Questões de Concurso Público INSS 2008 para Analista do Seguro Social - Estatística
Foram encontradas 147 questões
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409130
Estatística
Texto associado

O quadro acima apresenta uma tábua abreviada de mortalidade para determinada população, obtida a partir de um censo demográfico realizado em 2007. As duas primeiras colunas dessa tabela definem o início e o comprimento do intervalo de tempo dos grupos etários (terceira coluna). A probabilidade Q(X, N) é a estimativa do risco de morte de um indivíduo pertencente ao grupo etário (X, X + N). Com base nas informações apresentadas no texto e considerando-se que o número de sobreviventes à idade exata X = 0 foi igual a 100.000, julgue o item subseqüente.
O quadro acima apresenta uma tábua abreviada de mortalidade para determinada população, obtida a partir de um censo demográfico realizado em 2007. As duas primeiras colunas dessa tabela definem o início e o comprimento do intervalo de tempo dos grupos etários (terceira coluna). A probabilidade Q(X, N) é a estimativa do risco de morte de um indivíduo pertencente ao grupo etário (X, X + N). Com base nas informações apresentadas no texto e considerando-se que o número de sobreviventes à idade exata X = 0 foi igual a 100.000, julgue o item subseqüente.
Em 2007, a expectativa de vida ao nascer é superior a 70 anos e inferior a 70,5 anos.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409131
Estatística
Texto associado
O quadro acima apresenta uma tábua abreviada de mortalidade para determinada população, obtida a partir de um censo demográfico realizado em 2007. As duas primeiras colunas dessa tabela definem o início e o comprimento do intervalo de tempo dos grupos etários (terceira coluna). A probabilidade Q(X, N) é a estimativa do risco de morte de um indivíduo pertencente ao grupo etário (X, X + N). Com base nas informações apresentadas no texto e considerando-se que o número de sobreviventes à idade exata X = 0 foi igual a 100.000, julgue o item subseqüente.
O quadro acima apresenta uma tábua abreviada de mortalidade para determinada população, obtida a partir de um censo demográfico realizado em 2007. As duas primeiras colunas dessa tabela definem o início e o comprimento do intervalo de tempo dos grupos etários (terceira coluna). A probabilidade Q(X, N) é a estimativa do risco de morte de um indivíduo pertencente ao grupo etário (X, X + N). Com base nas informações apresentadas no texto e considerando-se que o número de sobreviventes à idade exata X = 0 foi igual a 100.000, julgue o item subseqüente.
Uma criança, ao atingir 5 anos de idade em 2007, tem expectativa de vida superior a 68 anos e inferior a 69 anos.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409132
Estatística
Texto associado
O quadro acima apresenta uma tábua abreviada de mortalidade para determinada população, obtida a partir de um censo demográfico realizado em 2007. As duas primeiras colunas dessa tabela definem o início e o comprimento do intervalo de tempo dos grupos etários (terceira coluna). A probabilidade Q(X, N) é a estimativa do risco de morte de um indivíduo pertencente ao grupo etário (X, X + N). Com base nas informações apresentadas no texto e considerando-se que o número de sobreviventes à idade exata X = 0 foi igual a 100.000, julgue o item subseqüente.
O quadro acima apresenta uma tábua abreviada de mortalidade para determinada população, obtida a partir de um censo demográfico realizado em 2007. As duas primeiras colunas dessa tabela definem o início e o comprimento do intervalo de tempo dos grupos etários (terceira coluna). A probabilidade Q(X, N) é a estimativa do risco de morte de um indivíduo pertencente ao grupo etário (X, X + N). Com base nas informações apresentadas no texto e considerando-se que o número de sobreviventes à idade exata X = 0 foi igual a 100.000, julgue o item subseqüente.
O número esperado de sobreviventes à idade exata X = 10 é superior a 96 mil pessoas.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409133
Estatística
Texto associado
O quadro acima apresenta uma tábua abreviada de mortalidade para determinada população, obtida a partir de um censo demográfico realizado em 2007. As duas primeiras colunas dessa tabela definem o início e o comprimento do intervalo de tempo dos grupos etários (terceira coluna). A probabilidade Q(X, N) é a estimativa do risco de morte de um indivíduo pertencente ao grupo etário (X, X + N). Com base nas informações apresentadas no texto e considerando-se que o número de sobreviventes à idade exata X = 0 foi igual a 100.000, julgue o item subseqüente.
O quadro acima apresenta uma tábua abreviada de mortalidade para determinada população, obtida a partir de um censo demográfico realizado em 2007. As duas primeiras colunas dessa tabela definem o início e o comprimento do intervalo de tempo dos grupos etários (terceira coluna). A probabilidade Q(X, N) é a estimativa do risco de morte de um indivíduo pertencente ao grupo etário (X, X + N). Com base nas informações apresentadas no texto e considerando-se que o número de sobreviventes à idade exata X = 0 foi igual a 100.000, julgue o item subseqüente.
O número esperado de óbitos ocorridos no grupo etário de 5 a 9 anos é superior a 192 crianças e é inferior a 200 crianças.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409134
Estatística
Texto associado
O quadro acima apresenta uma tábua abreviada de mortalidade para determinada população, obtida a partir de um censo demográfico realizado em 2007. As duas primeiras colunas dessa tabela definem o início e o comprimento do intervalo de tempo dos grupos etários (terceira coluna). A probabilidade Q(X, N) é a estimativa do risco de morte de um indivíduo pertencente ao grupo etário (X, X + N). Com base nas informações apresentadas no texto e considerando-se que o número de sobreviventes à idade exata X = 0 foi igual a 100.000, julgue o item subseqüente.
O quadro acima apresenta uma tábua abreviada de mortalidade para determinada população, obtida a partir de um censo demográfico realizado em 2007. As duas primeiras colunas dessa tabela definem o início e o comprimento do intervalo de tempo dos grupos etários (terceira coluna). A probabilidade Q(X, N) é a estimativa do risco de morte de um indivíduo pertencente ao grupo etário (X, X + N). Com base nas informações apresentadas no texto e considerando-se que o número de sobreviventes à idade exata X = 0 foi igual a 100.000, julgue o item subseqüente.
As tábuas correspondentes aos anos intermediários à realização dos censos demográficos podem ser interpoladas por um modelo conhecido como método das componentes demográficas, que considera uma equação de equilíbrio que envolve, entre outras componentes, o movimento migratório.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409135
Estatística
Considere-se um vetor aleatório transposto xt = (X1, X2, X3) distribuído segundo uma distribuição normal com vetor de médias igual a µt = (– 5, 0, 5) e matriz de covariância 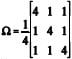 . Com base nessas informações, julgue o item subseqüente.
. Com base nessas informações, julgue o item subseqüente.
A forma quadrática µt Ω-1 é superior a 50 e inferior a 100.
. Com base nessas informações, julgue o item subseqüente.A forma quadrática µt Ω-1 é superior a 50 e inferior a 100.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409136
Estatística
Considere-se um vetor aleatório transposto xt = (X1, X2, X3) distribuído segundo uma distribuição normal com vetor de médias igual a µt = (– 5, 0, 5) e matriz de covariância . Com base nessas informações, julgue o item subseqüente.
O determinante de Ω-1 é superior a 1 e é inferior a 100
. Com base nessas informações, julgue o item subseqüente. O determinante de Ω-1 é superior a 1 e é inferior a 100
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409137
Estatística
Considere-se um vetor aleatório transposto xt = (X1, X2, X3) distribuído segundo uma distribuição normal com vetor de médias igual a µt = (– 5, 0, 5) e matriz de covariância . Com base nessas informações, julgue o item subseqüente.
Considerando os vetores transpostos v1 t = (– 5, 0, 0) e v2t = (0, 0, 0), o quadrado da distância de Mahalanobis entre ambos é superior a 30 e inferior a 60.
. Com base nessas informações, julgue o item subseqüente. Considerando os vetores transpostos v1 t = (– 5, 0, 0) e v2t = (0, 0, 0), o quadrado da distância de Mahalanobis entre ambos é superior a 30 e inferior a 60.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409138
Estatística
Considere-se um vetor aleatório transposto xt = (X1, X2, X3) distribuído segundo uma distribuição normal com vetor de médias igual a µt = (– 5, 0, 5) e matriz de covariância . Com base nessas informações, julgue o item subseqüente.
Considere-se e E = [e1, e2, e3], em que λ1, λ2 e λ3 são os autovalores de Ω e e1, e2 e e3 são os respectivos autovetores padronizados. Nessa situação, o vetor aleatório (E ∧Et ) (x - µ) segue uma distribuição normal cuja matriz de covariância é igual à matriz identidade.
e E = [e1, e2, e3], em que λ1, λ2 e λ3 são os autovalores de Ω e e1, e2 e e3 são os respectivos autovetores padronizados. Nessa situação, o vetor aleatório (E ∧Et ) (x - µ) segue uma distribuição normal cuja matriz de covariância é igual à matriz identidade.
. Com base nessas informações, julgue o item subseqüente. Considere-se
e E = [e1, e2, e3], em que λ1, λ2 e λ3 são os autovalores de Ω e e1, e2 e e3 são os respectivos autovetores padronizados. Nessa situação, o vetor aleatório (E ∧Et ) (x - µ) segue uma distribuição normal cuja matriz de covariância é igual à matriz identidade.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409139
Estatística
Considere-se um vetor aleatório transposto xt = (X1, X2, X3) distribuído segundo uma distribuição normal com vetor de médias igual a µt = (– 5, 0, 5) e matriz de covariância . Com base nessas informações, julgue o item subseqüente.
Considere a matriz aleatória Y = [y1, y2], em que y1 e y2 são vetores aleatórios independentes e com a mesma distribuição de x - µ. Nessa situação, YYt segue uma distribuição de Wishart com 2 graus de liberdade.
. Com base nessas informações, julgue o item subseqüente. Considere a matriz aleatória Y = [y1, y2], em que y1 e y2 são vetores aleatórios independentes e com a mesma distribuição de x - µ. Nessa situação, YYt segue uma distribuição de Wishart com 2 graus de liberdade.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409140
Estatística
Texto associado
Considere-se hipoteticamente que o tempo de contribuição previdenciário (T1) e a idade do trabalhador (T2) sejam variáveis aleatórias conjuntamente distribuídas como  , em que t1 > 0, t2 > 0, exp( ·) representa a função exponencial, λ > 0, e φ > 0 são os parâmetros da distribuição.
, em que t1 > 0, t2 > 0, exp( ·) representa a função exponencial, λ > 0, e φ > 0 são os parâmetros da distribuição.
, em que t1 > 0, t2 > 0, exp( ·) representa a função exponencial, λ > 0, e φ > 0 são os parâmetros da distribuição.
Acerca dessa situação hipotética, julgue o item que se segue.
A distribuição da idade do trabalhador é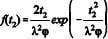 ,
,
A distribuição da idade do trabalhador é
,
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409141
Estatística
Texto associado
Considere-se hipoteticamente que o tempo de contribuição previdenciário (T1) e a idade do trabalhador (T2) sejam variáveis aleatórias conjuntamente distribuídas como , em que t1 > 0, t2 > 0, exp( ·) representa a função exponencial, λ > 0, e φ > 0 são os parâmetros da distribuição.
, em que t1 > 0, t2 > 0, exp( ·) representa a função exponencial, λ > 0, e φ > 0 são os parâmetros da distribuição.
Acerca dessa situação hipotética, julgue o item que se segue.
O tempo médio de contribuição previdenciária e a média da idade do trabalhador são, respectivamente, iguais a λ2φ e φ.
O tempo médio de contribuição previdenciária e a média da idade do trabalhador são, respectivamente, iguais a λ2φ e φ.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409142
Estatística
Texto associado
Considere-se hipoteticamente que o tempo de contribuição previdenciário (T1) e a idade do trabalhador (T2) sejam variáveis aleatórias conjuntamente distribuídas como , em que t1 > 0, t2 > 0, exp( ·) representa a função exponencial, λ > 0, e φ > 0 são os parâmetros da distribuição.
, em que t1 > 0, t2 > 0, exp( ·) representa a função exponencial, λ > 0, e φ > 0 são os parâmetros da distribuição.
Acerca dessa situação hipotética, julgue o item que se segue.
A probabilidade conjunta P(T1 > 0, T2 > 0) é inferior a 0,5.
A probabilidade conjunta P(T1 > 0, T2 > 0) é inferior a 0,5.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409143
Matemática
Texto associado
Considere-se hipoteticamente que o tempo de contribuição previdenciário (T1) e a idade do trabalhador (T2) sejam variáveis aleatórias conjuntamente distribuídas como , em que t1 > 0, t2 > 0, exp( ·) representa a função exponencial, λ > 0, e φ > 0 são os parâmetros da distribuição.
, em que t1 > 0, t2 > 0, exp( ·) representa a função exponencial, λ > 0, e φ > 0 são os parâmetros da distribuição.
Acerca dessa situação hipotética, julgue o item que se segue.
A esperança condicional pode ser escrita na forma de um modelo linear, isto é, E ( T1 T2 = t ) = αt + β , em que t > 0, ß = 0 e α = λ.
A esperança condicional pode ser escrita na forma de um modelo linear, isto é, E ( T1 T2 = t ) = αt + β , em que t > 0, ß = 0 e α = λ.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409144
Estatística
Com respeito ao texto anterior, considerando uma amostragem aleatória simples (X1, Y1), (X2, Y2), ...., (Xn, Yn) para a estimação dos parâmetros da distribuição (λ > 0, φ > 0), em que cada vetor aleatório (Xk, Yk) é identicamente distribuído como (T1, T2), k = 1, 2, ..., n, julgue o item subseqüente.
Os estimadores de máxima verossimilhança para λ e φ são, respectivamente, iguais a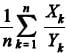 e
e 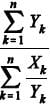 .
.
Os estimadores de máxima verossimilhança para λ e φ são, respectivamente, iguais a
e .
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409145
Estatística
Com respeito ao texto anterior, considerando uma amostragem aleatória simples (X1, Y1), (X2, Y2), ...., (Xn, Yn) para a estimação dos parâmetros da distribuição (λ > 0, φ > 0), em que cada vetor aleatório (Xk, Yk) é identicamente distribuído como (T1, T2), k = 1, 2, ..., n, julgue o item subseqüente.
Um estimador de mínimos quadrados para λ é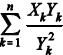
Um estimador de mínimos quadrados para λ é
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409146
Estatística
Com respeito ao texto anterior, considerando uma amostragem aleatória simples (X1, Y1), (X2, Y2), ...., (Xn, Yn) para a estimação dos parâmetros da distribuição (λ > 0, φ > 0), em que cada vetor aleatório (Xk, Yk) é identicamente distribuído como (T1, T2), k = 1, 2, ..., n, julgue o item subseqüente.
Por se tratar de uma amostra aleatória simples, espera-se que a correlação entre Xk e Yk seja nula.
Por se tratar de uma amostra aleatória simples, espera-se que a correlação entre Xk e Yk seja nula.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409147
Estatística
Texto associado
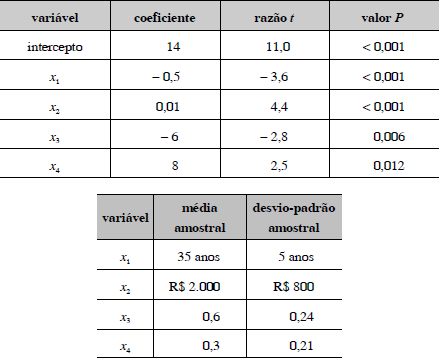
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
Com base nas informações apresentadas no texto, julgue o item a seguir.
O modelo ajustado pode ser usado para calcular os valores previstos para cada indivíduo com base nas suas características x1, x2, x3 e x4. O valor esperado da variável resposta é superior a 15 e inferior a 17.
O modelo ajustado pode ser usado para calcular os valores previstos para cada indivíduo com base nas suas características x1, x2, x3 e x4. O valor esperado da variável resposta é superior a 15 e inferior a 17.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409148
Estatística
Texto associado
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
Com base nas informações apresentadas no texto, julgue o item a seguir.
A variável x4 é relativamente mais importante do que a variável x2 , pois seu coeficiente é 800 vezes maior do que o coeficiente de x2 .
A variável x4 é relativamente mais importante do que a variável x2 , pois seu coeficiente é 800 vezes maior do que o coeficiente de x2 .
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409149
Estatística
Texto associado
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
Com base nas informações apresentadas no texto, julgue o item a seguir.
As variáveis dependentes são multicolineares.
As variáveis dependentes são multicolineares.