Questões de Concurso Sobre estatística
Foram encontradas 11.639 questões
Ano: 2022
Banca:
FUNDATEC
Órgão:
AGERGS
Prova:
FUNDATEC - 2022 - AGERGS - Técnico Superior Engenheiro Mecânico |
Q1950422
Estatística
Em Estatística, qual dos seguintes valores NÃO pode representar um coeficiente de
correlação (r)?
Ano: 2022
Banca:
FUNDATEC
Órgão:
AGERGS
Prova:
FUNDATEC - 2022 - AGERGS - Técnico Superior Engenheiro de Dados |
Q1949126
Estatística
Para evitar a polarização dos modelos de aprendizado de máquina, as técnicas de
balanceamento buscam equilibrar a quantidade de instâncias de cada classe do conjunto de dados.
Dentre as diversas técnicas existentes, podemos citar: Seleção aleatória pela menor classe, Seleção
por agrupamento pela menor classe e Replicação de instâncias. Sobre o assunto, analise as assertivas
a seguir:
I. Dado dois conjuntos de registros com N e M registros (onde N<<M) vinculados a duas classes, o balanceamento por seleção aleatória ocorre selecionando de forma aleatória N registros dentro do conjunto contendo M registros.
II. Dado dois conjuntos de registros com N e M registros (onde N<<M) vinculados a duas classes, o balanceamento por seleção de grupo ocorre selecionando por meio de uma técnica de agrupamento os N registros mais representativos dentro do conjunto contendo M registros.
III. Dado dois conjuntos de registros com N e M registros (onde N<<M) vinculados a duas classes, o balanceamento ocorre gerando artificialmente instâncias a partir das instâncias do conjunto contendo M registros (classe maioritária).
Quais estão INCORRETAS?
I. Dado dois conjuntos de registros com N e M registros (onde N<<M) vinculados a duas classes, o balanceamento por seleção aleatória ocorre selecionando de forma aleatória N registros dentro do conjunto contendo M registros.
II. Dado dois conjuntos de registros com N e M registros (onde N<<M) vinculados a duas classes, o balanceamento por seleção de grupo ocorre selecionando por meio de uma técnica de agrupamento os N registros mais representativos dentro do conjunto contendo M registros.
III. Dado dois conjuntos de registros com N e M registros (onde N<<M) vinculados a duas classes, o balanceamento ocorre gerando artificialmente instâncias a partir das instâncias do conjunto contendo M registros (classe maioritária).
Quais estão INCORRETAS?
Ano: 2022
Banca:
FUNDATEC
Órgão:
AGERGS
Prova:
FUNDATEC - 2022 - AGERGS - Técnico Superior Engenheiro de Dados |
Q1949114
Estatística
Sobre os modelos de aprendizagem de máquina supervisionada, analise as assertivas
abaixo e assinale a alternativa correta.
I. Em modelos de aprendizado de máquina do tipo classificação a ideia é prever variáveis categóricas, e numéricas.
II. Um exemplo básico de aprendizado de máquina supervisionado por classificação é o uso da regressão logística.
III. Os modelos de regressão não buscam encontrar como uma variável se comporta na medida em que outra variável sofre oscilações.
IV. Nos modelos de aprendizagem de máquina supervisionado, não temos uma variável específica a ser respondida, pois estamos apenas buscando encontrar os indivíduos, itens ou elementos semelhantes.
I. Em modelos de aprendizado de máquina do tipo classificação a ideia é prever variáveis categóricas, e numéricas.
II. Um exemplo básico de aprendizado de máquina supervisionado por classificação é o uso da regressão logística.
III. Os modelos de regressão não buscam encontrar como uma variável se comporta na medida em que outra variável sofre oscilações.
IV. Nos modelos de aprendizagem de máquina supervisionado, não temos uma variável específica a ser respondida, pois estamos apenas buscando encontrar os indivíduos, itens ou elementos semelhantes.
Ano: 2022
Banca:
FUNDATEC
Órgão:
AGERGS
Prova:
FUNDATEC - 2022 - AGERGS - Técnico Superior Engenheiro de Dados |
Q1949113
Estatística
Antes mesmo de entrar na parte da estatística descritiva, após a coleta dos dados, é
importante saber qual o tipo de dados que irá trabalhar. Em uma pesquisa, foram coletadas as
seguintes variáveis de um total de 200 pessoas:
• Idade.
• Renda.
• Estado Civil.
• Escolaridade.
• Número de Aparelhos de TV na Residência.
• Grau de Satisfação sobre a TV a Cabo (1 – Péssimo a 5 – Ótimo).
A classificação correta dessas seis variáveis é:
• Idade.
• Renda.
• Estado Civil.
• Escolaridade.
• Número de Aparelhos de TV na Residência.
• Grau de Satisfação sobre a TV a Cabo (1 – Péssimo a 5 – Ótimo).
A classificação correta dessas seis variáveis é:
Ano: 2022
Banca:
FUNDATEC
Órgão:
AGERGS
Prova:
FUNDATEC - 2022 - AGERGS - Técnico Superior Engenheiro de Dados |
Q1949112
Estatística
Em uma pesquisa estatística, foi construída uma tabela com o perfil dos pesquisados
a partir das seguintes variáveis: Sexo; raça; cor dos olhos; cor do cabelo; altura; idade (anos); peso;
estado civil; salário mensal (R$); número de dependentes. Considerando as variáveis apresentadas,
assinale a alternativa que apresenta apenas as variáveis qualitativas.
Ano: 2022
Banca:
OBJETIVA
Órgão:
Prefeitura de Arroio do Padre - RS
Prova:
OBJETIVA - 2022 - Prefeitura de Arroio do Padre - RS - Agente Administrativo |
Q1946356
Estatística
Considere o conjunto de valores: {∛8, √225, √0,25, ∛0,125, ∛135}. Qual o valor modal desse conjunto?
Ano: 2022
Banca:
CESPE / CEBRASPE
Órgão:
POLITEC-RO
Prova:
CESPE / CEBRASPE - 2022 - POLITEC - RO - Perito Criminal - Área 1 (Ciência Contábeis/Ciências Econômicas/Adm de Empresas/Adm Pública) |
Q1940376
Estatística
Em relação aos procedimentos técnicos relacionados aos
procedimentos de amostragem, julgue os itens a seguir.
I Quando se adiciona variáveis explicativas no modelo de regressão linear, espera-se o incremento da estatística R2 .
II Ao se comparar modelos com diferentes quantidades de variáveis explicativas, deve-se analisar o valor de R2 ajustado.
III O aumento de variáveis explicativas aumenta o R2 ajustado.
IV Ao se estimar um modelo com quatro variáveis explicativas e compará-lo com um modelo com três variáveis explicativas, escolhe-se o modelo que retornar o maior valor de R2 ajustado, tudo o mais constante.
Estão corretos apenas os itens
I Quando se adiciona variáveis explicativas no modelo de regressão linear, espera-se o incremento da estatística R2 .
II Ao se comparar modelos com diferentes quantidades de variáveis explicativas, deve-se analisar o valor de R2 ajustado.
III O aumento de variáveis explicativas aumenta o R2 ajustado.
IV Ao se estimar um modelo com quatro variáveis explicativas e compará-lo com um modelo com três variáveis explicativas, escolhe-se o modelo que retornar o maior valor de R2 ajustado, tudo o mais constante.
Estão corretos apenas os itens
Ano: 2022
Banca:
FGV
Órgão:
TJ-DFT
Prova:
FGV - 2022 - TJ-DFT - Analista Judiciário - Análise de Dados |
Q1936781
Estatística
Um analista é contratado para analisar dados de volume de suco
de laranja produzido em duas fábricas da mesma empresa.
Suponha que sejam medidos 16 lotes na fábrica A e 61 lotes na fábrica B, e que as médias amostrais tenham sido A_bar = 104 e B_bar = 112, com somas de desvios quadráticos em relação à média S^2_A = 40.000 e S^2_B = 100.000, respectivamente.
A chefia quer saber se uma fábrica tem menor variabilidade em relação à outra.
O teste a ser usado e o valor da sua estatística de teste são, respectivamente:
Suponha que sejam medidos 16 lotes na fábrica A e 61 lotes na fábrica B, e que as médias amostrais tenham sido A_bar = 104 e B_bar = 112, com somas de desvios quadráticos em relação à média S^2_A = 40.000 e S^2_B = 100.000, respectivamente.
A chefia quer saber se uma fábrica tem menor variabilidade em relação à outra.
O teste a ser usado e o valor da sua estatística de teste são, respectivamente:
Ano: 2022
Banca:
FGV
Órgão:
TJ-DFT
Prova:
FGV - 2022 - TJ-DFT - Analista Judiciário - Análise de Dados |
Q1936780
Estatística
Considere um conjunto de dados com n = 10 observações, cujas
nove primeiras observações são
7,6 4,1 8,8 4,2 5,1 7,4 8,8 5,9 3,1
Sabendo-se que a média amostral do conjunto completo é x_bar = 4,2, a amplitude dos dados é:
7,6 4,1 8,8 4,2 5,1 7,4 8,8 5,9 3,1
Sabendo-se que a média amostral do conjunto completo é x_bar = 4,2, a amplitude dos dados é:
Ano: 2022
Banca:
FGV
Órgão:
TJ-DFT
Prova:
FGV - 2022 - TJ-DFT - Analista Judiciário - Análise de Dados |
Q1936779
Estatística
A chance de um evento que ocorre com probabilidade p é
definida como c = p/(1-p).
Quando queremos entender a associação de um fator com um evento de interesse, em geral computamos a razão de chances, r = c_0/c_1, onde c_0 é a chance sem a exposição e c_1 é a chance com a exposição.
Suponha que um analista dispõe de um conjunto de dados binários Y = (Y_1,..., Y_n), com Y_i tomando valores em {0, 1} contendo o resultado de um teste de Covid-19 em n pacientes e que X = (X_1, ..., X_n) é um conjunto de covariáveis também binárias que indicam se o indivíduo foi (X_i = 1) ou não (X_i = 0) a uma festa nos últimos dez dias.
O analista quer determinar se a variável X está significativamente associada com o resultado do teste, Y.
Para tanto, ajusta um modelo de regressão logística utilizando Y como variável resposta, um termo de intercepto e X como covariável.
Ele obtém uma estimativa b0 para o intercepto, com erro padrão s0 e, para o coeficiente de X, uma estimativa b1 erro padrão s1.
O intervalo de confiança de 90% para a razão de chances é:
Quando queremos entender a associação de um fator com um evento de interesse, em geral computamos a razão de chances, r = c_0/c_1, onde c_0 é a chance sem a exposição e c_1 é a chance com a exposição.
Suponha que um analista dispõe de um conjunto de dados binários Y = (Y_1,..., Y_n), com Y_i tomando valores em {0, 1} contendo o resultado de um teste de Covid-19 em n pacientes e que X = (X_1, ..., X_n) é um conjunto de covariáveis também binárias que indicam se o indivíduo foi (X_i = 1) ou não (X_i = 0) a uma festa nos últimos dez dias.
O analista quer determinar se a variável X está significativamente associada com o resultado do teste, Y.
Para tanto, ajusta um modelo de regressão logística utilizando Y como variável resposta, um termo de intercepto e X como covariável.
Ele obtém uma estimativa b0 para o intercepto, com erro padrão s0 e, para o coeficiente de X, uma estimativa b1 erro padrão s1.
O intervalo de confiança de 90% para a razão de chances é:
Ano: 2022
Banca:
FGV
Órgão:
TJ-DFT
Prova:
FGV - 2022 - TJ-DFT - Analista Judiciário - Análise de Dados |
Q1936778
Estatística
Um analista obtém n = 10 estimativas
E = (E_1, E_2, ..., E_10) da quantidade X e deseja avaliar o estimador que as produziu.
Conhecendo o valor verdadeiro de X, ele computa o erro quadrático médio, cujo valor foi 64.
Já a soma das estimativas foi 1.000 e a soma de seus quadrados foi 5.100.
O valor absoluto do viés do estimador é:
E = (E_1, E_2, ..., E_10) da quantidade X e deseja avaliar o estimador que as produziu.
Conhecendo o valor verdadeiro de X, ele computa o erro quadrático médio, cujo valor foi 64.
Já a soma das estimativas foi 1.000 e a soma de seus quadrados foi 5.100.
O valor absoluto do viés do estimador é:
Ano: 2022
Banca:
CESPE / CEBRASPE
Órgão:
PC-PB
Prova:
CESPE / CEBRASPE - 2022 - PC-PB - Necrotomista - Área Enfermagem |
Q1936362
Estatística
Para uma amostra de 100 pacientes, foi verificado que o tempo
médio de permanência em um Hospital foi de 20 dias, com
desvio-padrão de 10 dias. O intervalo de confiança para a média
do tempo de permanência de todos os pacientes do hospital, com
95% de confiança (Z = 1,96) é de
Ano: 2022
Banca:
CESPE / CEBRASPE
Órgão:
PC-PB
Prova:
CESPE / CEBRASPE - 2022 - PC-PB - Necrotomista - Área Enfermagem |
Q1936359
Estatística
Texto associado
Situação hipotética 17A4-I
Um padrão de referência possui concentração de 25 mg/mL da substância X. Um técnico, ao calibrar dois aparelhos que medem a concentração desta substância X, fez medidas durante 5 dias (amostra 1 no dia 1, amostra 2 no dia 2, e assim por diante) e encontrou os seguintes valores.

Considerando os dados obtidos na situação hipotética 17A4-I, os
valores para a média e desvio-padrão dos aparelhos A e B são
Ano: 2022
Banca:
CESPE / CEBRASPE
Órgão:
PC-PB
Prova:
CESPE / CEBRASPE - 2022 - PC-PB - Necrotomista - Área Geral |
Q1936337
Estatística
Um farmacêutico preparou um material de referência para
controle da qualidade de um medicamento. Após preparação
adequada do material, usou como amostra cinco porções do
medicamento e encontrou os seguintes teores de ferro.
Amostras 1 2 3 4
Teor de ferro ( ppm) 118 113 107 102
Considerando o valor de tα/2 igual a 3,182 e α = 0,10, assinale a opção correta para o intervalo de confiança calculado para o teor de ferro no material de referência preparado.
Amostras 1 2 3 4
Teor de ferro ( ppm) 118 113 107 102
Considerando o valor de tα/2 igual a 3,182 e α = 0,10, assinale a opção correta para o intervalo de confiança calculado para o teor de ferro no material de referência preparado.
Q1936142
Estatística
Numa análise de componentes principais, foram calculados os seguintes autovalores para a matriz de correlações:
2,50; 1,25; 0,75; 0,30; 0,20. Com base nesses valores, é correto afirmar:
Q1936141
Estatística
Sobre o uso de técnicas multivariadas na análise de dados, é correto afirmar:
Q1936140
Estatística
Um estudo foi conduzido com o objetivo de avaliar a eficácia de determinada droga no tratamento de um problema
de pele. Para isso, os pacientes que participaram do estudo foram aleatoriamente distribuídos em dois grupos,
sendo o primeiro o grupo controle (não tratado), e o segundo o grupo tratado (que efetivamente recebeu a droga).
Ao término do experimento, foi verificado se os pacientes estavam ou não curados do problema de pele. Seja Yi = 1, caso
o i-ésimo paciente tenha sido curado após o término do experimento, e Yi = 0, caso contrário. Além disso, Xi = 1, caso
o i-ésimo paciente seja do grupo tratado, e Xi = 0, caso seja do grupo controle. A equação apresentada a seguir
representa o modelo de regressão logística ajustado aos dados experimentais:
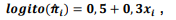
sendo πi = P(Yi = 1|xi). Com base no modelo ajustado, a probabilidade estimada de um paciente do grupo tratado estar curado do problema de pele é igual a:
sendo πi = P(Yi = 1|xi). Com base no modelo ajustado, a probabilidade estimada de um paciente do grupo tratado estar curado do problema de pele é igual a:
Q1936139
Estatística
Sobre a análise de dados de contagens, no contexto de modelos lineares generalizados, é correto afirmar:
Q1936138
Estatística
Um problema frequente na análise de regressão é a presença de multicolinearidade. Nesses casos, as correlações
entre as variáveis independentes causam instabilidade na estimação dos parâmetros, inflacionando os erros das
estimativas. Qual das técnicas apresentadas a seguir é uma alternativa para lidar com multicolinearidade em regressão
linear múltipla?
Q1936137
Estatística
Deseja-se ajustar um modelo de regressão linear para descrever a relação linear entre velocidade do saque (variável
resposta) e altura de tenistas (variável explicativa). No entanto, acredita-se que essa relação mude conforme a idade.
Por isso, além da altura do jogador, será considerada na análise a faixa etária, categorizada em: jovens, adultos e
idosos. O modelo de regressão linear múltipla com efeito de interação entre altura e faixa etária pode ser expresso
como:
y = β0 + β1x1 + ... + βkxk + ∈, ∈ ~ N(0,σ2),
em que x1,...,xk denota as k variáveis a serem inseridas no modelo (eventualmente, resultantes do produto das variáveis originais). Nesse caso, k é igual a:
y = β0 + β1x1 + ... + βkxk + ∈, ∈ ~ N(0,σ2),
em que x1,...,xk denota as k variáveis a serem inseridas no modelo (eventualmente, resultantes do produto das variáveis originais). Nesse caso, k é igual a: