Questões de Concurso Sobre engenharia de software
Foram encontradas 12.444 questões
Ano: 2024
Banca:
FGV
Órgão:
TCE-GO
Prova:
FGV - 2024 - TCE-GO - Analista de Controle Externo - Tecnologia da Informação |
Q2524541
Engenharia de Software
Os diagramas de classe e diagramas de objetos da UML 2.5 são
elementos importantes na modelagem de sistemas orientados a
objetos. Ambos desempenham papéis distintos na visualização e
representação das estruturas e interações dentro de um sistema.
Assinale a opção que descreve corretamente as diferenças entre o diagrama de classe e o diagrama de objetos na UML 2.5.
Assinale a opção que descreve corretamente as diferenças entre o diagrama de classe e o diagrama de objetos na UML 2.5.
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Especificação, Projeto e Arquitetura de Sistemas de Software para o Processamento e Distribuição de Imagens de Sensoriamento Remoto |
Q2524057
Engenharia de Software
As chamadas metodologias ágeis, apesar de compartilharem os
mesmos fundamentos, possuem procedimentos particulares.
Assinale a opção que indica a metodologia ágil que se caracteriza por organizar programadores em pares e focar na refatoração frequente.
Assinale a opção que indica a metodologia ágil que se caracteriza por organizar programadores em pares e focar na refatoração frequente.
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento de Software e Sistemas para Área de Geoinformática |
Q2524000
Engenharia de Software
No contexto do processamento digital de imagens, o processo de
filtragem modifica a imagem pixel a pixel, sob influência do pixel de
referência e dos pixels vizinhos.
Assinale a opção que indica um dos objetivos para o qual o filtro pode ser aplicado.
Assinale a opção que indica um dos objetivos para o qual o filtro pode ser aplicado.
Ano: 2024
Banca:
Quadrix
Órgão:
CRMV-SE
Provas:
Quadrix - 2024 - CRMV-SE - Advogado
|
Quadrix - 2024 - CRMV-SE - Contador |
Q2522694
Engenharia de Software
Texto associado
Nas questões que avaliem conhecimentos de informática,
a menos que seja explicitamente informado o contrário,
considere que: todos os programas mencionados estejam
em configuração‑padrão, em português; o mouse esteja
configurado para pessoas destras; expressões como
clicar, clique simples e clique duplo refiram‑se a cliques
com o botão esquerdo do mouse; e teclar corresponda à
operação de pressionar uma tecla e, rapidamente, liberá‑la,
acionando‑a apenas uma vez. Considere também que não
haja restrições de proteção, de funcionamento e de uso
em relação aos programas, arquivos, diretórios, recursos e
equipamentos mencionados.
Assinale a alternativa que apresenta a principal diferença
entre aprendizado supervisionado e aprendizado não
supervisionado em aprendizado de máquina.
Ano: 2024
Banca:
Qconcursos
Órgão:
Qconcursos
Prova:
Qconcursos - 2024 - Qconcursos - Simulado Ilimitada - 2° Simulado |
Q2522626
Engenharia de Software
[Questão Inédita] A metodologia ágil é uma abordagem de gestão de projetos que se
destaca por sua flexibilidade e adaptabilidade às mudanças durante o
desenvolvimento do projeto. Entre as diversas metodologias ágeis, uma das
mais conhecidas e utilizadas é o Scrum. Considerando o framework Scrum,
qual das seguintes afirmativas está INCORRETA?
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Processamento de Alto Desempenho – PAD (HPC) |
Q2519095
Engenharia de Software
Relacione as terminologias referentes ao Git, listadas a seguir, às suas respectivas definições.
1. Fetch
2. Branch
3. Issue
4. Commit
( ) Permite adicionar alterações do repositório remoto à sua ramificação de trabalho local, sem confirmá-las.
( ) Está contido no repositório, mas é uma versão paralela do mesmo, não afetando a ramificação principal e permitindo trabalhar livremente sem interromper a versão "live".
( ) É uma alteração individual em um ou mais arquivos. Quando usado para salvar um trabalho, o Git gera um ID único que permite registrar as alterações confirmadas assim como quem as fez e quando.
( ) É uma sugestão de melhoria, tarefa ou dúvida relacionada ao repositório. Pode ser criado por qualquer pessoa (em repositórios públicos), bem como ser categorizado com rótulos e atribuído a colaboradores.
Assinale a opção que indica a relação correta, segundo a ordem apresentada.
Assinale a opção que indica a relação correta, segundo a ordem apresentada.
1. Fetch
2. Branch
3. Issue
4. Commit
( ) Permite adicionar alterações do repositório remoto à sua ramificação de trabalho local, sem confirmá-las.
( ) Está contido no repositório, mas é uma versão paralela do mesmo, não afetando a ramificação principal e permitindo trabalhar livremente sem interromper a versão "live".
( ) É uma alteração individual em um ou mais arquivos. Quando usado para salvar um trabalho, o Git gera um ID único que permite registrar as alterações confirmadas assim como quem as fez e quando.
( ) É uma sugestão de melhoria, tarefa ou dúvida relacionada ao repositório. Pode ser criado por qualquer pessoa (em repositórios públicos), bem como ser categorizado com rótulos e atribuído a colaboradores.
Assinale a opção que indica a relação correta, segundo a ordem apresentada.
Assinale a opção que indica a relação correta, segundo a ordem apresentada.
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Processamento de Alto Desempenho – PAD (HPC) |
Q2519084
Engenharia de Software
A respeito da gestão de projetos que emprega metodologias ágeis, assinale a afirmativa correta.
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Processamento de Alto Desempenho – PAD (HPC) |
Q2519083
Engenharia de Software
Acerca de metodologias ágeis, assinale a afirmativa correta.
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518308
Engenharia de Software
As técnicas de aprendizado de máquina aplicadas à assimilação
podem ser utilizadas de diversas maneiras para tratamento de
dados. Um exemplo de processo que pode ser vantajoso para os
algoritmos de assimilação é o de redução da dimensionalidade de
um conjunto de dados, no qual se aplica treinamento não
supervisionado para gerar representações “compactadas” das
entradas originais. Esse processo permite a assimilação de dados no
espaço latente, melhorando a eficiência de treinamento dos
algoritmos.
Determinadas arquiteturas de rede neural são utilizadas para redução de dimensionalidade e para a geração de representações de dados no espaço latente, em que se destaca a arquitetura do tipo
Determinadas arquiteturas de rede neural são utilizadas para redução de dimensionalidade e para a geração de representações de dados no espaço latente, em que se destaca a arquitetura do tipo
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518307
Engenharia de Software
Redes neurais artificiais são elementos fundamentais para o uso de
técnicas de aprendizado de máquina. São constituídas por camadas
de unidades de processamento, chamadas de neurônios.
Relacione os tipos de redes neurais listadas as seguir, às suas principais características.
1. Redes de Propagação Direta (feedforward).
2. Redes Neurais Recorrentes.
3. Redes de Funções de Base Radial.
4. Redes Auto-Organizáveis de Kohonen.
( ) Rede que possui realimentação, de forma que as saídas são direcionadas para as entradas, formando-se um loop.
( ) Rede em que os sinais fluem apenas em uma direção, da entrada para a saída, exceto quando em treinamento.
( ) Rede que é treinada com aprendizado não supervisionado, criando clusters dos dados de entrada.
( ) Rede usada para aproximar funções contínuas a partir de combinações lineares de Gaussianas.
Assinale a opção que indica a relação correta na ordem apresentada.
Relacione os tipos de redes neurais listadas as seguir, às suas principais características.
1. Redes de Propagação Direta (feedforward).
2. Redes Neurais Recorrentes.
3. Redes de Funções de Base Radial.
4. Redes Auto-Organizáveis de Kohonen.
( ) Rede que possui realimentação, de forma que as saídas são direcionadas para as entradas, formando-se um loop.
( ) Rede em que os sinais fluem apenas em uma direção, da entrada para a saída, exceto quando em treinamento.
( ) Rede que é treinada com aprendizado não supervisionado, criando clusters dos dados de entrada.
( ) Rede usada para aproximar funções contínuas a partir de combinações lineares de Gaussianas.
Assinale a opção que indica a relação correta na ordem apresentada.
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518306
Engenharia de Software
Recentemente, tem-se observado o aumento dos usos de algoritmos
de Inteligência Artificial (IA) aplicados à assimilação de dados. Muitos
algoritmos de IA em assimilação são baseados em redes neurais e
redes neurais profundas, que necessitam de uma etapa de
treinamento.
Essas etapas de treinamento nem sempre são de fácil execução. Por exemplo, há um fenômeno que ocorre quando um algoritmo é treinado e apresenta bom desempenho para um conjunto particular de dados usado para treinamento, mas falha ao prever respostas para dados de entrada não incluídos naquele conjunto.
A esse fenômeno dá-se o nome, em inglês, de
Essas etapas de treinamento nem sempre são de fácil execução. Por exemplo, há um fenômeno que ocorre quando um algoritmo é treinado e apresenta bom desempenho para um conjunto particular de dados usado para treinamento, mas falha ao prever respostas para dados de entrada não incluídos naquele conjunto.
A esse fenômeno dá-se o nome, em inglês, de
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 8 - TI / Sistemas e Desenvolvimento - Tarde |
Q2518092
Engenharia de Software
A fase de testes de software em processos ágeis se caracteriza
pela elaboração dos testes antes da implementação do código,
permitindo a execução do teste enquanto o código está sendo
escrito.
A característica do XP que tem como fundamento esse conceito de teste é o:
A característica do XP que tem como fundamento esse conceito de teste é o:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 8 - TI / Sistemas e Desenvolvimento - Tarde |
Q2518083
Engenharia de Software
Maria está desenvolvendo um aplicativo desktop, com base em
um ambiente de janelas, e precisa que alguns processos sejam
disponibilizados de forma global no aplicativo, sem a necessidade
de instanciar um objeto específico, e de forma que qualquer
entidade possa acessar.
Por estar trabalhando dentro da metodologia orientada a objetos, Maria precisará adicionar aos métodos globais os modificadores:
Por estar trabalhando dentro da metodologia orientada a objetos, Maria precisará adicionar aos métodos globais os modificadores:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 8 - TI / Sistemas e Desenvolvimento - Tarde |
Q2518074
Engenharia de Software
Os padrões de projeto são extremamente úteis para organizar a
arquitetura do sistema e o modelo de programação. Eles são
projetados em diagramas da UML, como no modelo a seguir.
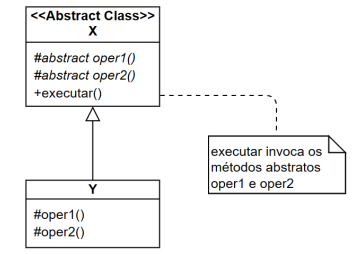
O diagrama expressa o padrão de projeto:
O diagrama expressa o padrão de projeto:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 8 - TI / Sistemas e Desenvolvimento - Tarde |
Q2518073
Engenharia de Software
Ana está desenvolvendo o novo aplicativo da sua empresa e quer
garantir um melhor nível de usabilidade para o produto.
Como se trata de uma empresa voltada para a terceira idade, Ana irá precisar de alguns cuidados a mais, entre eles:
Como se trata de uma empresa voltada para a terceira idade, Ana irá precisar de alguns cuidados a mais, entre eles:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 8 - TI / Sistemas e Desenvolvimento - Tarde |
Q2518072
Engenharia de Software
João foi direcionado, pela consultoria na qual trabalha, para um
novo cliente, a fim de iniciar a elicitação de requisitos. Após
analisar alguns documentos e entrevistar alguns gestores, ele
resolveu utilizar a técnica de card sorting, na qual contará com a
participação de um grupo de 15 usuários. Após a utilização da
técnica, João observou que o card sorting:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 8 - TI / Sistemas e Desenvolvimento - Tarde |
Q2518071
Engenharia de Software
As metodologias ágeis surgiram com o intuito de oferecer com
maior rapidez produtos consistentes e que agregam valor, por
meio de entregas parciais em períodos curtos. Em termos de
Scrum e XP, existem diversas regras e eventos que objetivam essa
otimização de entregas, como:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 8 - TI / Sistemas e Desenvolvimento - Tarde |
Q2518059
Engenharia de Software
O analista José desenvolveu a aplicação CVMapaB observando a
arquitetura hexagonal. Para a interação com o usuário, a
CVMapaB disponibiliza uma interface gráfica de usuário e uma
interface de linha de comando, a cvmapb, com ambas as
interfaces capazes de realizar as mesmas operações. A aplicação
também disponibiliza uma Application Programming
Interface (API) web RESTful, capaz de realizar parte das operações
disponíveis na cvmapb. A CVMapaB utiliza o sistema gerenciador
de banco de dados da CVM para persistir os dados do usuário. A
aplicação possui, ainda, implementações específicas para a
publicação de métricas de desempenho. As métricas são
remetidas pela CVMapaB ao pipeline de processamento de dados
em tempo real da CVM.
Com base no enunciado e à luz da arquitetura hexagonal, são identificáveis na CVMapaB:
Com base no enunciado e à luz da arquitetura hexagonal, são identificáveis na CVMapaB:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 8 - TI / Sistemas e Desenvolvimento - Tarde |
Q2518058
Engenharia de Software
Maurício é o líder técnico do Time de Tecnologia da Informação
(TTI) de uma organização que está iniciando o uso do estilo de
Desenvolvimento Orientado a Testes (TDD).
De forma a nivelar o conhecimento e obedecendo ao estilo TDD, Maurício orientou que os(as):
De forma a nivelar o conhecimento e obedecendo ao estilo TDD, Maurício orientou que os(as):
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 8 - TI / Sistemas e Desenvolvimento - Tarde |
Q2518057
Engenharia de Software
A Equipe de Desenvolvimento de Soluções de Software (EDSS)
recebeu a demanda de desenvolvimento de um software
complexo e, por isso, pretende utilizar a abordagem Domain
Driven Design (DDD).
Com foco no modelo de domínio principal, a EDSS assumirá que:
Com foco no modelo de domínio principal, a EDSS assumirá que: