Questões de Concurso Público Petrobras 2022 para Ciência de Dados
Foram encontradas 120 questões
Considering the previous text, judge the following item.
According to the text, handsets are essential for people
because sometimes healthcare, education and social services
are offered only through smartphones.
Considering the previous text, judge the following item.
In the sentence (thirteenth paragraph) “Yet, while some
worry about how much time they spend on their handset, for
millions of others they are a godsend.”, the word “Yet” is
synonymous with However.
Considering the previous text, judge the following item.
The only way Alex Dunedin connects electronically is via
emails on his home computer.
Considering the previous text, judge the following item.
People who are giving up on their mobile devices believe
they were spending too much time with being connected and
they were missing their real lives because of that.
Considering the previous text, judge the following item.
It was when Dulcie Cowling was in the park with her two
kids that she took her decision to ditch her smartphone and
then she told her family and friends about it after Christmas.
Considering the previous text, judge the following item.
In the sentence ‘They are blunting cognition and impeding
productivity’ (ninth paragraph), the pronoun ‘They’ refers to
the “nine out of 10 people in the UK who own a
smartphone” (seventh paragraph).
Considering the previous text, judge the following item.
Although there is a movement of people ditching their
smartphones in order to have what they think is a better life
quality, millions believe digital technology is essential to
everyone’s lives.
Judge the following item, based on the previous text.
In the last sentence of the last paragraph, the word “prickly”
means peaceful.
Judge the following item, based on the previous text.
The War of the Worlds was a radio drama that told the real
story of an invasion from Mars, panicking countless people.
Judge the following item, based on the previous text.
According to the text, the speculations about extraterrestrial
life started in the late 1800s due to canal-like features
observed on Mars.
Em um processo em que se utiliza a ciência de dados, o número de variáveis necessárias para a realização da investigação de um fenômeno é direta e simplesmente igual ao número de variáveis utilizadas para mensurar as respectivas características desejadas; entretanto, é diferente o procedimento para determinar o número de variáveis explicativas, cujos dados estejam em escalas qualitativas.
Considerando esse aspecto dos modelos de regressão, julgue o item a seguir.
Para evitar um erro de ponderação arbitrária, deve-se
recorrer ao artifício de uso de variáveis dummy, o que
permitirá a estratificação da amostra da maneira que for
definido um determinado critério, evento ou atributo, para
então serem inseridas no modelo em análise; isso permitirá o
estudo da relação entre o comportamento de determinada
variável explicativa qualitativa e o fenômeno em questão,
representado pela variável dependente.
Acerca das características específicas dessas métricas, julgue o próximo item.
A matriz de confusão a seguir apresenta três rótulos de classe; os elementos diagonais representam o número de pontos para os quais o rótulo previsto é igual ao rotulo verdadeiro, enquanto qualquer coisa fora da diagonal teve um rótulo atribuído erroneamente pelo classificador. Quanto menores forem os valores diagonais da matriz de confusão, melhor o modelo adotado.
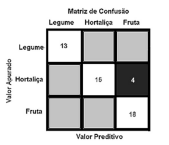
As métricas de avaliação de desempenho de um modelo de aprendizado de máquina, que é um componente integrante de qualquer projeto de ciência de dados, destinam-se a estimar a precisão da generalização de um modelo sobre os dados futuros (não vistos ou fora da amostra). Dentre as métricas mais conhecidas, estão a matriz de confusão, precisão, recall, pontuação, especificidade e a curva de características operacionais do receptor (ROC).
Acerca das características específicas dessas métricas, julgue o próximo item.
As curvas ROC a seguir mostram a taxa de especificidade
(verdadeiros positivos) versus a taxa de sensibilidade (falsos
positivos) do modelo adotado; a linha tracejada é a linha de
base da métrica de avaliação e define uma adivinhação
aleatória.
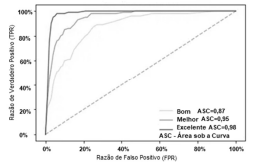
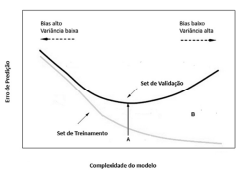
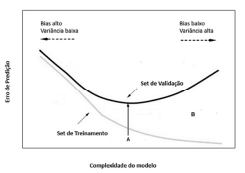
Julgue o próximo item, considerando o gráfico precedente, que representa as regiões de overfitting e de underfitting, permitindo uma avaliação do relacionamento da complexidade do modelo de aprendizagem de máquina adotado, com o erro de predição.
A região do gráfico entre as duas curvas, indicada pela letra
B, mostra a região de erro de generalização para o modelo de
aprendizado de máquina.
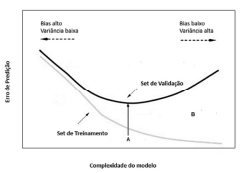
Julgue o próximo item, considerando o gráfico precedente, que representa as regiões de overfitting e de underfitting, permitindo uma avaliação do relacionamento da complexidade do modelo de aprendizagem de máquina adotado, com o erro de predição.
O Set de Treinamento é usado para qualificar o desempenho
do modelo, enquanto o Set de Validação é utilizado para
criar o modelo de aprendizado de máquina.
Julgue o próximo item, considerando o gráfico precedente, que representa as regiões de overfitting e de underfitting, permitindo uma avaliação do relacionamento da complexidade do modelo de aprendizagem de máquina adotado, com o erro de predição.
Considerando que a variância é um erro de sensibilidade para
pequenas flutuações no conjunto de treinamento, infere-se
que um baixo nível de variância pode fazer que o algoritmo
associado a um modelo de aprendizado de máquina perca as
relações relevantes entre os atributos de entrada e a variável
de saída, caracterizando o erro de overfitting, percebido na
região à direita do ponto A.
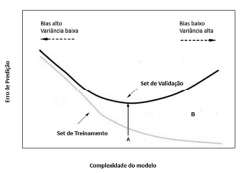
Julgue o próximo item, considerando o gráfico precedente, que representa as regiões de overfitting e de underfitting, permitindo uma avaliação do relacionamento da complexidade do modelo de aprendizagem de máquina adotado, com o erro de predição.
Quando se verifica um alto erro no treinamento com valor
próximo ao erro na validação, percebido na região à
esquerda do ponto A, tem-se um clássico problema de
underfitting, caracterizado pelo alto valor do bias.
 respectivamente, as médias amostrais das variáveis x e y.
respectivamente, as médias amostrais das variáveis x e y.
Com base nos dados dessa tabela, julgue o próximo item.
Uma forma de melhorar o modelo de regressão linear para a
situação em questão é utilizar o modelo de regressão
logística, uma vez que a variável dependente se apresenta de
forma quantitativa.
respectivamente, as médias amostrais das variáveis x e y.Com base nos dados dessa tabela, julgue o próximo item.
Pelo modelo de regressão linear simples, a equação que
expressa o relacionamento ajustado entre a variável y em função de x é 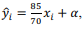 em que α é uma constante.
em que α é uma constante.
Uma árvore de decisão representa um determinado número de caminhos possíveis de decisão e os resultados de cada um deles, apresentando muitos pontos positivos, ou seja, são fáceis de entender e interpretar. Elas têm processo de previsão completamente transparente e lidam facilmente com diversos atributos numéricos, assim como atributos categóricos, podendo até mesmo classificar dados sem atributos definidos.
De acordo com os aspectos construtivos de uma árvore de decisão, julgue o item a seguir.
Se o processo adotado para a construção de árvores de
decisão for determinístico, uma forma de obtenção de
árvores aleatórias, que compõem as florestas aleatórias, pode
ser realizada por meio do bootstrap dos dados, em que cada
árvore é treinada com base no resultado de bootstrap_sample
(inputs).