rotas
desse roteador está apresentada a seguir.
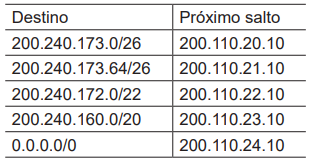
O endereço IPv4 do Próximo salto que será selecionado pelo roteador para fazer o encaminhamento do pacote é
O endereço IPv4 do Próximo salto que será selecionado pelo roteador para fazer o encaminhamento do pacote é
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Infraestrutura de Tecnologia da Informação |
Q2383179
Redes de Computadores
O Domain Name System (DNS) é um sistema hierárquico
e distribuído de gestão de nomes para computadores e
serviços. Uma resolução de um nome pode envolver consultas a vários servidores DNS; logo, para otimizar consultas futuras, as respostas são, em geral, mantidas em
cache durante um período de tempo determinado. Se um
Man-In-The-Middle conseguir interceptar uma consulta
DNS, poderá inserir um resultado falso para a consulta na
cache do servidor DNS que realizou a consulta.
Esse ataque ao serviço DNS é conhecido como DNS Cache
Esse ataque ao serviço DNS é conhecido como DNS Cache
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Infraestrutura de Tecnologia da Informação |
Q2383178
Redes de Computadores
O monitoramento da operação dos equipamentos e dos
serviços de rede é fundamental para uma ação proativa
na resolução de eventuais problemas. O Simple Network
Management Protocol (SNMP) é um padrão estabelecido
pelo Internet Engineering Task Force (IETF) para possibilitar o gerenciamento remoto de equipamentos e serviços
de rede. Esse padrão adota uma arquitetura cliente-servidor na qual o gerente SNMP, cliente, pode consultar ou alterar informações de gerenciamento de um agente SNMP,
servidor, que esteja em execução no equipamento ou no
sistema do serviço de rede monitorado. O padrão SNMP
também adota uma arquitetura produtor-consumidor na
qual o agente pode enviar notificações ao gerente sobre
eventos assíncronos que ocorrem no equipamento ou no
serviço de rede monitorado.
Essas notificações são conhecidas como
Essas notificações são conhecidas como
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Infraestrutura de Tecnologia da Informação |
Q2383177
Redes de Computadores
O NGINX (engine x) é amplamente usado como um servidor proxy reverso e oferece recursos para balanceamento
de carga e tolerância a falhas. Por ter alto desempenho,
estabilidade e baixo consumo de recursos, é uma escolha popular para muitos sites e aplicações web. Para o
NGINX fazer o balanceamento de carga do tráfego HTTP
para um grupo de servidores, o nome do grupo deve ser
especificado na diretiva proxy_pass.
Para especificar o grupo, o administrador do sistema deve usar a diretiva
Para especificar o grupo, o administrador do sistema deve usar a diretiva
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Infraestrutura de Tecnologia da Informação |
Q2383176
Sistemas Operacionais
Para atingir a alta disponibilidade, um sistema deve ser
modelado para evitar qualquer tipo de perda de serviço,
reduzindo ou gerenciando suas falhas e minimizando o
tempo de parada programada. Para minimizar as interrupções não planejadas, deve-se recorrer à redundância de
componentes e a recursos de tolerância a falhas. Uma
forma de fazer isso para serviços de rede é a implantação
de um cluster de servidores de alta disponibilidade.
Nesse tipo de cluster, o failover é o processo de
Nesse tipo de cluster, o failover é o processo de
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Infraestrutura de Tecnologia da Informação |
Q2383175
Sistemas Operacionais
O servidor web é uma parte crucial das aplicações web.
Dentre várias boas práticas de segurança, é importante
minimizar a quantidade de informações fornecidas pelo
servidor web nos campos de cabeçalho de resposta que
são enviados para os clientes web.
Nesse contexto, para fazer um servidor web Apache enviar APENAS a palavra Apache no campo de cabeçalho de resposta Server, o administrador desse servidor deve configurar o uso da diretiva
Nesse contexto, para fazer um servidor web Apache enviar APENAS a palavra Apache no campo de cabeçalho de resposta Server, o administrador desse servidor deve configurar o uso da diretiva
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Infraestrutura de Tecnologia da Informação |
Q2383174
Redes de Computadores
As unidades de armazenamento podem ser locais ou remotas e podem ser conectadas aos sistemas operacionais ou aos hypervisors de diferentes formas. Considere
que o administrador de um sistema operacional quer conectar esse sistema a um disco virtual remoto, de modo a
ter acesso aos blocos de dados do disco por meio de um
protocolo de comunicação de alta velocidade.
Dentre as arquiteturas de armazenamento mais comuns, aquela que atende à necessidade desse administrador é a
Dentre as arquiteturas de armazenamento mais comuns, aquela que atende à necessidade desse administrador é a
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Infraestrutura de Tecnologia da Informação |
Q2383173
Sistemas Operacionais
Os sistemas operacionais fornecem ferramentas para facilitar a instalação e a atualização de pacotes de software.
A ferramenta do sistema operacional Linux Ubuntu Server que fornece uma interface de linha de comando de alto nível para o sistema de gerenciamento de pacotes é o
A ferramenta do sistema operacional Linux Ubuntu Server que fornece uma interface de linha de comando de alto nível para o sistema de gerenciamento de pacotes é o
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Infraestrutura de Tecnologia da Informação |
Q2383172
Sistemas de Informação
O Kubernetes automatiza tarefas operacionais de gerenciamento de contêineres e inclui comandos integrados para implantação, manutenção e monitoramento de
aplicativos. Suponha que um administrador de uma infraestrutura com Kubernetes precise determinar se possui
autorização para criar pods em todos os namespaces disponíveis.
Para fazer essa consulta, esse administrador pode usar o comando
Para fazer essa consulta, esse administrador pode usar o comando
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Infraestrutura de Tecnologia da Informação |
Q2383171
Sistemas Operacionais
Num ambiente virtual, vários hosts Hyper-V estão em operação, e cada host se encontra com uma carga de trabalho diferente. Nesse contexto, considere uma situação na
qual os recursos de hardware em um determinado host
estão quase esgotados e há outro host com recursos de
hardware suficientes para possibilitar a migração de uma
máquina virtual (VM) que se encontra no host sobrecarregado.
Para fazer a migração da VM em execução entre os hosts Hyper-V, o administrador desse ambiente virtual pode usar o cmdlet
Para fazer a migração da VM em execução entre os hosts Hyper-V, o administrador desse ambiente virtual pode usar o cmdlet
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Infraestrutura de Tecnologia da Informação |
Q2383170
Redes de Computadores
Uma infraestrutura ágil deve permitir que administradores
de sistemas possam facilmente automatizar tarefas repetitivas, implantar aplicativos rapidamente e gerenciar servidores de forma proativa, tanto no ambiente local quanto
na nuvem. Dentre os vários projetos de código aberto disponibilizados para essa finalidade, está o Foreman, que
contém vários módulos para funcionalidades adicionais,
como plug-in e suporte a recursos de computação.
O plug-in opcional que pode ser usado para descobrir hosts em redes que o Foreman não consegue acessar diretamente é o
O plug-in opcional que pode ser usado para descobrir hosts em redes que o Foreman não consegue acessar diretamente é o
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Infraestrutura de Tecnologia da Informação |
Q2383169
Redes de Computadores
O HyperText Transfer Protocol (HTTP) é o protocolo de
comunicação da World Wide Web, utilizado pelo navegador (cliente web) para troca de mensagem com o servidor
web. Esse protocolo de nível de aplicação não assegura
a proteção dos dados em trânsito pois não oferece mecanismos de segurança para o controle de integridade, de
autenticidade e de sigilo das suas mensagens. Para suprir
essa deficiência do protocolo, a prática comum é utilizar
o HTTPS para proteger a troca de mensagens do HTTP
entre o cliente web e o servidor web, com o uso de uma
camada de segurança do nível de aplicação.
Essa camada de segurança utilizada pelo HTTPS é a
Essa camada de segurança utilizada pelo HTTPS é a
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Infraestrutura de Tecnologia da Informação |
Q2383168
Sistemas Operacionais
O Docker é uma ferramenta muito popular para a criação, a
implantação e a execução de aplicativos usando contêineres formados a partir de imagens que contêm o código ou
binário, runtimes, dependências e outros elementos do sistema de arquivos para executar um aplicativo. Quando as
imagens deixam de ser utilizadas, permanecem ocupando
espaço na área de armazenamento. Há um comando que
pode ser usado para remover todas as imagens não utilizadas, ou seja, que não estão associadas a, pelo menos,
um contêiner.
Esse comando é o
Esse comando é o
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Infraestrutura de Tecnologia da Informação |
Q2383167
Sistemas Operacionais
O administrador de um sistema operacional Windows
Server deseja criar um script Powershell para desabilitar
todas as contas numa unidade organizacional
(Organization Unit – OU) no Active Directory. Para executar
essa tarefa, o administrador deseja usar um cmdlet que
recupere o objeto de conta de cada usuário de uma OU
e depois passe os objetos pela pipeline para outro cmdlet
desabilitar as contas correspondentes.
Dois cmdlets que podem ser usados para essa tarefa são
Dois cmdlets que podem ser usados para essa tarefa são
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Infraestrutura de Tecnologia da Informação |
Q2383166
Sistemas Operacionais
O serverless é uma categoria de computação em nuvem
que fornece uma plataforma para desenvolver e implementar aplicações sem se preocupar com as tarefas rotineiras de provisionamento e gerenciamento de servidores. A plataforma de orquestração de contêineres do
Kubernetes é uma solução bem popular na execução de
ambientes serverless. Um projeto da comunidade open
source fornece componentes para implantar, executar e
gerenciar aplicações serverless no Kubernetes.
Esse projeto é o
Esse projeto é o