Questões de Concurso Público Petrobras 2022 para Ciência de Dados
Foram encontradas 120 questões
De acordo com os aspectos construtivos de uma árvore de decisão, julgue o item a seguir.
A entropia de uma árvore de decisão aborda o aspecto da quantidade de informações que está associada às respostas que podem ser obtidas às perguntas formuladas, representando o grau de incerteza associado aos dados.
As máquinas de vetores de suporte (SVMs) são originalmente utilizadas para a classificação de dados em duas classes, ou seja, na geração de dicotomias. Nas SVMs com margens rígidas, conjuntos de treinamento linearmente separáveis podem ser classificados. Acerca das características das SVMs com margens rígidas, julgue o item a seguir.
Um conjunto linearmente separável é composto por
exemplos que podem ser separados por pelo menos um
hiperplano. As SVMs lineares buscam o hiperplano
ótimo segundo a teoria do aprendizado estatístico, definido
como aquele em que a margem de separação entre as classes
presentes nos dados é minimizada.
O ensemble denominado bagging tem como foco principal a redução do viés e não da variância, treinando-se os modelos em sequência, tal que os erros dos primeiros modelos treinados são utilizados para o ajuste nos pesos matemáticos dos próximos modelos.
Os algoritmos de aprendizado supervisionado partem de um conjunto de dados rotulados para fazer previsões sobre novos dados não rotulados. O Python scikit-learn é uma biblioteca de código aberto utilizada para codificações de rotinas em aprendizado de máquina supervisionado; ela oferece ainda uma série de ferramentas utilizadas no ajuste de modelos e no pré-processamento de dados, para a seleção e avaliação de modelos.
Tendo como referência essas informações, julgue o item a seguir.
No código a seguir, 
 é um
classificador que recebe como entrada dois arrays: um array X,
é um
classificador que recebe como entrada dois arrays: um array X,

Os algoritmos de aprendizado supervisionado partem de um conjunto de dados rotulados para fazer previsões sobre novos dados não rotulados. O Python scikit-learn é uma biblioteca de código aberto utilizada para codificações de rotinas em aprendizado de máquina supervisionado; ela oferece ainda uma série de ferramentas utilizadas no ajuste de modelos e no pré-processamento de dados, para a seleção e avaliação de modelos.
Tendo como referência essas informações, julgue o item a seguir.
SVC, NuSCV e LinearSVC são classes do scikit-learn
capazes de realizar classificação binária e multiclasse em um
conjunto de dados.
Os hiperparâmetros de um modelo são todos os parâmetros que podem ser definidos antes do inicio do treinamento, diferentemente dos parâmetros do modelo, que são aprendidos durante o treino do modelo. A busca por hiperparâmetros de determinado algoritmo de aprendizado de máquina que retorne o melhor desempenho medido em um conjunto de validação deu origem ao conceito de otimização de hiperparâmetros.
Acerca dos conceitos de otimização de hiperparâmetros de
modelos de aprendizado de máquinas, julgue o item que se segue.
A otimização bayesiana se utiliza do conceito de
probabilidade para encontrar o valor de entrada de uma
função que possa retornar o menor valor de saída possível.
Nesse método, o número de iterações de pesquisa pode ser
reduzido a partir da escolha dos valores de entrada, levando
em consideração os resultados anteriores, o que caracteriza
um processo iterativo.
Com respeito a análise de componentes principais, mistura de gaussianas e agrupamento k-means, julgue o item que se segue.
Se a matriz de variância-covariância referente a três variáveis for
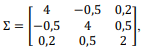
e se o menor autovalor dessa matriz for igual a 1,84, então as
duas primeiras componentes principais explicam 81,6% da
variação total referente a essas variáveis.
Com respeito a análise de componentes principais, mistura de gaussianas e agrupamento k-means, julgue o item que se segue.
Considere que, em uma análise de agrupamentos por meio de
mistura de gaussianas, três distribuições normais com médias 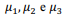 se referem, respectivamente, aos clusters 1, 2 e 3.
Nessa situação, pelo modelo de mistura de gaussianas, o
cluster 1 é constituído pelas observações mais próximas da
média
se referem, respectivamente, aos clusters 1, 2 e 3.
Nessa situação, pelo modelo de mistura de gaussianas, o
cluster 1 é constituído pelas observações mais próximas da
média 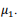
Com respeito a análise de componentes principais, mistura de gaussianas e agrupamento k-means, julgue o item que se segue.
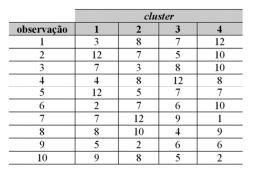
Considere a tabela abaixo que mostra as distâncias entre cada observação de um conjunto de dados hipotético e os vetores médios (centroides) do cluster correspondente ao final da aplicação do algoritmo de agrupamento k-means. Com base nessa tabela, infere-se que o cluster 1 é constituído pelas observações 2, 5 e 10.
Julgue o próximo item, relativos a redes neurais artificiais (RNA).
Uma RNA é formada por unidades que fazem operações a partir das entradas (sinais) recebidas pelas suas conexões; cada sinal é multiplicado por um peso e, após a soma ponderada dos sinais, caso o nível de atividade atinja o threshold, a unidade produz uma determinada resposta de saída.
Julgue o próximo item, relativos a redes neurais artificiais (RNA).
Em RNA formada unicamente de perceptron, uma pequena
alteração nos pesos de um único perceptron na rede pode
ocasionar grandes mudanças na saída desse perceptron;
mesmo com a inserção das funções de ativação, não é
possível controlar o nível da mudança, por isso, essas redes
são voltadas para a resolução de problemas específicos, tais
como regressão e previsão de séries temporais.
Julgue o próximo item, relativos a redes neurais artificiais (RNA).
As funções de ativação são elementos importantes nas redes
neurais artificiais; essas funções introduzem componente não
linear nas redes neurais, fazendo que elas possam aprender
mais do que relações lineares entre as variáveis dependentes
e independentes, tornando-as capazes de modelar também
relações não lineares.
Julgue o próximo item, relativos a redes neurais artificiais (RNA).
O algoritmo de backpropagation consiste das fases de
propagação e de retro propagação: na primeira, as entradas
são passadas através da rede e as previsões de saída são
obtidas; na segunda, se calcula o termo de correção dos
pesos e, por conseguinte, a atualização dos pesos.
Julgue o próximo item, relativos a redes neurais artificiais (RNA).
Rede neural recorrente é uma arquitetura similar à
feedforward; a diferença é que a cada nova camada oculta
(hidden layer) é acrescentada outra camada recorrente à
arquitetura conectada à camada anterior, duplicando assim a
quantidade de camadas.
Julgue o próximo item, relativos a redes neurais artificiais (RNA).
Em RNA, o uso de early stopping, ainda que não evite o
overfitting, permite calcular com mais precisão a
classificação nos dados de validação e, assim, melhorar a
acurácia do treinamento.
Julgue o próximo item, relativos a redes neurais artificiais (RNA).
As redes neurais convolucionais se utilizam de uma
arquitetura especial que é adaptada para classificar imagens
por meio de algoritmo de aprendizado profundo que pode
captar uma imagem de entrada, atribuir importância por meio
de pesos e ser capaz de diferenciar um do outro.
Julgue o próximo item, relativos a redes neurais artificiais (RNA).
Uma rede neural convolucional é composta por camadas
convolucionais, unidades de processamento não linear e
camadas de subamostragem (pooling); ela possui como
característica a habilidade em explorar correlações temporais
e espaciais nos dados.
Julgue o próximo item, relativos a redes neurais artificiais (RNA).
No código abaixo, escrito em Python, o método 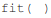 retorna o valor de perda e os valores de métricas para o
modelo, no modo de teste, tendo como referência o número
de eras
retorna o valor de perda e os valores de métricas para o
modelo, no modo de teste, tendo como referência o número
de eras 

Com respeito a machine learning aplicado, julgue o próximo item.
Classificação de imagens é um método de aprendizado não
supervisionado no qual se aplica um modelo de treinamento
para o reconhecimento de padrões gráficos presentes em
amostras de imagens.
Com respeito a machine learning aplicado, julgue o próximo item.
Mask RCNN (region-based convolutional neural network) é
um método para segmentação de objetos e instâncias que se
baseia em detecção, enquanto o método SSAP (single-shot
instance segmentation) se baseia em pixels.