Questões de Concurso
Para tecnologista pleno i - desenvolvimento ou aprimoramento de sistema de assimilação de dados nas componentes do sistema terrestre e de aplicações para monitoramento do processo de assimilação
Foram encontradas 45 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518317
Matemática
Algoritmos para assimilação de dados geralmente envolvem cálculos
complexos que dependem de diversos fatores, como o tamanho dos
espaços de estados, número de pontos da grade em questão,
tamanho da janela de assimilação, etc. Frequentemente, observa-se
que dois algoritmos usados para solucionar um mesmo problema
podem ter eficiências diferentes, por conta de diferenças em suas
implementações.
Uma maneira de se mensurar e representar a complexidade de um algoritmo é contabilizar o número de operações de ponto-flutuante (flops) necessárias para executá-lo e utilizar a notação “O-grande”.
Considere o algoritmo a seguir, implementado em uma linguagem de pseudocódigo autoexplicativa.

A complexidade desse algoritmo será
Uma maneira de se mensurar e representar a complexidade de um algoritmo é contabilizar o número de operações de ponto-flutuante (flops) necessárias para executá-lo e utilizar a notação “O-grande”.
Considere o algoritmo a seguir, implementado em uma linguagem de pseudocódigo autoexplicativa.
A complexidade desse algoritmo será
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518316
Banco de Dados
Considere a lista de processos computacionais abaixo.
1. Integração do modelo não-linear para frente no tempo.
2. Integração do modelo não-linear para trás no tempo.
3. Integração do modelo adjunto para frente no tempo.
4. Integração do modelo adjunto para trás no tempo.
5. Integração do modelo tangente linear no loop interno.
6. Integração do modelo tangente linear no loop externo.
Assinale a opção que apresenta os processos realizados em assimilação de dados 4DVAR incremental, com restrição forte, na sequência correta de execução.
1. Integração do modelo não-linear para frente no tempo.
2. Integração do modelo não-linear para trás no tempo.
3. Integração do modelo adjunto para frente no tempo.
4. Integração do modelo adjunto para trás no tempo.
5. Integração do modelo tangente linear no loop interno.
6. Integração do modelo tangente linear no loop externo.
Assinale a opção que apresenta os processos realizados em assimilação de dados 4DVAR incremental, com restrição forte, na sequência correta de execução.
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518315
Geografia
O treinamento de algoritmos de inteligência artificial no
desenvolvimento de aplicações para assimilação de dados
meteorológicos exige o uso de bases de dados representativas de
estados atmosféricos. Embora bases de dados sintéticas sejam úteis
para treinamento, o uso de bases de dados reais é sempre preferível.
Assinale a opção que apresenta a base de dados real que descreve propriedades físicas de uma grande quantidade de situações atmosféricas, e que é utilizada para o treinamento de modelos de temperatura atmosférica.
Assinale a opção que apresenta a base de dados real que descreve propriedades físicas de uma grande quantidade de situações atmosféricas, e que é utilizada para o treinamento de modelos de temperatura atmosférica.
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518314
Geologia
A área de assimilação de dados acoplados tem recebido atenção
crescente de pesquisadores e tecnologistas interessados em
previsão numérica de tempo. Nos esquemas de assimilação
acoplados, dois ou mais modelos geofísicos são combinados,
frequentemente utilizando também técnicas diferentes de
assimilação.
Com relação à área de assimilação de dados acoplados, analise as afirmativas a seguir.
I. Busca-se utilizar os modelos geofísicos simultaneamente, de forma a produzirem previsões/análises consistentes entre si.
II. Busca-se modelar e analisar as interações da atmosfera com os solos, com os oceanos e com as geleiras do planeta, melhorando assim as capacidades de previsão numérica.
III. Combinam-se os modelos geofísicos, de forma que os resultados de previsão de um modelo sirvam de condição de contorno para a solução do(s) outro(s) modelo(s) a ele combinado(s).
Está correto o que se afirma em
Com relação à área de assimilação de dados acoplados, analise as afirmativas a seguir.
I. Busca-se utilizar os modelos geofísicos simultaneamente, de forma a produzirem previsões/análises consistentes entre si.
II. Busca-se modelar e analisar as interações da atmosfera com os solos, com os oceanos e com as geleiras do planeta, melhorando assim as capacidades de previsão numérica.
III. Combinam-se os modelos geofísicos, de forma que os resultados de previsão de um modelo sirvam de condição de contorno para a solução do(s) outro(s) modelo(s) a ele combinado(s).
Está correto o que se afirma em
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518313
Oceanografia Geológica
Aplicações de assimilação de dados em oceanografia produzem
análises e previsões de diferentes variáveis que caracterizam o
estado dos oceanos. O Escritório de Meteorologia do Reino Unido,
mais conhecido como Met Office, utiliza um modelo oceanográfico
global, chamado Forecasting Ocean Assimilation Model (FOAM), na
implementação de um esquema de assimilação variacional
tridimensional, conhecido como NEMOVAR.
Entre as variáveis que fazem parte do vetor de estados utilizado no NEMOVAR, encontram-se
Entre as variáveis que fazem parte do vetor de estados utilizado no NEMOVAR, encontram-se
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518312
Engenharia Ambiental e Sanitária
Uma abordagem recentemente desenvolvida para estimar
concentrações de agentes poluentes na atmosfera busca integrar
assimilação de dados variacional e processos Gaussianos para
aperfeiçoar previsões. Processos Gaussianos são modelos
estatísticos usados em aprendizado de máquina para descrever
observações feitas em algum domínio contínuo, tal como espaço ou
tempo.
Com relação aos processos Gaussianos para aprendizado de máquina, analise as afirmativas a seguir e assinale (V) para a verdadeira e (F) para a falsa.
( ) São uma generalização de dimensão infinita das distribuições normais multivariáveis, em que cada variável aleatória está diretamente relacionada a algum ponto do domínio contínuo considerado.
( ) São amplamente utilizados em modelos de regressão, em que se busca prever a forma de uma função contínua incorporando-se informações provenientes de observações.
( ) Podem ser utilizados em tarefas de classificação, em que se busca prever a probabilidade de um conjunto de dados de entrada pertencer a uma classe específica.
As afirmativas são, respectivamente,
Com relação aos processos Gaussianos para aprendizado de máquina, analise as afirmativas a seguir e assinale (V) para a verdadeira e (F) para a falsa.
( ) São uma generalização de dimensão infinita das distribuições normais multivariáveis, em que cada variável aleatória está diretamente relacionada a algum ponto do domínio contínuo considerado.
( ) São amplamente utilizados em modelos de regressão, em que se busca prever a forma de uma função contínua incorporando-se informações provenientes de observações.
( ) Podem ser utilizados em tarefas de classificação, em que se busca prever a probabilidade de um conjunto de dados de entrada pertencer a uma classe específica.
As afirmativas são, respectivamente,
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518311
Banco de Dados
A integração de técnicas de inteligência artificial e aprendizado de
máquina com assimilação de dados pode aumentar a confiabilidade
das previsões por introduzir modelos orientados a dados obtidos por
meio de observações. A performance dos modelos de aprendizado
de máquina pode ser medida por algumas métricas, como por
exemplo a métrica Mean Absolute Error (MAE).
Considere um modelo de regressão usado para prever valores de uma variável, conforme a tabela a seguir.
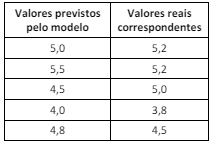
O MAE para o conjunto de dados representado na tabela será
Considere um modelo de regressão usado para prever valores de uma variável, conforme a tabela a seguir.
O MAE para o conjunto de dados representado na tabela será
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518310
Algoritmos e Estrutura de Dados
Algoritmos para assimilação de dados podem ser implementados de
maneira eficiente e otimizada por meio de paralelização de
processos.
O Parallel Data Assimilation Framework (PDAF) é um pacote de software que simplifica a implementação de métodos de assimilação, provendo versões totalmente paralelizadas de algoritmos, como por exemplo, diferentes versões dos Filtros de Kalman por conjunto (EnKF). Um dos requisitos de funcionamento do PDAF é o uso de um protocolo padronizado de comunicação para computação paralela.
O principal padrão de comunicação entre os processos paralelos executados em um sistema de memória distribuída, é denominado
O Parallel Data Assimilation Framework (PDAF) é um pacote de software que simplifica a implementação de métodos de assimilação, provendo versões totalmente paralelizadas de algoritmos, como por exemplo, diferentes versões dos Filtros de Kalman por conjunto (EnKF). Um dos requisitos de funcionamento do PDAF é o uso de um protocolo padronizado de comunicação para computação paralela.
O principal padrão de comunicação entre os processos paralelos executados em um sistema de memória distribuída, é denominado
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518309
Algoritmos e Estrutura de Dados
Assimilação de dados profunda (Deep Data Assimilation - DDA) é
uma técnica recente que integra aprendizado profundo e
assimilação.
Utiliza-se uma rede neural recorrente para aprender o processo de assimilação, que por sua vez é treinada a partir dos estados de um sistema dinâmico e de seus resultados de assimilação correspondentes. Tais redes neurais recorrentes são implementadas com o uso de funções de ativação, que introduzem não linearidades às saídas dos neurônios das redes.
Assinale a opção que menos se adequa às características esperadas para funções de ativação.
Utiliza-se uma rede neural recorrente para aprender o processo de assimilação, que por sua vez é treinada a partir dos estados de um sistema dinâmico e de seus resultados de assimilação correspondentes. Tais redes neurais recorrentes são implementadas com o uso de funções de ativação, que introduzem não linearidades às saídas dos neurônios das redes.
Assinale a opção que menos se adequa às características esperadas para funções de ativação.
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518308
Engenharia de Software
As técnicas de aprendizado de máquina aplicadas à assimilação
podem ser utilizadas de diversas maneiras para tratamento de
dados. Um exemplo de processo que pode ser vantajoso para os
algoritmos de assimilação é o de redução da dimensionalidade de
um conjunto de dados, no qual se aplica treinamento não
supervisionado para gerar representações “compactadas” das
entradas originais. Esse processo permite a assimilação de dados no
espaço latente, melhorando a eficiência de treinamento dos
algoritmos.
Determinadas arquiteturas de rede neural são utilizadas para redução de dimensionalidade e para a geração de representações de dados no espaço latente, em que se destaca a arquitetura do tipo
Determinadas arquiteturas de rede neural são utilizadas para redução de dimensionalidade e para a geração de representações de dados no espaço latente, em que se destaca a arquitetura do tipo
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518307
Engenharia de Software
Redes neurais artificiais são elementos fundamentais para o uso de
técnicas de aprendizado de máquina. São constituídas por camadas
de unidades de processamento, chamadas de neurônios.
Relacione os tipos de redes neurais listadas as seguir, às suas principais características.
1. Redes de Propagação Direta (feedforward).
2. Redes Neurais Recorrentes.
3. Redes de Funções de Base Radial.
4. Redes Auto-Organizáveis de Kohonen.
( ) Rede que possui realimentação, de forma que as saídas são direcionadas para as entradas, formando-se um loop.
( ) Rede em que os sinais fluem apenas em uma direção, da entrada para a saída, exceto quando em treinamento.
( ) Rede que é treinada com aprendizado não supervisionado, criando clusters dos dados de entrada.
( ) Rede usada para aproximar funções contínuas a partir de combinações lineares de Gaussianas.
Assinale a opção que indica a relação correta na ordem apresentada.
Relacione os tipos de redes neurais listadas as seguir, às suas principais características.
1. Redes de Propagação Direta (feedforward).
2. Redes Neurais Recorrentes.
3. Redes de Funções de Base Radial.
4. Redes Auto-Organizáveis de Kohonen.
( ) Rede que possui realimentação, de forma que as saídas são direcionadas para as entradas, formando-se um loop.
( ) Rede em que os sinais fluem apenas em uma direção, da entrada para a saída, exceto quando em treinamento.
( ) Rede que é treinada com aprendizado não supervisionado, criando clusters dos dados de entrada.
( ) Rede usada para aproximar funções contínuas a partir de combinações lineares de Gaussianas.
Assinale a opção que indica a relação correta na ordem apresentada.
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518306
Engenharia de Software
Recentemente, tem-se observado o aumento dos usos de algoritmos
de Inteligência Artificial (IA) aplicados à assimilação de dados. Muitos
algoritmos de IA em assimilação são baseados em redes neurais e
redes neurais profundas, que necessitam de uma etapa de
treinamento.
Essas etapas de treinamento nem sempre são de fácil execução. Por exemplo, há um fenômeno que ocorre quando um algoritmo é treinado e apresenta bom desempenho para um conjunto particular de dados usado para treinamento, mas falha ao prever respostas para dados de entrada não incluídos naquele conjunto.
A esse fenômeno dá-se o nome, em inglês, de
Essas etapas de treinamento nem sempre são de fácil execução. Por exemplo, há um fenômeno que ocorre quando um algoritmo é treinado e apresenta bom desempenho para um conjunto particular de dados usado para treinamento, mas falha ao prever respostas para dados de entrada não incluídos naquele conjunto.
A esse fenômeno dá-se o nome, em inglês, de
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518305
Geografia
Modelos de previsão meteorológica utilizados em esquemas de
assimilação variacional como o 4D-VAR são, em geral, não-lineares e
complexos, implementados em grandes quantidades de linhas de
código de software. A implementação dos esquemas pode requerer,
ainda, os cálculos do Modelo Tangente Linear (Tangent Linear Model
- TLM) e do Modelo Adjunto, os quais podem, frequentemente, ser
computados de maneira eficiente.
O conjunto de técnicas utilizadas para computação eficiente dos modelos mencionados constituem ferramentas de
O conjunto de técnicas utilizadas para computação eficiente dos modelos mencionados constituem ferramentas de
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518304
Algoritmos e Estrutura de Dados
Em assimilação variacional, frequentemente são encontrados
problemas inversos mal-postos, (ill-posed problems). Esses
problemas podem ser convertidos em bem-postos (well-posed) pelo
uso de técnicas de regularização. Um exemplo é o uso da
regularização de Tikhonov, em que se adiciona um termo de
regularização a um funcional a ser minimizado, evitando-se assim
instabilidades numéricas durante o cálculo da solução.
Por exemplo: suponha que se busque um vetor x que resolva o sistema Hx = y, minimizando-se o funcional
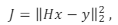
em que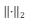 é a norma L2
(isto é, um problema de mínimos
quadrados mal-posto). Pode-se adicionar o termo de regularização
de Tikhonov ao funcional, substituindo-o por
é a norma L2
(isto é, um problema de mínimos
quadrados mal-posto). Pode-se adicionar o termo de regularização
de Tikhonov ao funcional, substituindo-o por
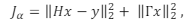
em que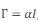 , e I é a matriz identidade.
, e I é a matriz identidade.
Considere um caso hipotético onde as variáveis H, y e α possuem os seguintes valores:
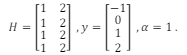
Neste caso, o vetor X que minimiza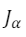 é:
é:
Por exemplo: suponha que se busque um vetor x que resolva o sistema Hx = y, minimizando-se o funcional
em que
é a norma L2
(isto é, um problema de mínimos
quadrados mal-posto). Pode-se adicionar o termo de regularização
de Tikhonov ao funcional, substituindo-o por em que
, e I é a matriz identidade. Considere um caso hipotético onde as variáveis H, y e α possuem os seguintes valores:
Neste caso, o vetor X que minimiza
é:
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518303
Algoritmos e Estrutura de Dados
Relacione os algoritmos de otimização utilizados em assimilação de
dados variacional com suas respectivas características
correspondentes.
1. Método de Newton
2. Broyden-Fletcher-Goldfarb-Shanno (BFGS)
3. Gradiente Conjugado
( ) Determina pontos cada vez mais próximos das soluções dos problemas de otimização mudando a direção de busca a cada iteração.
( ) Requer o cálculo das expressões fechadas dos gradientes e matrizes Hessianas a cada iteração.
( ) Utiliza aproximações de matrizes Hessianas e suas inversas para reduzir a carga computacional a cada iteração.
Assinale a opção que indica a relação correta, segundo a ordem apresentada.
1. Método de Newton
2. Broyden-Fletcher-Goldfarb-Shanno (BFGS)
3. Gradiente Conjugado
( ) Determina pontos cada vez mais próximos das soluções dos problemas de otimização mudando a direção de busca a cada iteração.
( ) Requer o cálculo das expressões fechadas dos gradientes e matrizes Hessianas a cada iteração.
( ) Utiliza aproximações de matrizes Hessianas e suas inversas para reduzir a carga computacional a cada iteração.
Assinale a opção que indica a relação correta, segundo a ordem apresentada.
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518302
Algoritmos e Estrutura de Dados
Métodos de assimilação de dados clássicos são tradicionalmente
classificados em sequenciais ou variacionais. Os métodos
variacionais guardam semelhanças com a teoria de controle ótimo,
por sua vez desenvolvida a partir do estabelecimento dos
fundamentos do cálculo variacional.
Com relação à formulação variacional de assimilação de dados, analise as afirmativas a seguir e assinale (V) para a verdadeira e (F) para a falsa.
( ) Trata-se da busca por estados dos sistemas que minimizam um funcional de custo, em geral definido como um erro quadrático entre observações e predições correspondentes àqueles estados, calculadas por modelos matemáticos.
( ) Envolve a necessidade de aplicação de técnicas de localização e/ou inflação de covariâncias para eliminar correlações espurias entre possíveis soluções de problemas de otimização.
( ) Baseia-se em otimizações com restrições dinâmicas fortes, introduzidas no problema por uso de multiplicadores de Largrange; ou fracas, introduzidas no problema como termos ponderados de penalidades.
As afirmativas são, respectivamente,
Com relação à formulação variacional de assimilação de dados, analise as afirmativas a seguir e assinale (V) para a verdadeira e (F) para a falsa.
( ) Trata-se da busca por estados dos sistemas que minimizam um funcional de custo, em geral definido como um erro quadrático entre observações e predições correspondentes àqueles estados, calculadas por modelos matemáticos.
( ) Envolve a necessidade de aplicação de técnicas de localização e/ou inflação de covariâncias para eliminar correlações espurias entre possíveis soluções de problemas de otimização.
( ) Baseia-se em otimizações com restrições dinâmicas fortes, introduzidas no problema por uso de multiplicadores de Largrange; ou fracas, introduzidas no problema como termos ponderados de penalidades.
As afirmativas são, respectivamente,
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518301
Algoritmos e Estrutura de Dados
O problema de previsão numérica de tempo em escala global é de
altíssima dimensionalidade, envolvendo, por exemplo,
representações de estados com centenas de milhões de variáveis.
Essa alta dimensionalidade impõe grandes dificuldades para a aplicação de filtros de partículas (PF) em problemas de assimilação de dados com muitas observações independentes, porque nessas situações o número de partículas necessárias para representar as distribuições de probabilidade cresce exponencialmente.
Técnicas recentemente desenvolvidas que visam contornar essas dificuldades baseiam-se em combinar filtros de partículas e filtros de Kalman por conjunto (EnKF), criando-se soluções híbridas PF-EnKF.
Assinale a opção que indica a principal vantagem de se utilizar filtros híbridos PF-EnKF.
Essa alta dimensionalidade impõe grandes dificuldades para a aplicação de filtros de partículas (PF) em problemas de assimilação de dados com muitas observações independentes, porque nessas situações o número de partículas necessárias para representar as distribuições de probabilidade cresce exponencialmente.
Técnicas recentemente desenvolvidas que visam contornar essas dificuldades baseiam-se em combinar filtros de partículas e filtros de Kalman por conjunto (EnKF), criando-se soluções híbridas PF-EnKF.
Assinale a opção que indica a principal vantagem de se utilizar filtros híbridos PF-EnKF.
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518300
Algoritmos e Estrutura de Dados
A reamostragem em filtros de partículas pode ser realizada por meio
da criação de novas amostras retiradas das distribuições de
probabilidade discretas correspondentes a conjuntos de partículas e
suas configurações de pesos. No entanto, o fato de as novas
amostras serem criadas exatamente nos mesmos pontos do espaço
em que se localizam as partículas anteriores é inconveniente, pois
facilita o empobrecimento das partículas (i.e., o chamado particle
impoverishment).
Uma forma de produzir um novo conjunto de partículas em pontos distintos é substituir as distribuições discretas de probabilidade por aproximações contínuas e, somente então, realizar a reamostragem. A criação dessas aproximações se dá por meio de uma operação matemática entre a distribuição de probabilidade discreta e um kernel contínuo.
Nesse contexto, o processo de reamostragem em distribuições de probabilidade contínuas, que aproximam distribuições discretas correspondentes às configurações de partículas, é chamado de
Uma forma de produzir um novo conjunto de partículas em pontos distintos é substituir as distribuições discretas de probabilidade por aproximações contínuas e, somente então, realizar a reamostragem. A criação dessas aproximações se dá por meio de uma operação matemática entre a distribuição de probabilidade discreta e um kernel contínuo.
Nesse contexto, o processo de reamostragem em distribuições de probabilidade contínuas, que aproximam distribuições discretas correspondentes às configurações de partículas, é chamado de
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518299
Algoritmos e Estrutura de Dados
Filtros de partículas são, em geral, implementados com o uso de
reamostragem sequencial por importância. Essa reamostragem
pode ser adaptativa, ocorrendo apenas quando a métrica
denominada número efetivo de partículas é considerada muito
baixa.
Considerando um filtro de partículas com N partículas cujos pesos são dados por w(i) ,i = 1, … , N, a estimativa do número efetivo de partículas é dada por
Considerando um filtro de partículas com N partículas cujos pesos são dados por w(i) ,i = 1, … , N, a estimativa do número efetivo de partículas é dada por
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518298
Algoritmos e Estrutura de Dados
Filtros de Partículas são implementações não paramétricas de filtros
Bayesianos em que as distribuições de probabilidade não são
explicitamente definidas, sendo, portanto, representadas por um
conjunto de amostras provenientes delas próprias (denominadas
partículas).
Com relação aos filtros de partículas, analise as afirmativas a seguir e assinale (V) para a verdadeira e (F) para a falsa.
( ) As partículas representam observações (ou medidas) obtidas por sensores aplicados ao sistema em análise, e a elas são associados pesos proporcionais às suas probabilidades de coincidirem com medidas correspondentes ao estado verdadeiro do sistema.
( ) Quando aplicados à assimilação de dados, a cada passo de assimilação, novos pesos são atribuídos às partículas. Caso não seja realizado nenhum processo de reamostragem, o conjunto de partículas costuma degenerar-se, com uma das partículas recebendo peso normalizado próximo de 1 e as outras partículas recebendo pesos normalizados próximos de 0.
( ) São capazes de representar distribuições de probabilidade multimodais, isto é, cujas densidades de probabilidade possuem mais de um máximo local.
As afirmativas são, respectivamente,
Com relação aos filtros de partículas, analise as afirmativas a seguir e assinale (V) para a verdadeira e (F) para a falsa.
( ) As partículas representam observações (ou medidas) obtidas por sensores aplicados ao sistema em análise, e a elas são associados pesos proporcionais às suas probabilidades de coincidirem com medidas correspondentes ao estado verdadeiro do sistema.
( ) Quando aplicados à assimilação de dados, a cada passo de assimilação, novos pesos são atribuídos às partículas. Caso não seja realizado nenhum processo de reamostragem, o conjunto de partículas costuma degenerar-se, com uma das partículas recebendo peso normalizado próximo de 1 e as outras partículas recebendo pesos normalizados próximos de 0.
( ) São capazes de representar distribuições de probabilidade multimodais, isto é, cujas densidades de probabilidade possuem mais de um máximo local.
As afirmativas são, respectivamente,