Questões de Concurso
Para analista judiciário - estatística
Foram encontradas 3.799 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Com relação à teoria geral de amostragem, considere as afirmativas abaixo.
I. A realização de amostragem aleatória simples só é feita para amostragem sem reposição.
II. A amostragem estratificada consiste na divisão de uma população em grupos segundo alguma característica conhecida. Os estratos da população devem ser mutuamente exclusivos.
III. Em uma amostra por conglomerados a população é dividida em subpopulações distintas.
IV. A amostragem sistemática é um plano de amostragem não probabilístico.
É correto o que se afirma APENAS em
Seja X a variável aleatória que representa o número de chamadas por minuto recebidas por um PBX. Sabe-se que X tem média λ e que P(X = 3) = P(X = 4). Supondo que a distribuição de Poisson seja adequada para X, a probabilidade de que ocorra uma chamada em 30 segundos é
Atenção: Para resolver às questões de números 38 e 39 considere o texto abaixo. Uma amostra com 80 pares de observações (Xi, Yi), i = 1, 2, 3, . . . , 80; sendo as somas das observações de Xi e Yi iguais a 560 e 2.400, respectivamente. Um estudo tinha como objetivo analisar a relação entre X e Y e adotou-se o modelo Yi = α + βXi + εi, em que i corresponde a i-ésima observação, α e β são parâmetros desconhecidos e εi o erro aleatório com as respectivas hipóteses consideradas para a regressão linear simples. Utilizou-se o método dos mínimos quadrados, com base na amostra, para o ajustamento do modelo obtendo-se para a estimativa de α o valor de 2.
Se Y = f(X), em que f(X) é a função linear obtida pelo método dos mínimos quadrados, então a função Z, tal que Z = XY, atinge o valor mínimo quando X for igual a
Atenção: Para resolver às questões de números 38 e 39 considere o texto abaixo. Uma amostra com 80 pares de observações (Xi, Yi), i = 1, 2, 3, . . . , 80; sendo as somas das observações de Xi e Yi iguais a 560 e 2.400, respectivamente. Um estudo tinha como objetivo analisar a relação entre X e Y e adotou-se o modelo Yi = α + βXi + εi, em que i corresponde a i-ésima observação, α e β são parâmetros desconhecidos e εi o erro aleatório com as respectivas hipóteses consideradas para a regressão linear simples. Utilizou-se o método dos mínimos quadrados, com base na amostra, para o ajustamento do modelo obtendo-se para a estimativa de α o valor de 2.
Considerando a função linear obtida pelo método dos mínimos quadrados, tem-se que quando X varia de 1 unidade Y varia de
Seja uma variável aleatória X, tal que uma amostra aleatória de 5 elementos {100, 120, 180, 200, 240} foi extraída da população. O intervalo [120, 200] refere-se a um intervalo de confiança encontrado para a mediana de X. O nível de confiança deste intervalo é de
O dirigente de uma empresa deverá decidir entre dois candidatos, Antônio e Paulo, qual ocupará o cargo de gerente administrativo. Para cada candidato foi aplicada uma mesma prova constituída de 16 testes de assuntos diversos. Subtraindo dos escores apresentados por Antônio os respectivos escores apresentados por Paulo, observa-se a presença de sinal negativo nas diferenças dos escores de 4 testes e sinal positivo nas 12 restantes, não ocorrendo diferença nula. Aplica-se o teste dos sinais para decidir se a proporção populacional de sinais negativos (p) é igual a 0,50, ao nível de significância de 2α, considerando as hipóteses: H0 : p = 0,50 (hipótese nula) e H1 : p ≠ 0,50 (hipótese alternativa). Aproximando a distribuição binomial pela normal, obteve-se o escore reduzido r correspondente para comparação com o valor crítico z da distribuição normal padrão (Z) tal que P(|Z| ≤ z) = 2α. Então,
O gerente de produção de uma grande fábrica de farinha garante à sua rede de atacadistas que cada pacote produzido não contém menos de 1 kg de farinha. Um comprador desconfiado extrai uma amostra aleatória de 25 pacotes e encontra para esta amostra uma média m, em kg, e uma variância de 0,04 (kg)2. Supondo que a quantidade de farinha em cada pacote apresente uma distribuição normal com média μ e variância σ2 desconhecida, deseja-se saber se o gerente tem razão a um nível de significância de 5% com a realização do teste t de Student. Seja H0 a hipótese nula do teste (μ = 1 kg), H1 a hipótese alternativa (μ < 1 kg) e t o valor do quantil da distribuição t de Student tal que P(|t| ≥ 1,71) = 0,05, tanto para 24 como para 25 graus de liberdade. Sabendo-se que H0 foi rejeitada, então o valor encontrado para m foi, no máximo,
Em uma cidade é realizada uma pesquisa sobre a preferência dos eleitores com relação a um determinado candidato, que afirma ter 60% da preferência. Uma amostra aleatória de tamanho 600 foi extraída da população, considerada de tamanho infinito, sendo que 330 eleitores manifestaram sua preferência pelo candidato. Com base nesta amostra, deseja-se testar a hipótese H0 : p = 60% (hipótese nula) contra H1 : p ≠ 60% (hipótese alternativa), em que p é a proporção dos eleitores que têm preferência pelo candidato. Para a análise considerou-se normal a distribuição amostral da frequência relativa dos eleitores que têm preferência pelo candidato e que na distribuição normal padrão Z a probabilidade P(|Z| ≤ 1,96) = 95% e P(|Z| ≤ 2,58) = 99%. A conclusão é que H0
Seja X uma variável aleatória representando a duração de vida de um equipamento. O desvio padrão populacional de X é igual a 20 horas. Uma amostra aleatória de 100 equipamentos forneceu uma duração de vida média igual a 1.000 horas obtendo-se um intervalo de confiança de 95% para a média populacional igual a [996,08 ; 1.003,92] (considerando a população normalmente distribuída e de tamanho infinito). Caso o tamanho da amostra tivesse sido de 400 e obtendo-se a mesma duração de vida média de 1.000 horas, o novo intervalo de confiança de 95% apresentaria uma amplitude de
Uma variável aleatória X apresenta uma média igual a 100. Sabe-se que pelo Teorema de Tchebyshev a probabilidade mínima de que X pertença ao intervalo (80 , 120) é igual a 84%. A variância de X é igual a
Um estudo tem o objetivo de verificar se existe independência entre tipos de crimes e regiões de um país. A seguinte Tabela de Contingência mostra os números observados em uma amostra aleatória de tamanho n = 789 casos registrados nas regiões.
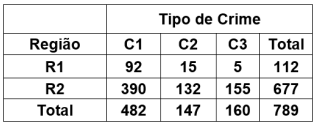
Sabe-se que 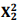 = 27,91 e P( > 27,91) = 0,0000.
Então, é correto afirmar que as frequências
esperadas das células (C1, R2) e (C3, R1), o
valor-p e a decisão quanto à relação entre Tipo de
Crime e Região, do teste da hipótese de
independência entre Tipo de Crime e Região,
serão:
= 27,91 e P( > 27,91) = 0,0000.
Então, é correto afirmar que as frequências
esperadas das células (C1, R2) e (C3, R1), o
valor-p e a decisão quanto à relação entre Tipo de
Crime e Região, do teste da hipótese de
independência entre Tipo de Crime e Região,
serão:
Supondo que [X1, X2 , ... , Xn] seja uma amostra aleatória da variável aleatória X com distribuição Poisson
com parâmetro θ, ou seja, P(θ), é correto afirmar que
Considere que um estatístico construiu o seguinte código em Python para ler um conjunto de cinco números inteiros:

O algoritmo solicita ao usuário para digitar um número de cada vez e, após o último número ser digitado, o algoritmo imprime na tela o conjunto dos 5 números inteiros digitados. O código em Python apresentado contém um erro. Assinale a alternativa que conserta o código e permite a execução dessas tarefas descritas.
A forma geral de representar uma classe de séries temporais não estacionárias é o modelo utorregressivo integrado médias móveis de ordem (p, d, q), ou seja, ARIMA(p, d, q), em que p é o grau do polinômio aracterístico da parte autorregressiva Φ(B), q é o grau do polinômio característico da parte média móveis θ(B) e d é o grau de diferenciação ▽d, ou seja, Φ(B)▽dZt = θ(B)at em que ⊽dZt = ωt. Desse modo, tem-se Φ(B)ωt = θ(B)at que é um modelo ARMA(p, q).
A uma determinada série temporal, ajustou-se um
modelo da classe ARIMA(p, d, q), e os resultados
do ajuste estão expostos a seguir:
Modelo ARIMA ajustado à série temporal
Então, é correto afirmar, com aproximação de três
(03) casas decimais, que
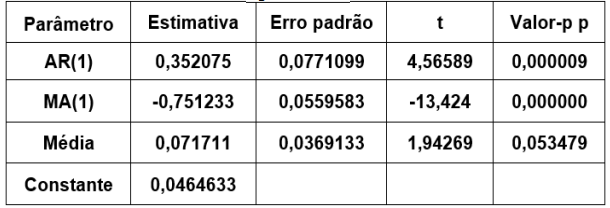
Considere a seguinte série temporal:
É correto afirmar que a média, a variância e a
autocorrelação de defasagem 2 dessa série
temporal, assumindo o estimador de máxima
verossimilhança para a variância, são,
respectivamente:
Os seguintes gráficos correspondem a
determinada série temporal e foram obtidos em
uma análise exploratória antes de ajustar um
modelo de previsão:
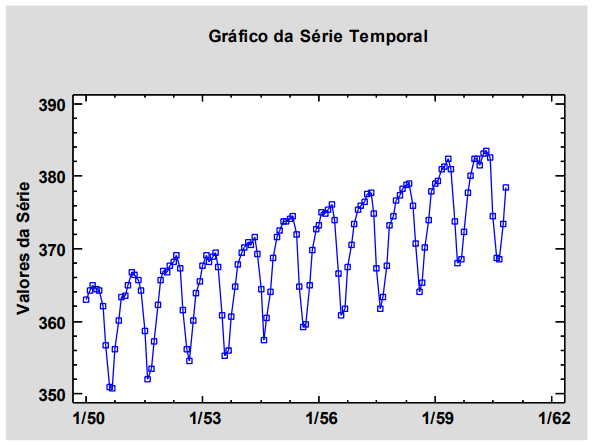
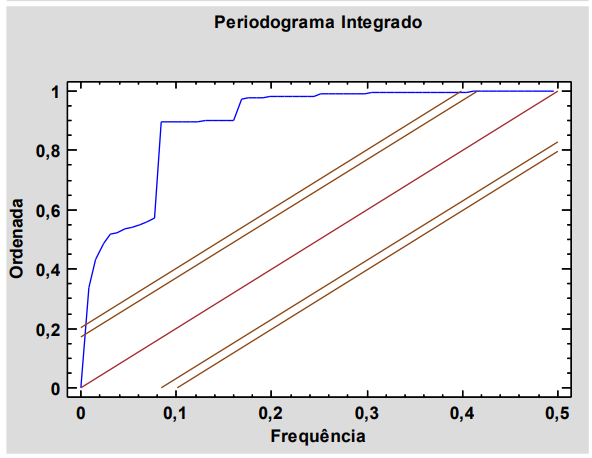
Observando os gráficos, é correto afirmar que
Seja a amostra aleatória de tamanho pequeno [X1, X2, ... , X10] de uma variável aleatória X com distribuição de probabilidade normal com média μ e variância σ2, então, as estatísticas x̄–μ/σ/√10, x̄–μ/s/√10, x̄–μ/σ e x̄–μ/s têm quais distribuições, respectivamente?