Questões de Concurso
Sobre inteligencia artificial em engenharia de software
Foram encontradas 426 questões
Uma maneira de mitigar esse comportamento inconveniente é usar técnicas de
A respeito da PCA, avalie as afirmativas a seguir.
I. As componentes principais equivalem às direções resultantes do cálculo dos autovetores da matriz de covariâncias dos dados normalizados, selecionando-se aqueles autovetores associados aos menores autovalores, até um limite definido pelo analista.
II. As componentes principais equivalem, em geral, a combinações lineares das características originais do conjunto de dados.
III. A maior vantagem da PCA é a manutenção total das informações do conjunto de dados original, sem ocorrência de perdas decorrentes de projeções dos dados sobre as componentes principais.
Está correto o que se afirma em
Assinale a técnica de classificação que melhor se enquadra nas características descritas acima.
Com a combinação de IA e bancos de dados em memória, o Comitê espera melhorar a eficiência na análise de grandes volumes de dados e fornecer insights personalizados para cada atleta, otimizando o treinamento e a performance nas competições.
Diante desse cenário, sobre o impacto da IA aplicada a bancos de dados em memória, assinale a opção incorreta.
Considere um cenário em que uma sequência de vendas de um produto permanece constante durante uma promoção que normalmente gera picos de vendas, retornando aos patamares normais ao final da promoção.
Nessas condições, o tipo de outlier observado nessa sequência de vendas é o
A Inteligência Artificial (IA) tem transformado diversos setores da economia e sociedade, possibilitando a automação de tarefas complexas, a análise de grandes volumes de dados e a tomada de decisões mais rápidas e precisas. Modelos de aprendizado de máquina (machine learning) e redes neurais são algumas das principais tecnologias que impulsionam a IA, permitindo que sistemas sejam treinados para identificar padrões, prever comportamentos e melhorar suas capacidades com base em novas informações. O avanço da IA, combinado com outras inovações tecnológicas como a computação em nuvem e a internet das coisas (IoT), está moldando o futuro de indústrias como saúde, transporte e finanças.
Julgue o item a seguir, a respeito do texto acima:
A Inteligência Artificial (IA) tem transformado diversos setores da economia e sociedade, possibilitando a automação de tarefas complexas, a análise de grandes volumes de dados e a tomada de decisões mais rápidas e precisas. Modelos de aprendizado de máquina (machine learning) e redes neurais são algumas das principais tecnologias que impulsionam a IA, permitindo que sistemas sejam treinados para identificar padrões, prever comportamentos e melhorar suas capacidades com base em novas informações. O avanço da IA, combinado com outras inovações tecnológicas como a computação em nuvem e a internet das coisas (IoT), está moldando o futuro de indústrias como saúde, transporte e finanças.
Julgue o item a seguir, a respeito do texto acima:
A Inteligência Artificial (IA) tem transformado diversos setores da economia e sociedade, possibilitando a automação de tarefas complexas, a análise de grandes volumes de dados e a tomada de decisões mais rápidas e precisas. Modelos de aprendizado de máquina (machine learning) e redes neurais são algumas das principais tecnologias que impulsionam a IA, permitindo que sistemas sejam treinados para identificar padrões, prever comportamentos e melhorar suas capacidades com base em novas informações. O avanço da IA, combinado com outras inovações tecnológicas como a computação em nuvem e a internet das coisas (IoT), está moldando o futuro de indústrias como saúde, transporte e finanças.
Julgue o item a seguir, a respeito do texto acima:
A Inteligência Artificial (IA) tem transformado diversos setores da economia e sociedade, possibilitando a automação de tarefas complexas, a análise de grandes volumes de dados e a tomada de decisões mais rápidas e precisas. Modelos de aprendizado de máquina (machine learning) e redes neurais são algumas das principais tecnologias que impulsionam a IA, permitindo que sistemas sejam treinados para identificar padrões, prever comportamentos e melhorar suas capacidades com base em novas informações. O avanço da IA, combinado com outras inovações tecnológicas como a computação em nuvem e a internet das coisas (IoT), está moldando o futuro de indústrias como saúde, transporte e finanças.
Julgue o item a seguir, a respeito do texto acima:
A Inteligência Artificial (IA) tem transformado diversos setores da economia e sociedade, possibilitando a automação de tarefas complexas, a análise de grandes volumes de dados e a tomada de decisões mais rápidas e precisas. Modelos de aprendizado de máquina (machine learning) e redes neurais são algumas das principais tecnologias que impulsionam a IA, permitindo que sistemas sejam treinados para identificar padrões, prever comportamentos e melhorar suas capacidades com base em novas informações. O avanço da IA, combinado com outras inovações tecnológicas como a computação em nuvem e a internet das coisas (IoT), está moldando o futuro de indústrias como saúde, transporte e finanças.
Julgue o item a seguir, a respeito do texto acima:
Em relação ao ajuste e validação de modelos em aprendizado de máquina, um modelo sofre overfitting quando
O conceito que está mais diretamente relacionado ao desenvolvimento de sistemas que aprendem com os dados e melhoram seu desempenho ao longo do tempo é o de
A técnica apropriada na otimização de hiperparâmetros para um modelo de aprendizado supervisionado, considerando tanto a eficiência quanto a eficácia é a
Na redução de dimensionalidade em PLN, a técnica utilizada é chamada
Assinale a opção que descreve corretamente uma diferença fundamental entre técnicas de agrupamento e técnicas de classificação.
Redes Neurais Artificiais são técnicas computacionais que utilizam um modelo matemático inspirado no neurônio biológico, obtendo aprendizado pela experiência. Encontra aplicações em visão computacional, automação residencial e industrial, robótica, microeletrônica, entre outros. A respeito de redes neurais MLP (Multi-layer Perceptron), analise as afirmativas:
I. Os parâmetros a serem definidos para a execução de uma rede MLP são número de camadas, número de neurônios em cada camada, taxa de aprendizado e função de ativação;
II. São redes recorrentes;
III. Os neurônios da camada oculta são capazes de capturar a não-linearidade dos dados;
IV. Geralmente utiliza-se a função sigmóide como função de ativação nas camadas oculta e de saída.
As afirmativas corretas são:
Considerando-se esse contexto, qual é a característica da técnica RAG?
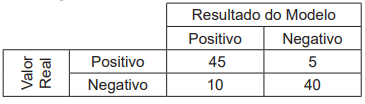
Considerando-se esse contexto, quais são, respectivamente, os valores aproximados, em 2 casas decimais, da precisão (precision) e da revocação (recall) obtidos pelo modelo?
Considere as seguintes afirmativas com relação à mitigação dos riscos identificados:
I - adotar uma abordagem de fairness-aware learning para corrigir potenciais vieses no modelo, garantindo que as recomendações sejam justas para todos os grupos de usuários.
II - implementar métodos de robustness testing para simular ataques adversariais e avaliar a resiliência do modelo, e realizar auditorias regulares para identificar e corrigir vieses algorítmicos.
III - implementar técnicas de data augmentation para aumentar a diversidade dos dados de treinamento, reduzindo o risco de viés algorítmico, e adotar uma estratégia de monitoramento contínuo para detectar e mitigar ataques adversariais.
IV - utilizar técnicas de differential privacy durante o treinamento do modelo para proteger dados sensíveis e garantir que as previsões do modelo não revelem informações específicas dos clientes.
Estão corretas as seguintes afirmativas: