Questões de Concurso Sobre estatística
Foram encontradas 11.902 questões
I II III IV V IV
30 25 40 25 60 2
Assinale a alternativa que expressa a sentença correta.
A amostragem sistemática pode ser considerada um caso específico de amostragem por conglomerados, em que os conglomerados têm tamanhos iguais e duas amostras são selecionadas para observação.
As amostras sistemáticas de tamanho 3 têm as alturas médias 160 cm, 170 cm, 150 cm e 180 cm.
Se o erro amostral tolerável for de 4%, então uma amostra aleatória simples da população de determinada cidade, com 400.000 habitantes, precisa conter mais de 700 pessoas.
A amostra de 400 indivíduos em populações de qualquer tamanho é suficiente se o erro amostral for de 3%.
Em uma população de 8 pessoas — U = {1, ..., 8} —, com pesos —
D = {40, 50, 60, 80, 80, 90, 100, 100} — medidos em quilogramas,
o peso médio da amostra é igual a 75 kg. A população foi dividida
nos estratos UA ={1, 2, 3} e UB ={4, 5, 6, 7, 8}, com pesos
DA ={40, 50, 60} e DB ={80, 80, 90, 100, 100}, em que as
variâncias desses estratos são  e
e  , respectivamente.
, respectivamente.
A média das variâncias dos estratos (variância dentro) é igual a 75/2 .
Em uma população de 8 pessoas — U = {1, ..., 8} —, com pesos —
D = {40, 50, 60, 80, 80, 90, 100, 100} — medidos em quilogramas,
o peso médio da amostra é igual a 75 kg. A população foi dividida
nos estratos UA ={1, 2, 3} e UB ={4, 5, 6, 7, 8}, com pesos
DA ={40, 50, 60} e DB ={80, 80, 90, 100, 100}, em que as
variâncias desses estratos são e , respectivamente.
Uma estimativa não viciada para o peso médio populacional é
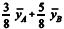 e sua variância é igual a 1.300/64 .
e sua variância é igual a 1.300/64 .Em uma população de 8 pessoas — U = {1, ..., 8} —, com pesos —
D = {40, 50, 60, 80, 80, 90, 100, 100} — medidos em quilogramas,
o peso médio da amostra é igual a 75 kg. A população foi dividida
nos estratos UA ={1, 2, 3} e UB ={4, 5, 6, 7, 8}, com pesos
DA ={40, 50, 60} e DB ={80, 80, 90, 100, 100}, em que as
variâncias desses estratos são e , respectivamente.
Se, em cada estrato, for escolhida, aleatoriamente, uma amostra de tamanho 2, então as variâncias das médias amostrais serão
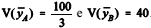 .
.Em uma população de 8 pessoas — U = {1, ..., 8} —, com pesos —
D = {40, 50, 60, 80, 80, 90, 100, 100} — medidos em quilogramas,
o peso médio da amostra é igual a 75 kg. A população foi dividida
nos estratos UA ={1, 2, 3} e UB ={4, 5, 6, 7, 8}, com pesos
DA ={40, 50, 60} e DB ={80, 80, 90, 100, 100}, em que as
variâncias desses estratos são e , respectivamente.
A variância das médias dos estratos (variância entre estratos) é igual a 375.
A variável fi segue uma distribuição de Bernoulli, isto é, P(fi = 1) = n/N e P(fi = 0) = 1 - n/N .
A probabilidade de que a amostra contenha os elementos 1, 2 e 3 é igual a
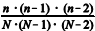 .
.A variância da variável aleatória fi é igual a 1/N × (1 - n/N ).
O valor esperado da variável aleatória fi é igual a n/N.
Toda variável aleatória fi é binomialmente distribuída com valor esperado n/N.
Se N = 10 e n = 5, então a probabilidade de que a amostra contenha uma vez o elemento 2, duas vezes o elemento 5 e duas vezes o elemento 8 é igual a 0,0003.
Se N = 100 e n = 10, então a probabilidade de que a amostra contenha os elementos 1 e 2 pode ser corretamente expressa por 1 - 0,9910 + 0,9810.