Questões de Concurso
Foram encontradas 162 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2022
Banca:
FUNDATEC
Órgão:
AGERGS
Prova:
FUNDATEC - 2022 - AGERGS - Técnico Superior Engenheiro Mecânico |
Q1950429
Direito Ambiental
Conforme a Lei Federal nº 14.026/2020 – Marco Regulatório do saneamento básico
no Brasil, analise as seguintes assertivas:
I. Esta Lei cria o Instituto Nacional do Saneamento Básico (INSAB), entidade federal de implementação da Política Nacional de Águas e Energias, integrante do Sistema Nacional de Águas e Esgotos (Sinage). II. As taxas ou as tarifas decorrentes da prestação de serviço de limpeza urbana e de manejo de resíduos sólidos considerarão a destinação adequada dos resíduos coletados e o nível de renda da população da área atendida, de forma isolada ou combinada. III. Nos casos em que a disposição de rejeitos em aterros sanitários for economicamente inviável, poderão ser adotadas outras soluções, observadas normas técnicas e operacionais estabelecidas pelo órgão competente, de modo a evitar danos ou riscos à saúde pública e à segurança e a minimizar os impactos ambientais.
Quais estão corretas?
I. Esta Lei cria o Instituto Nacional do Saneamento Básico (INSAB), entidade federal de implementação da Política Nacional de Águas e Energias, integrante do Sistema Nacional de Águas e Esgotos (Sinage). II. As taxas ou as tarifas decorrentes da prestação de serviço de limpeza urbana e de manejo de resíduos sólidos considerarão a destinação adequada dos resíduos coletados e o nível de renda da população da área atendida, de forma isolada ou combinada. III. Nos casos em que a disposição de rejeitos em aterros sanitários for economicamente inviável, poderão ser adotadas outras soluções, observadas normas técnicas e operacionais estabelecidas pelo órgão competente, de modo a evitar danos ou riscos à saúde pública e à segurança e a minimizar os impactos ambientais.
Quais estão corretas?
Ano: 2022
Banca:
FUNDATEC
Órgão:
AGERGS
Prova:
FUNDATEC - 2022 - AGERGS - Técnico Superior Engenheiro Mecânico |
Q1950424
Estatística
Considere a tabela de renda mensal da Figura 8 abaixo:
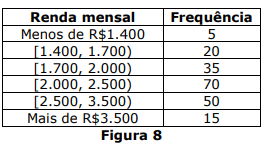
A partir da tabela, calcule o intervalo modal.
Ano: 2022
Banca:
FUNDATEC
Órgão:
AGERGS
Prova:
FUNDATEC - 2022 - AGERGS - Técnico Superior Engenheiro Mecânico |
Q1950420
Segurança e Saúde no Trabalho
Considerando a NR 12 – Segurança no Trabalho em Máquinas e Equipamentos,
assinale a alternativa correta.
Ano: 2022
Banca:
FUNDATEC
Órgão:
AGERGS
Prova:
FUNDATEC - 2022 - AGERGS - Técnico Superior Engenheiro Mecânico |
Q1950419
Segurança e Saúde no Trabalho
Segundo a NR-15 – Atividades e operações insalubres, Anexo III – Limites de
tolerância para exposição ao calor, o parâmetro para determinação de sobrecarga térmica é o:
Ano: 2022
Banca:
FUNDATEC
Órgão:
AGERGS
Prova:
FUNDATEC - 2022 - AGERGS - Técnico Superior Engenheiro Mecânico |
Q1950388
Física
Um corpo de 0,15 kg se movimenta ao longo do eixo x em um campo de forças, no
qual a energia potencial U é representada pela Figura 2 abaixo.
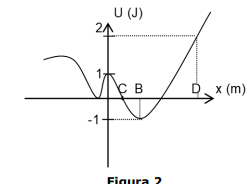
Se deixamos o corpo no ponto C a uma velocidade de 4 m/s no sentido positivo de x, qual será a energia mecânica no ponto C?
Se deixamos o corpo no ponto C a uma velocidade de 4 m/s no sentido positivo de x, qual será a energia mecânica no ponto C?
Ano: 2022
Banca:
FUNDATEC
Órgão:
AGERGS
Prova:
FUNDATEC - 2022 - AGERGS - Técnico Superior Engenheiro Civil |
Q1950375
Engenharia Civil
Com base na ABNT NBR 15575-1/2021 – Desempenho das edificações: Requisitos
gerais, desempenho acústico é um fator que expressa os requisitos do usuário relativos à:
Ano: 2022
Banca:
FUNDATEC
Órgão:
AGERGS
Prova:
FUNDATEC - 2022 - AGERGS - Técnico Superior Engenheiro Civil |
Q1950373
Engenharia Civil
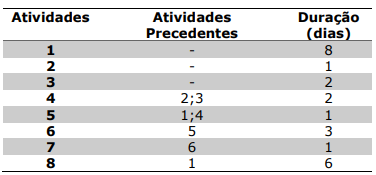
A rede PERT/CPM é uma ferramenta essencial para o gerenciamento de tempo e a
elaboração de cronograma. A partir das tarefas, das atividades precedentes e das durações
apresentadas na tabela abaixo, construa a rede PERT/CPM e assinale a alternativa que apresenta o
caminho crítico correto.
Ano: 2022
Banca:
FUNDATEC
Órgão:
AGERGS
Prova:
FUNDATEC - 2022 - AGERGS - Técnico Superior Engenheiro Civil |
Q1950365
Engenharia Civil
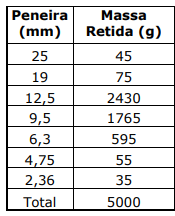
A tabela abaixo apresenta as massas retidas para cada abertura de peneira. Sobre
esse agregado, determine a dimensão máxima característica e assinale a alternativa que apresenta o
valor correto.
Ano: 2022
Banca:
FUNDATEC
Órgão:
AGERGS
Prova:
FUNDATEC - 2022 - AGERGS - Técnico Superior Engenheiro Civil |
Q1950349
Engenharia Civil
De acordo com a ABNT NBR 9050:2020 – Acessibilidade a edificações, mobiliário,
espaços e equipamentos urbanos, as obras eventualmente existentes sobre o passeio devem ser
convenientemente sinalizadas e isoladas, assegurando-se a largura mínima para circulação,
garantindo-se as condições de acesso e segurança de pedestres e de pessoas com mobilidade reduzida.
Neste sentido, assinale a alternativa que expressa corretamente o valor desta largura mínima.
Ano: 2022
Banca:
FUNDATEC
Órgão:
AGERGS
Prova:
FUNDATEC - 2022 - AGERGS - Técnico Superior Engenheiro Civil |
Q1950342
Engenharia Civil
De acordo com a ABNT NBR 6118:2014, é possível fazer análise de elementos isolados
se cumpridos alguns requisitos. De acordo com a referida norma, “Para pilares com índice de esbeltez
superior a ____, na análise dos efeitos locais de 2ª ordem, devem-se multiplicar os esforços
solicitantes finais de cálculo por um coeficiente adicional”.
Assinale a alternativa que preenche corretamente a lacuna do trecho acima.
Assinale a alternativa que preenche corretamente a lacuna do trecho acima.
Ano: 2022
Banca:
FUNDATEC
Órgão:
AGERGS
Prova:
FUNDATEC - 2022 - AGERGS - Técnico Superior Engenheiro Civil |
Q1950341
Engenharia Civil
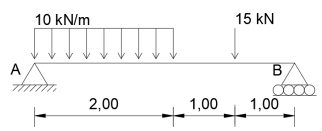
A viga ilustrada abaixo apresenta um carregamento distribuído de 10 kN/m e um
carregamento pontual de 15 kN. Acerca dos esforços internos, assinale a alternativa que apresenta
respectivamente o esforço cortante e o momento fletor em x = 2 metros contados a partir do ponto
A.
Ano: 2022
Banca:
FUNDATEC
Órgão:
AGERGS
Prova:
FUNDATEC - 2022 - AGERGS - Técnico Superior Engenheiro de Dados |
Q1949150
Engenharia de Software
Sobre os termos das características de processo de processamento de texto NLP,
analise as assertivas abaixo e assinale a alternativa correta.
I. Stopwords.
II. Tf-id+f (Term Frequency-inverse document frequency).
III. Word embedding.
IV. Word2vec.
I. Stopwords.
II. Tf-id+f (Term Frequency-inverse document frequency).
III. Word embedding.
IV. Word2vec.
Ano: 2022
Banca:
FUNDATEC
Órgão:
AGERGS
Prova:
FUNDATEC - 2022 - AGERGS - Técnico Superior Engenheiro de Dados |
Q1949149
Engenharia de Software
Sobre NLP, é INCORRETO afirmar que:
Ano: 2022
Banca:
FUNDATEC
Órgão:
AGERGS
Prova:
FUNDATEC - 2022 - AGERGS - Técnico Superior Engenheiro de Dados |
Q1949148
Sistemas Operacionais
Sobre Apache Spark, analise as assertivas abaixo e assinale a alternativa correta.
I. Similar a linguagem SQL, Spark SQLfunciona de maneira similar ao Hive, que converte códigos SQL para Map Reduce Java.
II. Spark Streaming é uma extensão do Spark, voltada para processamento de dados em tempo real, apresentando diversas propriedades interessantes, entre elas, podemos destacar a escalabilidade e a tolerância a falhas, processamento único e a possível integração entre processos batch e em tempo real.
III. O MLLib consiste em uma biblioteca de códigos de machine learning prontos e disponíveis para uso, funcionando de forma muito parecida aos pacotes do R ou ao numpy e ao scikit-learn do python.
IV. O GraphX, foi desenvolvido com o intuito de substituir os sistemas especializados de grafos que foram feitos para Hadoop, permitindo a análise e processamento de grafos em paralelo.
I. Similar a linguagem SQL, Spark SQLfunciona de maneira similar ao Hive, que converte códigos SQL para Map Reduce Java.
II. Spark Streaming é uma extensão do Spark, voltada para processamento de dados em tempo real, apresentando diversas propriedades interessantes, entre elas, podemos destacar a escalabilidade e a tolerância a falhas, processamento único e a possível integração entre processos batch e em tempo real.
III. O MLLib consiste em uma biblioteca de códigos de machine learning prontos e disponíveis para uso, funcionando de forma muito parecida aos pacotes do R ou ao numpy e ao scikit-learn do python.
IV. O GraphX, foi desenvolvido com o intuito de substituir os sistemas especializados de grafos que foram feitos para Hadoop, permitindo a análise e processamento de grafos em paralelo.
Ano: 2022
Banca:
FUNDATEC
Órgão:
AGERGS
Prova:
FUNDATEC - 2022 - AGERGS - Técnico Superior Engenheiro de Dados |
Q1949147
Programação
São exemplos de operações de transformação em Spark, EXCETO:
Ano: 2022
Banca:
FUNDATEC
Órgão:
AGERGS
Prova:
FUNDATEC - 2022 - AGERGS - Técnico Superior Engenheiro de Dados |
Q1949146
Programação
A programação em Spark se baseia no conceito de RDD’s. Os RDD’s são a unidade
fundamental de dados no Spark e têm como principal característica a propriedade de ser imutável.
Sobre os RDD’s, é correto afirmar que:
Ano: 2022
Banca:
FUNDATEC
Órgão:
AGERGS
Prova:
FUNDATEC - 2022 - AGERGS - Técnico Superior Engenheiro de Dados |
Q1949145
Sistemas Operacionais
Sobre Apache Spark, analise as assertivas abaixo e assinale a alternativa correta.
I. De forma geral, o Spark é uma engine rápida, escrita em Scala, para processamento de grandes volumes de dados em um cluster de computadores.
II. Scala é uma linguagem funcional que roda na JVM.
III. O Spark, assim como o Hadoop, também foi pensado para ser escalável.
IV. Umas das grandes vantagens do Spark em relação ao Hadoop são as High Level API’s de programação. Enquanto que o Hadoop é nativamente apenas Java, no Spark, temos a disposição API ’s em Scala, Java e Python.
I. De forma geral, o Spark é uma engine rápida, escrita em Scala, para processamento de grandes volumes de dados em um cluster de computadores.
II. Scala é uma linguagem funcional que roda na JVM.
III. O Spark, assim como o Hadoop, também foi pensado para ser escalável.
IV. Umas das grandes vantagens do Spark em relação ao Hadoop são as High Level API’s de programação. Enquanto que o Hadoop é nativamente apenas Java, no Spark, temos a disposição API ’s em Scala, Java e Python.
Ano: 2022
Banca:
FUNDATEC
Órgão:
AGERGS
Prova:
FUNDATEC - 2022 - AGERGS - Técnico Superior Engenheiro de Dados |
Q1949144
Engenharia de Software
A ideia principal da técnica de “dropout” é descartar aleatoriamente unidades da rede
neural (junto com suas conexões) durante a etapa de treinamento. Sobre a técnica de “dropout”,
assinale a alternativa INCORRETA.
Ano: 2022
Banca:
FUNDATEC
Órgão:
AGERGS
Prova:
FUNDATEC - 2022 - AGERGS - Técnico Superior Engenheiro de Dados |
Q1949143
Banco de Dados
Uma função de perda mede a diferença entre uma predição do valor alvo e o valor
disponível no conjunto de treinamento. Sobre o assunto, assinale a alternativa INCORRETA.
Ano: 2022
Banca:
FUNDATEC
Órgão:
AGERGS
Prova:
FUNDATEC - 2022 - AGERGS - Técnico Superior Engenheiro de Dados |
Q1949142
Engenharia de Software
Recentemente, encontram-se muitas referências na literatura e na mídia em geral
ao uso de aprendizagem profunda (ou “deep learning”). Sobre o assunto, assinale a alternativa
INCORRETA.