Questões de Concurso Público Petrobras 2022 para Ciência de Dados
Foram encontradas 120 questões
Em um processo em que se utiliza a ciência de dados, o número de variáveis necessárias para a realização da investigação de um fenômeno é direta e simplesmente igual ao número de variáveis utilizadas para mensurar as respectivas características desejadas; entretanto, é diferente o procedimento para determinar o número de variáveis explicativas, cujos dados estejam em escalas qualitativas.
Considerando esse aspecto dos modelos de regressão, julgue o item a seguir.
Para evitar um erro de ponderação arbitrária, deve-se
recorrer ao artifício de uso de variáveis dummy, o que
permitirá a estratificação da amostra da maneira que for
definido um determinado critério, evento ou atributo, para
então serem inseridas no modelo em análise; isso permitirá o
estudo da relação entre o comportamento de determinada
variável explicativa qualitativa e o fenômeno em questão,
representado pela variável dependente.
Acerca das características específicas dessas métricas, julgue o próximo item.
A matriz de confusão a seguir apresenta três rótulos de classe; os elementos diagonais representam o número de pontos para os quais o rótulo previsto é igual ao rotulo verdadeiro, enquanto qualquer coisa fora da diagonal teve um rótulo atribuído erroneamente pelo classificador. Quanto menores forem os valores diagonais da matriz de confusão, melhor o modelo adotado.
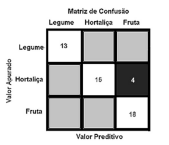
As métricas de avaliação de desempenho de um modelo de aprendizado de máquina, que é um componente integrante de qualquer projeto de ciência de dados, destinam-se a estimar a precisão da generalização de um modelo sobre os dados futuros (não vistos ou fora da amostra). Dentre as métricas mais conhecidas, estão a matriz de confusão, precisão, recall, pontuação, especificidade e a curva de características operacionais do receptor (ROC).
Acerca das características específicas dessas métricas, julgue o próximo item.
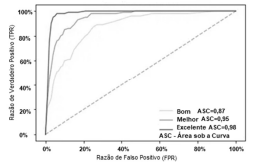
As curvas ROC a seguir mostram a taxa de especificidade
(verdadeiros positivos) versus a taxa de sensibilidade (falsos
positivos) do modelo adotado; a linha tracejada é a linha de
base da métrica de avaliação e define uma adivinhação
aleatória.
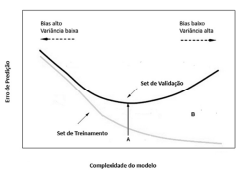
Julgue o próximo item, considerando o gráfico precedente, que representa as regiões de overfitting e de underfitting, permitindo uma avaliação do relacionamento da complexidade do modelo de aprendizagem de máquina adotado, com o erro de predição.
A região do gráfico entre as duas curvas, indicada pela letra
B, mostra a região de erro de generalização para o modelo de
aprendizado de máquina.
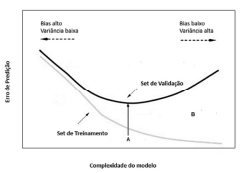
Julgue o próximo item, considerando o gráfico precedente, que representa as regiões de overfitting e de underfitting, permitindo uma avaliação do relacionamento da complexidade do modelo de aprendizagem de máquina adotado, com o erro de predição.
O Set de Treinamento é usado para qualificar o desempenho
do modelo, enquanto o Set de Validação é utilizado para
criar o modelo de aprendizado de máquina.