Questões de Concurso Público IPEA 2024 para Técnico de Planejamento e Pesquisa - Políticas Públicas e Avaliação
Foram encontradas 70 questões
Equação I
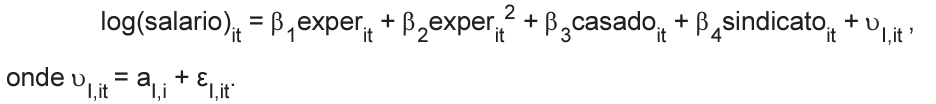
O p-valor do Teste de Hausman obtido é igual a 0,001.
Equação II
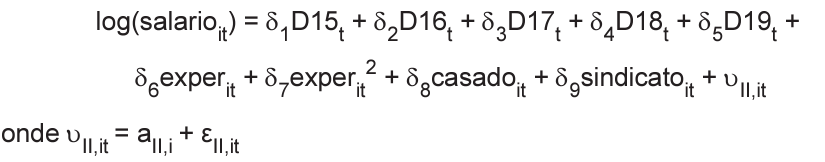
O p-valor do Teste de Hausman obtido é igual a 0,265.
A base de dados é composta pelas seguintes variáveis:
• salario = salário real; • exper = anos de experiência profissional;
• casado = variável dummy igual a 1 se casado e 0 caso contrário;
• sindicato = variável dummy igual a 1 se sindicalizado e 0 caso contrário; • D15,D16,D17,D18 e D19 são os efeitos fixos de cada ano no tempo;
• aI,i e aII,i são os efeitos fixos não observados associados aos trabalhadores das Equações I e II, respectivamente;
• εI,it e εII,it são os termos de erro das Equações I e II, respectivamente.
Com base nos resultados dos Testes de Hausman e considerando o nível de significância a 5%, conclui-se que os coeficientes
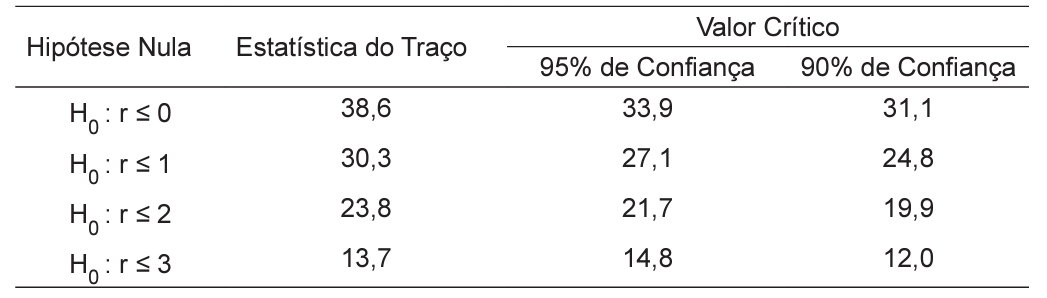
Qual é o número de vetores de cointegração sugerido pelo teste acima para os níveis de 5% e 10% de significância, respectivamente?
O modelo de Regressão com Descontinuidade (RDD) é uma técnica estatística usada para avaliar o impacto causal de uma variável independente em uma variável dependente, quando essa variável independente ultrapassa um certo limite ou ponto de corte.
Suponha que se esteja investigando o efeito do número de horas de estudo (variável independente) no desempenho em um teste (variável dependente). Assumindo-se que haja um ponto de corte de 5 horas de estudo e que se deseje verificar se há algum efeito no resultado do teste ao se ultrapassar esse ponto de corte.
A equação para esse modelo pode ser expressa da seguinte forma:
Yi = 60 + 5Xi + 8Di + ϵi ,
onde
• Yi é o desempenho no teste para o indivíduo i;
• Xi é o número de horas de estudo para o indivíduo i;
• Di é uma variável indicadora que vale 1 se Xi > 5 horas e 0 caso contrário para o indivíduo i;
• ϵi é o termo de erro para o indivíduo i.
Ao se comparar um estudante que estuda 6 horas para um teste com um outro que estuda 4 horas, de acordo com o modelo RDD apresentado acima, verifica-se que o
Yt = 3 + 0,5Yt-1 + ut ,
onde E(ut) =0 e Var(ut) = 6. Assuma, também, que ut e Yt-1 são independentes.
Nesse cenário, qual é a variância de Yt?
• taxa de desemprego do País Z em 2016 = 7%;
• taxa de desemprego do País Z em 2018 = 5%;
• taxas de desemprego das Unidades de Controle (Países P, Q, R, S, T) em 2016 = variando de 6% a 8%;
• taxas de desemprego das Unidades de Controle (Países P, Q, R, S, T) em 2018 = variando de 4% a 6%;
• taxa de desemprego sintética do País Z em 2016 = 6,5%;
• taxa de desemprego prevista para o controle sintético em 2018: 6%.
Nessa situação, qual foi o efeito estimado da política sobre a taxa de desemprego do País Z no ano seguinte à implementação da política de redução do seguro-desemprego?
Se um intervalo de confiança de 95% for construído para estimar a verdadeira média de horas semanais estudadas pelos estudantes universitários, qual intervalo é o mais apropriado?
Considere o seguinte sistema de equações, em suas respectivas formas estruturais:
qd = α1p +α2z + α3y + ε1 (demanda)
qs = β1p + ε2 (oferta)
qd = qs (equilíbrio),
onde qd é a quantidade demandada de um bem; qs é a quantidade ofertada do mesmo bem; p é o preço do bem; z e y são variáveis explicativas exógenas; ε1 e ε2 são os termos de erro das funções de demanda e oferta, respectivamente; α1 , α2 , α3 e β1 são coeficientes de inclinação.
Nesse contexto, no sistema de determinação da oferta e demanda,
Estrato 1 (1º ao 5º ano): 600 estudantes
Estrato 2 (6º ao 9º ano): 900 estudantes
Estrato 3 (Ensino Médio): 500 estudantes
Uma amostra de 80 estudantes será selecionada para um estudo.
Para garantir uma representatividade proporcional de cada estrato na amostra, quantos estudantes devem ser selecionados de cada estrato?
Tal variável mediadora é a(o)
Considere que a análise DAG foi utilizada para auxiliar na definição das restrições na identificação de um modelo VAR estrutural (SVAR) aplicado à política monetária. O modelo é constituído a partir das seguintes variáveis: Taxa Selic, PIB, câmbio nominal e taxa de inflação. Considere o DAG abaixo.
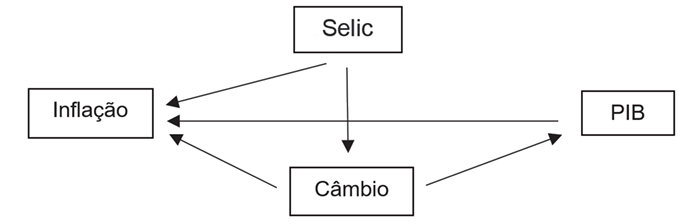
Nesse contexto, verifica-se que
Seja o seguinte processo dinâmico caracterizado pela descontinuidade no tempo:

em que t é a unidade de tempo e εt é o termo de erro independente e identicamente distribuído com média igual a 0 e variância constante.
Sendo assim, qual é o valor esperado para t = 3, isto é, E[Y3 ]?
Os modelos dinâmicos de dados em painel envolvem tanto dados de séries temporais quanto de seção transversal. Esses modelos frequentemente incorporam variáveis dependentes defasadas e regressores endógenos, o que pode levar a problemas de endogeneidade.
O modelo GMM aborda problemas de endogeneidade e autocorrelação em modelos dinâmicos de dados em painel. Ele faz isso utilizando variáveis instrumentais (IVs) e explorando a estrutura dos dados, para criar condições de momento que auxiliam na estimativa consistente de parâmetros.
Um dos principais testes usados para avaliar a adequação do modelo é o teste de Sargan-Hansen.
O teste de Sargan-Hansen
Essa metodologia é composta pelas seguintes etapas:
P - Estimação
Q - Diagnóstico
R - Previsão
S - Identificação
Segundo essa metodologia, a sequência das etapas, da primeira para a última, para explicar a dinâmica de uma série temporal é:
No Texto para Discussão do Ipea, é apresentada a seguinte Tabela que sumariza o resultado do teste de causalidade de Granger entre duas variáveis: Expectativa de Dívida Líquida do Setor Público (EDLSP) e a diferença da Expectativa de Superávit Primário (dESP), em que d representa a primeira diferença da série, entre janeiro de 2001 e junho de 2006.
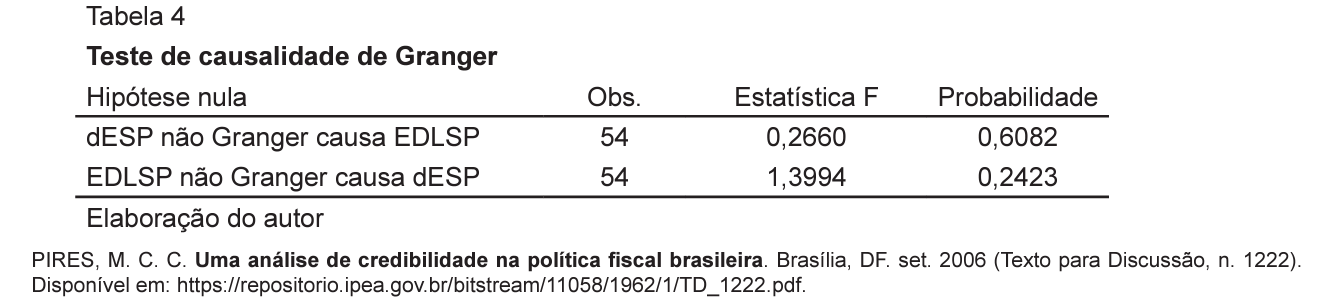
As informações da Tabela permitem inferir o seguinte resultado:
As formas mais utilizadas para testar a existência de cointegração entre as séries são:
Nesse contexto, as principais metodologias utilizadas para a previsão de séries econômicas estacionárias, considerando-se a utilização de uma única série temporal ou de diversas séries temporais, são as seguintes:
Yi = β1 + β2Xi + β3X2i + β4 X3i + u1i , modelo explicativo 0, onde Y é a variável dependente; X, a variável explicativa; β1 , β2 , β3 e β4 , os coeficientes da regressão; u, o termo de erro, e o subscrito i indica a i-ésima observação.
No entanto, considere que, por diversos motivos, o pesquisador decida estimar outros modelos (equações 1, 2, 3 e 4), cujas notações foram alteradas para distingui-los do modelo explicativo verdadeiro (modelo explicativo 0):
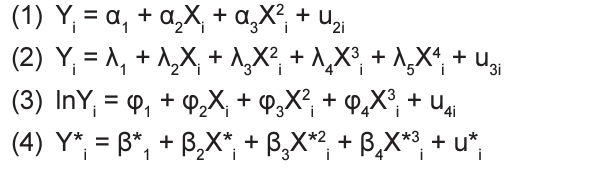
Essa decisão poderia levar a erros de especificação, já que os modelos 1, 2, 3 e 4 são diferentes do modelo explicativo verdadeiro (modelo equação 0), o que permite concluir que
Sobre esses testes considere as afirmativas abaixo.
I - O teste de Hansen investiga a exogeneidade dos instrumentos e a sua hipótese nula é que o modelo é corretamente especificado e os instrumentos em conjunto são válidos.
II - O teste Arellano-Bond AR (2) testa a autocorrelação serial, para o qual se deve rejeitar a hipótese nula de ausência de correlação serial de primeira e segunda ordem no termo de erro.
III - O teste Arellano-Bond AR (2) testa a autocorrelação serial, sob hipótese nula de ausência de correlação serial de segunda ordem no termo de erro.
Está correto o que se afirma em
Nesses modelos,