Questões de Concurso
Sobre estatística descritiva (análise exploratória de dados) em estatística
Foram encontradas 3.963 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2014
Banca:
CESPE / CEBRASPE
Órgão:
TJ-SE
Prova:
CESPE / CEBRASPE - 2014 - TJ-SE - Analista Judiciário - Estatística |
Q410718
Estatística

O quadro acima mostra uma síntese da movimentação processual dos tribunais de justiça dos estados de São Paulo, Rio de Janeiro, Minas Gerais, Rio Grande do Sul e do total da justiça estadual no Brasil em 2010. Considere que o estoque de processos em andamento no estado j (Ej ), no final de 2010, seja um indicador que se define como Ej = Xj + Yj - Zj - Wj , em que j = 1, 2, ..., 27; Xj representa o número de casos novos registrados em 2010 no estado j; Yj seja a quantidade de casos pendentes no estado j (i.e., casos anteriores que não foram solucionados até o final de 2010); Zj denota o total de processos baixados (arquivados) no estado j durante 2010 e Wj seja o número de sentenças e decisões proferidas no estado j até o final de 2010. Considere, por fim, que, para todos os efeitos, o Distrito Federal seja um estado. Com base nessas informações e no quadro acima, julgue os itens que se seguem.
Considerando-se que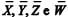 representem, respectivamente, as médias aritméticas das variáveis X, Y, Z e W, então
representem, respectivamente, as médias aritméticas das variáveis X, Y, Z e W, então 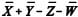 representa a média aritmética da distribuição dos estoques de processos observados nos tribunais estaduais.
representa a média aritmética da distribuição dos estoques de processos observados nos tribunais estaduais.
Considerando-se que
representem, respectivamente, as médias aritméticas das variáveis X, Y, Z e W, então representa a média aritmética da distribuição dos estoques de processos observados nos tribunais estaduais.
Ano: 2014
Banca:
CESPE / CEBRASPE
Órgão:
TJ-SE
Prova:
CESPE / CEBRASPE - 2014 - TJ-SE - Analista Judiciário - Estatística |
Q410716
Estatística
O quadro acima mostra uma síntese da movimentação processual dos tribunais de justiça dos estados de São Paulo, Rio de Janeiro, Minas Gerais, Rio Grande do Sul e do total da justiça estadual no Brasil em 2010. Considere que o estoque de processos em andamento no estado j (Ej ), no final de 2010, seja um indicador que se define como Ej = Xj + Yj - Zj - Wj , em que j = 1, 2, ..., 27; Xj representa o número de casos novos registrados em 2010 no estado j; Yj seja a quantidade de casos pendentes no estado j (i.e., casos anteriores que não foram solucionados até o final de 2010); Zj denota o total de processos baixados (arquivados) no estado j durante 2010 e Wj seja o número de sentenças e decisões proferidas no estado j até o final de 2010. Considere, por fim, que, para todos os efeitos, o Distrito Federal seja um estado. Com base nessas informações e no quadro acima, julgue os itens que se seguem.
Considerando-se apenas os dados relativos aos estados de São Paulo, Rio de Janeiro, Minas Gerais e Rio Grande do Sul quanto à dispersão entre duas variáveis, é correto afirmar que a covariância entre Z e W é superior a 1 e inferior a 2.
Considerando-se apenas os dados relativos aos estados de São Paulo, Rio de Janeiro, Minas Gerais e Rio Grande do Sul quanto à dispersão entre duas variáveis, é correto afirmar que a covariância entre Z e W é superior a 1 e inferior a 2.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409152
Estatística
Texto associado
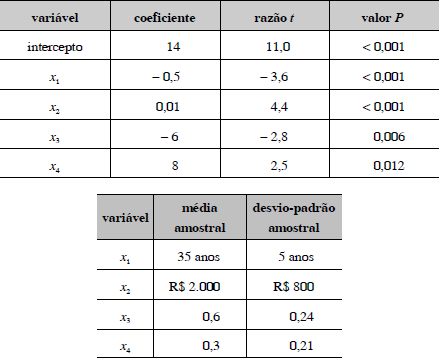
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
Com base nas informações apresentadas no texto, julgue o item a seguir.
O stepwise é um método computacional para a estimação de coeficientes do modelo de regressão linear. Nesse método, inicialmente, todas as q variáveis explanatórias de interesse estão disponíveis no banco de dados. Em seguida, observam-se os valores da razão t e exclui-se aquela variável que possui o maior valor P. Repete-se o procedimento para as q - 1 variáveis restantes e assim sucessivamente. O processo termina quando todas as estimativas dos coeficientes apresentam valores P baixos, como os que estão apresentados no quadro do texto
O stepwise é um método computacional para a estimação de coeficientes do modelo de regressão linear. Nesse método, inicialmente, todas as q variáveis explanatórias de interesse estão disponíveis no banco de dados. Em seguida, observam-se os valores da razão t e exclui-se aquela variável que possui o maior valor P. Repete-se o procedimento para as q - 1 variáveis restantes e assim sucessivamente. O processo termina quando todas as estimativas dos coeficientes apresentam valores P baixos, como os que estão apresentados no quadro do texto
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409151
Estatística
Texto associado
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
Com base nas informações apresentadas no texto, julgue o item a seguir.
A quantidade de mulheres com x3 = 1 e x4 = 1 é superior a 310.
A quantidade de mulheres com x3 = 1 e x4 = 1 é superior a 310.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409150
Estatística
Texto associado
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
Com base nas informações apresentadas no texto, julgue o item a seguir.
O coeficiente de variação de x1 é superior a 1.
O coeficiente de variação de x1 é superior a 1.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409149
Estatística
Texto associado
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
Com base nas informações apresentadas no texto, julgue o item a seguir.
As variáveis dependentes são multicolineares.
As variáveis dependentes são multicolineares.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409148
Estatística
Texto associado
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
Com base nas informações apresentadas no texto, julgue o item a seguir.
A variável x4 é relativamente mais importante do que a variável x2 , pois seu coeficiente é 800 vezes maior do que o coeficiente de x2 .
A variável x4 é relativamente mais importante do que a variável x2 , pois seu coeficiente é 800 vezes maior do que o coeficiente de x2 .
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409147
Estatística
Texto associado
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
Um estudo acerca da depressão pós-parto em uma população de trabalhadoras foi realizado por um pesquisador, envolvendo uma amostra de 1.024 mulheres. As variáveis do estudo foram observadas por intermédio de um questionário, sendo ajustado o modelo y = 14 - 0,5 x1 + 0,01 x2 - 6 x3 + 8 x4, em que a variável resposta y é um índice de depressão e as variáveis explanatórias x1 e x2 são, respectivamente, a idade (em anos) e a renda (em reais), enquanto x3 e x4 são variáveis binárias que assumem valores zero ou um. As covariâncias entre as variáveis explanatórias não são nulas. O método utilizado para a seleção de variáveis foi o stepwise. Os quadros acima apresentam um resumo do ajuste.
Com base nas informações apresentadas no texto, julgue o item a seguir.
O modelo ajustado pode ser usado para calcular os valores previstos para cada indivíduo com base nas suas características x1, x2, x3 e x4. O valor esperado da variável resposta é superior a 15 e inferior a 17.
O modelo ajustado pode ser usado para calcular os valores previstos para cada indivíduo com base nas suas características x1, x2, x3 e x4. O valor esperado da variável resposta é superior a 15 e inferior a 17.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409126
Estatística
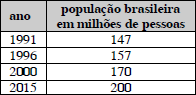
A tabela acima apresenta a evolução da população brasileira segundo os censos de 1991 e 2000, a contagem populacional de 1996 e uma projeção feita para o ano 2015. Com base nas informações apresentadas e na tabela, julgue o item seguinte.
A taxa média anual de crescimento geométrico de 1996 a 2000 foi inferior a 2% ao ano.
A taxa média anual de crescimento geométrico de 1996 a 2000 foi inferior a 2% ao ano.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409125
Estatística
A tabela acima apresenta a evolução da população brasileira segundo os censos de 1991 e 2000, a contagem populacional de 1996 e uma projeção feita para o ano 2015. Com base nas informações apresentadas e na tabela, julgue o item seguinte.
De 1991 a 1996, o crescimento relativo da população foi superior a 7% e inferior a 7,5%. O crescimento absoluto nesse período foi igual a 2 milhões de pessoas ao ano.
De 1991 a 1996, o crescimento relativo da população foi superior a 7% e inferior a 7,5%. O crescimento absoluto nesse período foi igual a 2 milhões de pessoas ao ano.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409124
Estatística
Texto associado
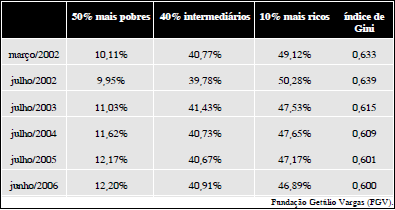
O mercado de trabalho brasileiro promoveu nos últimos quatro anos uma melhor distribuição de renda. Entre março de 2002 e junho de 2006, a participação dos 50% trabalhadores mais pobres na renda do país passou de 10,11% para 12,20%, enquanto a fatia de 10% dos trabalhadores mais ricos caiu de 49,12% para 46,89% no mesmo período. Com isso o índice de Gini recuou de 0,633 para 0,600 (quadro acima). No período de 2002 a 2006, embora ainda ganhem 23 vezes menos que os abastados, foram os trabalhadores mais pobres que tiveram melhor ganho de renda. Entre 2002 e 2006, 50% dos trabalhadores mais pobres viram sua renda média crescer 29,5%, de R$ 59,49 para R$ 77,03, enquanto que 10% dos trabalhadores mais ricos tiveram apenas 1,18% de ganho, de R$ 1.775,23 para R$ 1.796,23. No mesmo período, 40% trabalhadores intermediários (a conhecida classe média) tiveram 7,75% de ganho, de R$ 342,16 para R$ 368,69.
Correio Braziliense, 23/8/2006, p. 14 (com adaptações).
O mercado de trabalho brasileiro promoveu nos últimos quatro anos uma melhor distribuição de renda. Entre março de 2002 e junho de 2006, a participação dos 50% trabalhadores mais pobres na renda do país passou de 10,11% para 12,20%, enquanto a fatia de 10% dos trabalhadores mais ricos caiu de 49,12% para 46,89% no mesmo período. Com isso o índice de Gini recuou de 0,633 para 0,600 (quadro acima). No período de 2002 a 2006, embora ainda ganhem 23 vezes menos que os abastados, foram os trabalhadores mais pobres que tiveram melhor ganho de renda. Entre 2002 e 2006, 50% dos trabalhadores mais pobres viram sua renda média crescer 29,5%, de R$ 59,49 para R$ 77,03, enquanto que 10% dos trabalhadores mais ricos tiveram apenas 1,18% de ganho, de R$ 1.775,23 para R$ 1.796,23. No mesmo período, 40% trabalhadores intermediários (a conhecida classe média) tiveram 7,75% de ganho, de R$ 342,16 para R$ 368,69.
Correio Braziliense, 23/8/2006, p. 14 (com adaptações).
Com base nas informações apresentadas no texto acima, julgue o item que se segue .
A covariância entre os índices de Gini e os meses apresentados na tabela é superior a -0,30 e inferior a -0,10.
A covariância entre os índices de Gini e os meses apresentados na tabela é superior a -0,30 e inferior a -0,10.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409123
Estatística
Texto associado
O mercado de trabalho brasileiro promoveu nos últimos quatro anos uma melhor distribuição de renda. Entre março de 2002 e junho de 2006, a participação dos 50% trabalhadores mais pobres na renda do país passou de 10,11% para 12,20%, enquanto a fatia de 10% dos trabalhadores mais ricos caiu de 49,12% para 46,89% no mesmo período. Com isso o índice de Gini recuou de 0,633 para 0,600 (quadro acima). No período de 2002 a 2006, embora ainda ganhem 23 vezes menos que os abastados, foram os trabalhadores mais pobres que tiveram melhor ganho de renda. Entre 2002 e 2006, 50% dos trabalhadores mais pobres viram sua renda média crescer 29,5%, de R$ 59,49 para R$ 77,03, enquanto que 10% dos trabalhadores mais ricos tiveram apenas 1,18% de ganho, de R$ 1.775,23 para R$ 1.796,23. No mesmo período, 40% trabalhadores intermediários (a conhecida classe média) tiveram 7,75% de ganho, de R$ 342,16 para R$ 368,69.
Correio Braziliense, 23/8/2006, p. 14 (com adaptações).
O mercado de trabalho brasileiro promoveu nos últimos quatro anos uma melhor distribuição de renda. Entre março de 2002 e junho de 2006, a participação dos 50% trabalhadores mais pobres na renda do país passou de 10,11% para 12,20%, enquanto a fatia de 10% dos trabalhadores mais ricos caiu de 49,12% para 46,89% no mesmo período. Com isso o índice de Gini recuou de 0,633 para 0,600 (quadro acima). No período de 2002 a 2006, embora ainda ganhem 23 vezes menos que os abastados, foram os trabalhadores mais pobres que tiveram melhor ganho de renda. Entre 2002 e 2006, 50% dos trabalhadores mais pobres viram sua renda média crescer 29,5%, de R$ 59,49 para R$ 77,03, enquanto que 10% dos trabalhadores mais ricos tiveram apenas 1,18% de ganho, de R$ 1.775,23 para R$ 1.796,23. No mesmo período, 40% trabalhadores intermediários (a conhecida classe média) tiveram 7,75% de ganho, de R$ 342,16 para R$ 368,69.
Correio Braziliense, 23/8/2006, p. 14 (com adaptações).
Com base nas informações apresentadas no texto acima, julgue o item que se segue.
A renda média dos trabalhadores em 2006 foi superior a R$ 350,00.
A renda média dos trabalhadores em 2006 foi superior a R$ 350,00.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409122
Estatística
Texto associado
O mercado de trabalho brasileiro promoveu nos últimos quatro anos uma melhor distribuição de renda. Entre março de 2002 e junho de 2006, a participação dos 50% trabalhadores mais pobres na renda do país passou de 10,11% para 12,20%, enquanto a fatia de 10% dos trabalhadores mais ricos caiu de 49,12% para 46,89% no mesmo período. Com isso o índice de Gini recuou de 0,633 para 0,600 (quadro acima). No período de 2002 a 2006, embora ainda ganhem 23 vezes menos que os abastados, foram os trabalhadores mais pobres que tiveram melhor ganho de renda. Entre 2002 e 2006, 50% dos trabalhadores mais pobres viram sua renda média crescer 29,5%, de R$ 59,49 para R$ 77,03, enquanto que 10% dos trabalhadores mais ricos tiveram apenas 1,18% de ganho, de R$ 1.775,23 para R$ 1.796,23. No mesmo período, 40% trabalhadores intermediários (a conhecida classe média) tiveram 7,75% de ganho, de R$ 342,16 para R$ 368,69.
Correio Braziliense, 23/8/2006, p. 14 (com adaptações).
O mercado de trabalho brasileiro promoveu nos últimos quatro anos uma melhor distribuição de renda. Entre março de 2002 e junho de 2006, a participação dos 50% trabalhadores mais pobres na renda do país passou de 10,11% para 12,20%, enquanto a fatia de 10% dos trabalhadores mais ricos caiu de 49,12% para 46,89% no mesmo período. Com isso o índice de Gini recuou de 0,633 para 0,600 (quadro acima). No período de 2002 a 2006, embora ainda ganhem 23 vezes menos que os abastados, foram os trabalhadores mais pobres que tiveram melhor ganho de renda. Entre 2002 e 2006, 50% dos trabalhadores mais pobres viram sua renda média crescer 29,5%, de R$ 59,49 para R$ 77,03, enquanto que 10% dos trabalhadores mais ricos tiveram apenas 1,18% de ganho, de R$ 1.775,23 para R$ 1.796,23. No mesmo período, 40% trabalhadores intermediários (a conhecida classe média) tiveram 7,75% de ganho, de R$ 342,16 para R$ 368,69.
Correio Braziliense, 23/8/2006, p. 14 (com adaptações).
Com base nas informações apresentadas no texto acima, julgue o item que se segue.
O índice de Gini é uma razão sobre a curva de Lorenz que mede o grau de assimetria na distribuição de renda da população. Esse índice varia de zero a infinito, e quanto mais próximo de zero estiver o índice, menor será o grau de assimetria da distribuição de renda dos trabalhadores.
O índice de Gini é uma razão sobre a curva de Lorenz que mede o grau de assimetria na distribuição de renda da população. Esse índice varia de zero a infinito, e quanto mais próximo de zero estiver o índice, menor será o grau de assimetria da distribuição de renda dos trabalhadores.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409097
Estatística
Texto associado
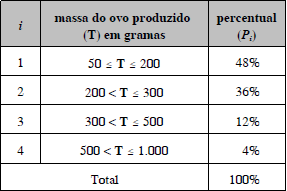
Segundo uma associação de indústrias de chocolate, em 2008 serão produzidos 100 milhões de ovos de Páscoa. A tabela acima apresenta a distribuição dos ovos segundo a massa de cada ovo e as quantidades produzidas nos anos anteriores.
Correio Braziliense, 17/2/2008, p. 26 (com adaptações).
Segundo uma associação de indústrias de chocolate, em 2008 serão produzidos 100 milhões de ovos de Páscoa. A tabela acima apresenta a distribuição dos ovos segundo a massa de cada ovo e as quantidades produzidas nos anos anteriores.
Correio Braziliense, 17/2/2008, p. 26 (com adaptações).
Com base nessas informações, julgue o item subseqüente.
Considerando-se que T é uniformemente distribuída dentro de cada intervalo de classe, a variância da distribuição T é igual a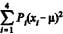 , em que xi é o ponto médio do intervalo de classe i e µ é a média de T.
, em que xi é o ponto médio do intervalo de classe i e µ é a média de T.
Considerando-se que T é uniformemente distribuída dentro de cada intervalo de classe, a variância da distribuição T é igual a
, em que xi é o ponto médio do intervalo de classe i e µ é a média de T.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409094
Estatística
Texto associado
Segundo uma associação de indústrias de chocolate, em 2008 serão produzidos 100 milhões de ovos de Páscoa. A tabela acima apresenta a distribuição dos ovos segundo a massa de cada ovo e as quantidades produzidas nos anos anteriores.
Correio Braziliense, 17/2/2008, p. 26 (com adaptações).
Segundo uma associação de indústrias de chocolate, em 2008 serão produzidos 100 milhões de ovos de Páscoa. A tabela acima apresenta a distribuição dos ovos segundo a massa de cada ovo e as quantidades produzidas nos anos anteriores.
Correio Braziliense, 17/2/2008, p. 26 (com adaptações).
Com base nessas informações, julgue o item subseqüente.
A moda da distribuição T é superior a 49,9 g e inferior a 200,1 g.
A moda da distribuição T é superior a 49,9 g e inferior a 200,1 g.
Ano: 2008
Banca:
CESPE / CEBRASPE
Órgão:
INSS
Prova:
CESPE - 2008 - INSS - Analista do Seguro Social - Estatística |
Q409093
Estatística
Texto associado
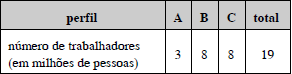
Um projeto do governo tinha como objetivo atrair para o sistema previdenciário uma parcela de trabalhadores que não eram contribuintes do INSS. Na ocasião em que tal projeto havia sido proposto, pelos cálculos do governo, existiam no país 19 milhões de trabalhadores com mais de 16 anos e renda mensal de um ou mais salários mínimos que não contribuíam para a previdência. Esses trabalhadores foram classificados de acordo com três perfis A, B e C, e a distribuição do número de trabalhadores em cada perfil está no quadro acima. A expectativa do governo era a seguinte: entre as pessoas com o perfil A, a probabilidade de entrada para o sistema previdenciário era de 0,8; para as de perfil B, a probabilidade de entrada para o sistema era de 0,5 e os de perfil C entrariam no sistema com uma probabilidade igual a 0,1.
Correio Braziliense, 15/11/2006, p. A-14 (com adaptações).
Um projeto do governo tinha como objetivo atrair para o sistema previdenciário uma parcela de trabalhadores que não eram contribuintes do INSS. Na ocasião em que tal projeto havia sido proposto, pelos cálculos do governo, existiam no país 19 milhões de trabalhadores com mais de 16 anos e renda mensal de um ou mais salários mínimos que não contribuíam para a previdência. Esses trabalhadores foram classificados de acordo com três perfis A, B e C, e a distribuição do número de trabalhadores em cada perfil está no quadro acima. A expectativa do governo era a seguinte: entre as pessoas com o perfil A, a probabilidade de entrada para o sistema previdenciário era de 0,8; para as de perfil B, a probabilidade de entrada para o sistema era de 0,5 e os de perfil C entrariam no sistema com uma probabilidade igual a 0,1.
Correio Braziliense, 15/11/2006, p. A-14 (com adaptações).
Ainda com relação ao texto e considerando que a probabilidade de dois trabalhadores selecionados aleatoriamente entre aqueles com o perfil A entrarem para o sistema previdenciário é igual a α, julgue o item subseqüente.
Dependendo do valor α, o desvio-padrão do número de trabalhadores do perfil A que serão atraídos para o sistema previdenciário pode ser superior a 1,5 milhão de pessoas.
Dependendo do valor α, o desvio-padrão do número de trabalhadores do perfil A que serão atraídos para o sistema previdenciário pode ser superior a 1,5 milhão de pessoas.
Q408882
Estatística
Com relação aos processos utilizados na modelagem de Box-Jenkins afirma-se:
I - Os modelos de média móvel MA(1) e MA(2) são sempre estacionários.
II - Os modelos autoregressivos AR(1) são sempre estacionários.
III - Um processo autoregressivo de ordem P pode ser representado por um processo de média móvel de ordem infinita.
É correto apenas o que se afirma em
I - Os modelos de média móvel MA(1) e MA(2) são sempre estacionários.
II - Os modelos autoregressivos AR(1) são sempre estacionários.
III - Um processo autoregressivo de ordem P pode ser representado por um processo de média móvel de ordem infinita.
É correto apenas o que se afirma em
Q408874
Estatística
Uma série temporal 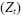 é dada por
é dada por 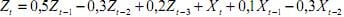 , sendo Xt um processo gaussiano branco de média nula. Essa série temporal é modelada por um processo
, sendo Xt um processo gaussiano branco de média nula. Essa série temporal é modelada por um processo
é dada por , sendo Xt um processo gaussiano branco de média nula. Essa série temporal é modelada por um processo
Q408873
Estatística
Os resultados de uma pesquisa são apresentados parcialmente na seguinte tabela.
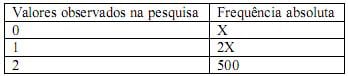
Sabendo-se que 2 é moda, o menor valor da média é
Sabendo-se que 2 é moda, o menor valor da média é
Q408872
Estatística
Uma pesquisa avalia a taxa de poupança em função da renda familiar (RF), do nível de escolaridade do chefe de família (NECF), do número de filhos (NF), da idade do chefe de família (ICF) e da intensidade de consumo familiar de bens não duráveis (CBND). Os coeficientes de correlação parcial entre a taxa de poupança e as variáveis independentes mencionadas são apresentadas na tabela a seguir.

Com base nesses resultados, as duas variáveis que permitem prever com maior precisão a taxa de poupança de uma família são:
Com base nesses resultados, as duas variáveis que permitem prever com maior precisão a taxa de poupança de uma família são: