Questões de Concurso
Para ipea
Foram encontradas 1.406 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Comunicação Social e Divulgação Científica |
Q2380369
Jornalismo
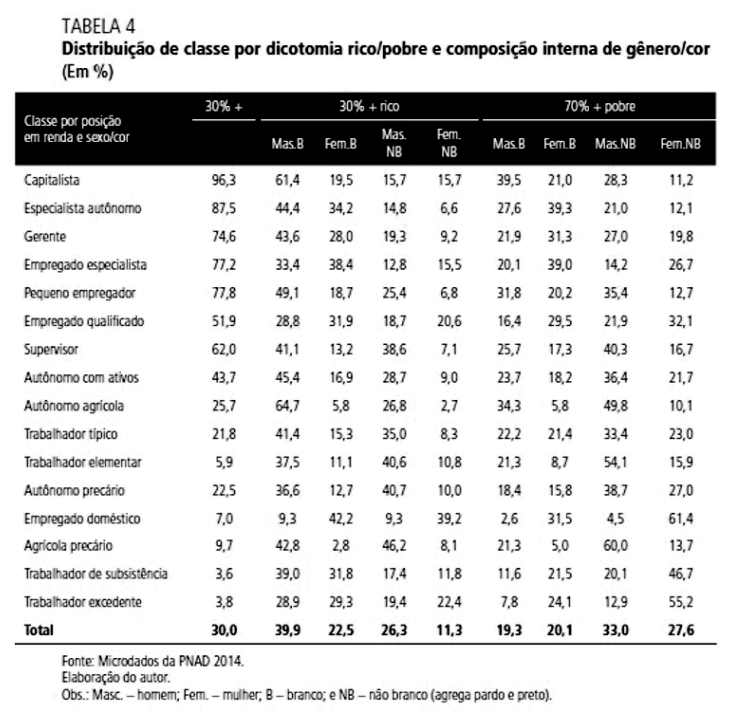
POMPEU, J.C.B.; VIANA, A.R.; MAGALHÃES, L.C.G.; GONÇALVES, A.P.V.(org.). Dinâmica econômica, mudanças sociais e novas pautas de políticas públicas. Brasília, DF: Ipea, 2023. p. 144. ISBN: 978-65-5635-064-6. DOI: https://dx.doi.org/10.38116/978-65-5635-064-6
A Tabela acima está na página 144 do estudo “Dinâmica econômica, mudanças sociais e novas pautas de políticas públicas”, publicado pelo Ipea, em 2023. Logo abaixo, o texto esclarece: “O desenho da tabela 4 expressa, de certa forma, os cruzamentos ou as associações entre empregos ou posições de classe, ordenamentos da renda e categorias de status. Nos décimos de renda de todas as fontes, foi feito o recorte entre os 30% mais ricos e os 70% mais pobres.” A partir desse exemplo, constata-se que, para que uma pesquisa com muitos gráficos e tabelas seja compreendida pelo leitor leigo, os repórteres e editores devem
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Comunicação Social e Divulgação Científica |
Q2380368
Jornalismo
Comparando-se divulgação científica a jornalismo científico, constata-se o seguinte:
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Comunicação Social e Divulgação Científica |
Q2380367
Jornalismo
A pandemia da Covid-19 trouxe, recentemente, um intenso debate fomentado por grupos antivacina, alguns deles
supostamente ou diretamente embasados em estudos
científicos que questionavam a eficácia da imunização no
combate à doença.
No caso da cobertura jornalística de temas controversos como esse, recomenda-se adotar que posicionamento?
No caso da cobertura jornalística de temas controversos como esse, recomenda-se adotar que posicionamento?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Comunicação Social e Divulgação Científica |
Q2380366
Jornalismo
O repórter especializado em jornalismo científico sugere
pautas que englobam vários campos da ciência e do comportamento, mas raramente a área da
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Comunicação Social e Divulgação Científica |
Q2380365
Jornalismo
Nos últimos meses, os brasileiros experimentaram mudanças climáticas avassaladoras, como as ondas de calor
que provocaram sensações térmicas de 60 graus no Rio
de Janeiro, enchentes na Região Sul do país e a mais
longa seca dos últimos tempos na Amazônia.
Cabe ao jornalista científico buscar a fonte adequada para falar oficialmente sobre o tema, que, nesse caso, é
Cabe ao jornalista científico buscar a fonte adequada para falar oficialmente sobre o tema, que, nesse caso, é
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Comunicação Social e Divulgação Científica |
Q2380364
Jornalismo
Um repórter que cobre jornalismo científico recebeu o seguinte release: “Ipea analisa preço dos principais produtos agropecuários — Estudo publicado em parceria com
Conab e Cepea”, informando que o estudo estará disponível para leitura no site do Instituto. O repórter se interessou pela pauta e conversou com o seu editor para fazer a
reportagem.
Considerando-se que, nesse caso, é necessário seguir uma série de boas práticas no aproveitamento do conteúdo fornecido, o seguinte procedimento deve ser evitado pelo repórter:
Considerando-se que, nesse caso, é necessário seguir uma série de boas práticas no aproveitamento do conteúdo fornecido, o seguinte procedimento deve ser evitado pelo repórter:
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Comunicação Social e Divulgação Científica |
Q2380363
Comunicação Social
O uso intensivo das redes sociais no país não chama
a atenção somente dessas empresas. O movimento
tem diversos impactos na economia brasileira: companhias investem na publicidade dentro dessas plataformas, principalmente por meio de influenciadores
digitais; bares têm surgido ou se adaptado para serem
“instagramáveis”, ou seja, com ambientes e cardápios
mais atrativos para fotografias; e profissionais comercializam cada dia mais por meio dessas ferramentas
de interação.
BRASIL é o terceiro país que mais consome redes sociais. O Globo. Disponível em: https://oglobo.globo.com/economia/ tecnologia/noticia/2023/03/brasil-e-o-terceiro-pais-que-maisconsome-redes-sociais.ghtml. Acesso em: 27 dez. 2023.
O grande sucesso das redes sociais no Brasil levou a imprensa a marcar presença com perfis nessas plataformas de relacionamento.
Os posts usados pelos jornais de referência se assemelham a qual elemento gráfico presente há algumas décadas na mídia impressa?
BRASIL é o terceiro país que mais consome redes sociais. O Globo. Disponível em: https://oglobo.globo.com/economia/ tecnologia/noticia/2023/03/brasil-e-o-terceiro-pais-que-maisconsome-redes-sociais.ghtml. Acesso em: 27 dez. 2023.
O grande sucesso das redes sociais no Brasil levou a imprensa a marcar presença com perfis nessas plataformas de relacionamento.
Os posts usados pelos jornais de referência se assemelham a qual elemento gráfico presente há algumas décadas na mídia impressa?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Comunicação Social e Divulgação Científica |
Q2380362
Comunicação Social
A impessoalidade é um princípio basilar da comunicação das ações e publicações do Ipea, o que se reflete
em uma comunicação de caráter informativo, ou educativo, ou de orientação social, ou de publicação e disseminação de produtos editoriais, e realização de eventos
voltados à análise de problemas públicos coletivos e de
desafios ao desenvolvimento.
BRASIL, Portaria IPEA no 411 de 10 de outubro de 2023 - Capítulo II - Dos princípios e missão da comunicação integrada do IPEA – Art. 4o . Boletim Gestão e Desenvolvimento de Pessoas. n. 4, 16 out. 2023. Disponível em: https://www.ipea.gov.br/portal/images/stories/ PDFs/231018_portaria_411.pdf. Acesso em: 16 jan. 2024.
O Art. 4º da Portaria Ipea nº 411 determina que as ações de comunicação integrada da instituição sigam o mesmo princípio da isenção presente no processo produtivo do jornalismo.
Esse princípio significa
BRASIL, Portaria IPEA no 411 de 10 de outubro de 2023 - Capítulo II - Dos princípios e missão da comunicação integrada do IPEA – Art. 4o . Boletim Gestão e Desenvolvimento de Pessoas. n. 4, 16 out. 2023. Disponível em: https://www.ipea.gov.br/portal/images/stories/ PDFs/231018_portaria_411.pdf. Acesso em: 16 jan. 2024.
O Art. 4º da Portaria Ipea nº 411 determina que as ações de comunicação integrada da instituição sigam o mesmo princípio da isenção presente no processo produtivo do jornalismo.
Esse princípio significa
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Comunicação Social e Divulgação Científica |
Q2380361
Jornalismo
As plataformas digitais podem ser entendidas, sob esta
perspectiva, como um elemento organizacional, ou até
mesmo morfológico (Castells, 1996; 2009), fundamental deste novo paradigma tecnoeconômico. Sob o signo
da plataformização, as sociedades vêm organizando
novas atividades econômicas e transformando atividades preexistentes. Elas têm gerado novas formas de
sociabilidade e de produção e consumo cultural, imiscuindo-se, portanto, em todo tipo de organização social. Dessa maneira, o estudo das plataformas digitais
pertence a um grupo de estudos não apenas econômicos, mas das humanidades, que busca compreender
como esta configuração da interação social ocorre mediada pelas tecnologias contemporâneas.
CHARINI, T.; SILVA NETO, V.J.; PEREIRA, L.; SZIGETHY, L. Plataformas digitais: mapeamento semissistemático e interdisciplinar do conhecimento produzido nas universidades brasileiras. Brasília, DF: Ipea, 2023 (Texto para discussão, n. 2829). Disponível em: https://www.researchgate.net/publication/367046050_ Plataformas_digitais_mapeamento_semissitematico_e_ ìnterdisciplinar_do_conhecimento_produzido _nas_universidades_brasileiras. Acesso em: 27 dez. 2023.
No texto acima, os autores afirmam que atividades preexistentes se transformam impulsionadas por avanços tecnológicos.
Um exemplo de uma ressignificação de atividade preexistente no campo jornalístico, que ganhou relevância após a onda de disseminação de fake news, é
CHARINI, T.; SILVA NETO, V.J.; PEREIRA, L.; SZIGETHY, L. Plataformas digitais: mapeamento semissistemático e interdisciplinar do conhecimento produzido nas universidades brasileiras. Brasília, DF: Ipea, 2023 (Texto para discussão, n. 2829). Disponível em: https://www.researchgate.net/publication/367046050_ Plataformas_digitais_mapeamento_semissitematico_e_ ìnterdisciplinar_do_conhecimento_produzido _nas_universidades_brasileiras. Acesso em: 27 dez. 2023.
No texto acima, os autores afirmam que atividades preexistentes se transformam impulsionadas por avanços tecnológicos.
Um exemplo de uma ressignificação de atividade preexistente no campo jornalístico, que ganhou relevância após a onda de disseminação de fake news, é
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Comunicação Social e Divulgação Científica |
Q2380360
Português
Nunca me esquecerei desse acontecimento
na vida de minhas retinas tão fatigadas.
Nunca me esquecerei que no meio do caminho
tinha uma pedra
tinha uma pedra no meio do caminho
no meio do caminho tinha uma pedra.
ANDRADE, C.D. No meio do caminho. In: Alguma poesia. 3. ed. Rio de Janeiro: Record, 2022. p. 47.
O poema No Meio do Caminho, se fosse adaptado para um texto do gênero jornalístico, seria chamado de
na vida de minhas retinas tão fatigadas.
Nunca me esquecerei que no meio do caminho
tinha uma pedra
tinha uma pedra no meio do caminho
no meio do caminho tinha uma pedra.
ANDRADE, C.D. No meio do caminho. In: Alguma poesia. 3. ed. Rio de Janeiro: Record, 2022. p. 47.
O poema No Meio do Caminho, se fosse adaptado para um texto do gênero jornalístico, seria chamado de
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Comunicação Social e Divulgação Científica |
Q2380359
Comunicação Social
A Coordenadoria de Comunicação do Ipea, por meio do
Manual de Relacionamento com a Imprensa, adverte os
pesquisadores para que não criem expectativas de que
uma longa entrevista certamente irá se tornar uma grande reportagem. O documento afirma que, muitas vezes, a
notícia vira uma nota ou nem mesmo é publicada porque
depende de vários fatores existentes no processo produtivo da notícia e conclui que “quem define o espaço que a
entrevista/reportagem terá é o editor”.
A afirmação final remete a um dos papéis assumidos pelos editores que é o de
A afirmação final remete a um dos papéis assumidos pelos editores que é o de
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Comunicação Social e Divulgação Científica |
Q2380358
Comunicação Social
O Manual de Relacionamento com a Imprensa do Ipea
ressalta a importância que os pedidos de entrevista recebidos diretamente pelos agentes públicos em exercício
nesse Instituto, tanto pesquisadores quanto servidores da
instituição, sejam encaminhados à Coordenação-Geral de
Imprensa e Comunicação Social.
Esse cuidado existe porque o papel essencial do jornalista que atua em assessoria de imprensa dentro dos conceitos éticos do jornalismo é
Esse cuidado existe porque o papel essencial do jornalista que atua em assessoria de imprensa dentro dos conceitos éticos do jornalismo é
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Comunicação Social e Divulgação Científica |
Q2380357
Comunicação Social
“Quando um cachorro morde uma pessoa, isso não é
notícia. Mas quando uma pessoa morde um cachorro,
isso sim é notícia”. A frase do norte-americano Charles
Anderson Dana, proferida em 1882, é um clássico repetido por vários profissionais desde então para deixar claro
o que leva um fato a receber o status de notícia.
O critério de noticiabilidade é reforçado pelo Manual de Relacionamento de Imprensa do Ipea quando recomenda “Jornalistas valorizam dados relevantes, o que é inédito, o alcance. Mostre os impactos da ação, da informação, como modificam a realidade do cidadão comum”.
No exemplo específico dado por Dana, está sendo destacado o valor-notícia
O critério de noticiabilidade é reforçado pelo Manual de Relacionamento de Imprensa do Ipea quando recomenda “Jornalistas valorizam dados relevantes, o que é inédito, o alcance. Mostre os impactos da ação, da informação, como modificam a realidade do cidadão comum”.
No exemplo específico dado por Dana, está sendo destacado o valor-notícia
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Comunicação Social e Divulgação Científica |
Q2380356
Comunicação Social
Ao fazer a cobertura da entrevista coletiva, realizada em 4
de dezembro de 2023, em que a Ministra do Planejamento
e Orçamento do Brasil, Simone Tebet, apresentou o Planejamento Estratégico Integrado (PEI) para os próximos
quatro anos em conjunto com presidentes do Ipea e do
IBGE, o repórter deve apresentar um texto jornalístico que
seja claro, conciso e acessível a todos os perfis de leitor.
Para tal, é preciso que o repórter incorpore a função de
Para tal, é preciso que o repórter incorpore a função de
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Comunicação Social e Divulgação Científica |
Q2380355
Comunicação Social
“‘Venham, façam o concurso do Ipea. O Ipea é para todos’, diz presidenta Luciana.”
O título da notícia veiculada no site do Ipea, em 4 de dezembro de 2023, contém aspas do entrevistado com destaque, mas a mesma frase não foi repetida na primeira linha do texto da matéria.
A ausência da declaração se dá porque começar a matéria jornalística, ou seja, abrir o lead com a fala entre aspas do entrevistado a partir da primeira frase só é aceitável quando a(o)
O título da notícia veiculada no site do Ipea, em 4 de dezembro de 2023, contém aspas do entrevistado com destaque, mas a mesma frase não foi repetida na primeira linha do texto da matéria.
A ausência da declaração se dá porque começar a matéria jornalística, ou seja, abrir o lead com a fala entre aspas do entrevistado a partir da primeira frase só é aceitável quando a(o)
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Comunicação Social e Divulgação Científica |
Q2380354
Comunicação Social
A facilidade da navegação por meio digital faz o leitor da
contemporaneidade ser mais crítico e impaciente. Diante
disso, a Coordenação-Geral de Imprensa e Comunicação
Social do Ipea, bem como a maioria das assessorias de
imprensa institucionais, procura saber de que forma os
conteúdos de entrevistas serão veiculados, se no formato de vídeo para redes sociais, podcast, ou algum outro.
A meta é orientar o entrevistado a ser objetivo, expondo
prioritariamente os elementos indispensáveis para a divulgação científica.
Essas atitudes reforçam duas características essenciais para esse caso, próprias do texto jornalístico do gênero informativo, que são
Essas atitudes reforçam duas características essenciais para esse caso, próprias do texto jornalístico do gênero informativo, que são
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Comunicação Social e Divulgação Científica |
Q2380353
Jornalismo
O Manual de Relacionamento com a Imprensa 2023 do
Ipea diz que “Tendo em vista que as atividades de pesquisa fornecem suporte técnico e institucional às ações
governamentais, na formulação de políticas públicas, muitos estudos desenvolvidos pelo Ipea têm potencial de se
tornar pauta”.
Mas, para além dessa afirmação, tem potencial nato para ser transformada em notícia a sugestão de pauta sobre
Mas, para além dessa afirmação, tem potencial nato para ser transformada em notícia a sugestão de pauta sobre
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Comunicação Social e Divulgação Científica |
Q2380352
Jornalismo
Diz o Manual de Relacionamento com a Imprensa do Ipea
que “Notícia é o relato de um fato. A informação apenas
vai se tornar um produto com potencial para consumo
(notícia jornalística) após ser trabalhada e devidamente
elaborada pelo assessor de imprensa, de forma a torná-la
relevante, atraente e interessante”.
Essa recomendação tem como objetivo explicar aos pesquisadores que, nas regras próprias do jornalismo, o fato ou acontecimento tem potencial para se tornar notícia quando
Essa recomendação tem como objetivo explicar aos pesquisadores que, nas regras próprias do jornalismo, o fato ou acontecimento tem potencial para se tornar notícia quando
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Comunicação Social e Divulgação Científica |
Q2380351
Jornalismo
Os programas televisivos “No Mundo da Bola” (TV Brasil),
“Encontro” (TV Globo) e “Jornal Nacional” (TV Globo) podem ser classificados de acordo com suas características,
respectivamente, pelos gêneros
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Comunicação Social e Divulgação Científica |
Q2380350
Jornalismo
O Brasil corre o risco de ser apenas um usuário de
sistemas de inteligência artificial (IA) desenvolvidos no
exterior. A dependência de outros países e de grandes
empresas nessa área pode comprometer a segurança
e a soberania nacional, além de diminuir a competitividade das empresas brasileiras. Para reverter esse cenário, é preciso investir em infraestrutura e na formação
de profissionais altamente qualificados e em um corpo
de pesquisadores capaz de promover avanços tecnológicos e propor soluções inovadoras.
ANDRADE, R. ABC faz recomendações para avanço da inteligência artificial no Brasil. Disponível em: https://www.ipea.gov. br/cts/pt/central-de-conteudo/artigos/artigos/398-abc-fazrecomendacoes-para-avanco-da-inteligencia-artificial-no-br. Acesso em: 27 dez. 2023.
O texto acima tem as características essenciais para o formato de artigo. Se fosse publicado em um jornal impresso, ele seria submetido a práticas que garantem os princípios da isenção e da objetividade, adotados pelo jornalismo a partir de 1950.
Entre essas práticas está o(a)
ANDRADE, R. ABC faz recomendações para avanço da inteligência artificial no Brasil. Disponível em: https://www.ipea.gov. br/cts/pt/central-de-conteudo/artigos/artigos/398-abc-fazrecomendacoes-para-avanco-da-inteligencia-artificial-no-br. Acesso em: 27 dez. 2023.
O texto acima tem as características essenciais para o formato de artigo. Se fosse publicado em um jornal impresso, ele seria submetido a práticas que garantem os princípios da isenção e da objetividade, adotados pelo jornalismo a partir de 1950.
Entre essas práticas está o(a)