Questões de Concurso Público Petrobras 2022 para Ciência de Dados
Foram encontradas 120 questões
Com respeito a machine learning aplicado, julgue o próximo item.
Stop-words constituem um conjunto de palavras que
proporcionam pouca informação para o significado de uma
frase.
Com respeito a machine learning aplicado, julgue o próximo item.
O CBOW é um modelo de aprendizado de máquina
desenhado para prever contexto com base em determinada
palavra.
Com respeito a machine learning aplicado, julgue o próximo item.
Suponha que a palavra amor ocorra 1.000 vezes no último
livro escrito por certo autor, que escreveu, no total, 10 livros.
Nesse caso, se a palavra amor for encontrada em todos os
livros desse autor, então o valor do TF-IDF (term frequencyinverse document frequency) referente à palavra amor no
último livro escrito será igual a 1/1.000.
Considerando uma série temporal representada por {Xt}, julgue o item a seguir.
Se a figura abaixo apresenta a forma da função de autocorrelação parcial (facp) da série temporal {Xt}, na qual as correlações parciais são nulas nos lags iguais ou superiores a 2, então a autocorrelação entre Xt e Xt-4 é igual a zero.
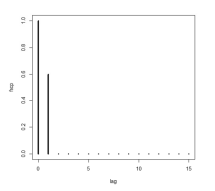
Considerando uma série temporal representada por {Xt}, julgue o item a seguir.
Se a série temporal for gerada por um processo na forma
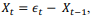
no qual Et representa um ruído branco com média zero e desvio padrão igual a 1, então a variância de Xt será igual a 0,5.

Considerando a figura precedente, que mostra desenhos esquemáticos das distribuições das quantidades de cargas perdidas nos anos de 2020 e 2021, segundo o tipo de carga transportada por uma mineradora, julgue o item que se segue.
No que se refere à distribuição da quantidade de carga do
tipo B perdida em 2021, observa-se que o valor da perda
mínima foi superior a Q1 -1,5Dq, no qual Q1 representa o
primeiro quartil e Dq denota o intervalo interquartil da
distribuição em tela.
Considerando a figura precedente, que mostra desenhos esquemáticos das distribuições das quantidades de cargas perdidas nos anos de 2020 e 2021, segundo o tipo de carga transportada por uma mineradora, julgue o item que se segue.
Na distribuição da quantidade de carga do tipo A perdida em
2020, observa-se que o primeiro quartil foi superior a
100 kg, enquanto o terceiro quartil foi inferior a 50 kg.
Considerando a figura precedente, que mostra desenhos esquemáticos das distribuições das quantidades de cargas perdidas nos anos de 2020 e 2021, segundo o tipo de carga transportada por uma mineradora, julgue o item que se segue.
No desenho esquemático referente à distribuição da
quantidade de carga do tipo C perdida em 2020, os dois
pontos exteriores representam as observações destoantes das
demais, que podem ou não podem ser considerados outliers.
Considerando a figura precedente, que mostra desenhos esquemáticos das distribuições das quantidades de cargas perdidas nos anos de 2020 e 2021, segundo o tipo de carga transportada por uma mineradora, julgue o item que se segue.
Suponha que os valores das quantidades de carga perdida sejam submetidos a uma normalização numérica com base no critério do Z-score da forma
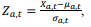
em que Xa,t denota a quantidade de carga do tipo t perdida no ano a, μa,t representa a quantidade média de carga do tipo t perdida no ano a, e σa,t , refere-se ao desvio padrão da distribuição da quantidade de carga do tipo t perdida no ano a. Como resultado dessa normalização, a média da soma
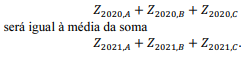
Com respeito a métodos para imputação de dados, julgue o seguinte item.
O método de imputação K-NN (k-nearest neighbours) leva
em consideração os padrões de similaridade presentes no
conjunto de dados para predizer os valores faltantes. No
entanto, a escolha da função de distância para a aplicação
desse método, como, por exemplo, HEOM (heterogeneous
euclidean-overlap metric) ou HVDM (heterogeneous value
difference metric), pode influenciar significativamente nos
resultados da imputação.
Com respeito a métodos para imputação de dados, julgue o seguinte item.
Um dos passos para tratar com dados faltantes é avaliar o
tipo de dado perdido; assim, por exemplo, o método MICE
(multivariate imputation by chained equations) não seria
aplicável para dados perdidos do tipo MAR (missing at
random).
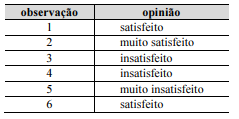 Com base nessas informações, julgue o próximo item.
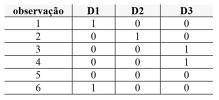
Com base nessas informações, julgue o próximo item. Para lidar numericamente com os dados categóricos, uma codificação binária proporciona uma conversão de cada categoria de resposta para uma sequência de dígitos binários, em que cada dígito binário representa uma variável numérica que assume valores 0 ou 1. Na situação em tela, uma possível codificação binária é exemplificada na tabela abaixo.

Considerando essas informações, julgue o próximo item.
O código abaixo permite importar corretamente o arquivo pesquisa.csv para ser manuseado como um data frame no Python.

Considerando essas informações, julgue o próximo item.
O código abaixo permite importar apenas a última linha das duas primeiras colunas do arquivo pesquisa.csv.


Com base no modelo entidade-relacionamento (MER) precedente, que apresenta a representação das regras de uma instituição de pesquisa, existe um Pesquisador cadastrado com o nome Pedro. Todos os atributos do MER são do tipo caractere e um dos comandos SQL usados para a construção do modelo é mostrado a seguir.

A partir das informações constantes no modelo e dos dados sobre o conteúdo dos atributos, julgue o item subsecutivo.
Após a criação da tabela Projeto, a criação das chaves estrangeiras (FK) do relacionamento Orienta pode ser feita corretamente conforme a seguir.

Com base no modelo entidade-relacionamento (MER) precedente, que apresenta a representação das regras de uma instituição de pesquisa, existe um Pesquisador cadastrado com o nome Pedro. Todos os atributos do MER são do tipo caractere e um dos comandos SQL usados para a construção do modelo é mostrado a seguir.
A partir das informações constantes no modelo e dos dados sobre o conteúdo dos atributos, julgue o item subsecutivo.
Projeto é uma entidade fraca em relação à entidade
Pesquisador, considerando o relacionamento
identificado como Responsavel e os atributos do MER.
Com base no modelo entidade-relacionamento (MER) precedente, que apresenta a representação das regras de uma instituição de pesquisa, existe um Pesquisador cadastrado com o nome Pedro. Todos os atributos do MER são do tipo caractere e um dos comandos SQL usados para a construção do modelo é mostrado a seguir.
A partir das informações constantes no modelo e dos dados sobre o conteúdo dos atributos, julgue o item subsecutivo.
Por meio do comando SQL a seguir, é possível recuperar o nome dos pesquisadores responsáveis por projetos, seguido pelo nome de seu orientador, mas apenas os projetos orientados por Pedro.

Com referência aos conceitos de banco de dados e data warehouse, julgue o item seguinte.
Em sistemas NoSQL baseados em armazenamento de chave-valor, a chave é multidimensional e composta pela
combinação do nome de tabela com a chave linha-coluna e
com o rótulo de data e hora.
O Hadoop Distributed File System (HDFS) é construído usando a linguagem Java, o que permite que sua arquitetura mestre/escravo seja implementada em uma ampla variedade de máquinas
Com base nessas informações hipotéticas, julgue o próximo item.
O volume instantâneo que o poço produz está aumentando
no instante t = 10 horas.