Questões de Concurso
Para brde
Foram encontradas 1.201 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2012
Banca:
AOCP
Órgão:
BRDE
Prova:
AOCP - 2012 - BRDE - Analista de Sistemas - Administrador de Banco de Dados |
Q234314
Banco de Dados
Assinale a alternativa que define corretamente o comando DROP na Linguagem SQL-99.
Ano: 2012
Banca:
AOCP
Órgão:
BRDE
Prova:
AOCP - 2012 - BRDE - Analista de Sistemas - Administrador de Banco de Dados |
Q234313
Banco de Dados
Preencha as lacunas e, em seguida, assinale a alternativa correta. Em SQL-99 temos o tipo de dados de atributos ________________, os tipos de dados cadeia de caracteres ou tem tamanho_________ – CHAR(n) ou _______________, em que n é o numero de caracteres – ou tem tamanho _____________ VARCHAR(n) ou CHAR VARIYNG ou CHARACTER VARIYNG(n), em que n é o número máximo de caracteres.
Ano: 2012
Banca:
AOCP
Órgão:
BRDE
Prova:
AOCP - 2012 - BRDE - Analista de Sistemas - Administrador de Banco de Dados |
Q234312
Banco de Dados
Sobre a linguagem SQL, analise as assertivas e assinale a alternativa que aponta a(s) correta(s).
I. O nome da SQL é derivado de Structured Query Language (Linguagem estruturada de consulta), foi chamada inicialmente de SEQUEL (Structured English QUEry Language – Linguagem de Pesquisa em Inglês Estruturado).
II. O núcleo da especificação SQL deve ser implementado por todos os vendedores de SGBDs relacionais, compatíveis com o padrão.
III. Essa linguagem tem funcionalidades, como definição de visões, no banco de dados.
IV. A SQL é uma linguagem de banco de dados abrangente: ela possui comandos para definição de dados, consulta e atualizações. Assim ela tem ambas as DDL e DML.
I. O nome da SQL é derivado de Structured Query Language (Linguagem estruturada de consulta), foi chamada inicialmente de SEQUEL (Structured English QUEry Language – Linguagem de Pesquisa em Inglês Estruturado).
II. O núcleo da especificação SQL deve ser implementado por todos os vendedores de SGBDs relacionais, compatíveis com o padrão.
III. Essa linguagem tem funcionalidades, como definição de visões, no banco de dados.
IV. A SQL é uma linguagem de banco de dados abrangente: ela possui comandos para definição de dados, consulta e atualizações. Assim ela tem ambas as DDL e DML.
Ano: 2012
Banca:
AOCP
Órgão:
BRDE
Prova:
AOCP - 2012 - BRDE - Analista de Sistemas - Administrador de Banco de Dados |
Q234311
Banco de Dados
Preencha as lacunas e, em seguida, assinale a alternativa correta. No ______________, escrevemos uma expressão _____________ para expressar um requisito de recuperação, portanto não será feita nenhuma descrição de como uma consulta se desenvolve. Uma ________________ especifica o que será recuperado, em vez de como recuperá-lo.
Ano: 2012
Banca:
AOCP
Órgão:
BRDE
Prova:
AOCP - 2012 - BRDE - Analista de Sistemas - Administrador de Banco de Dados |
Q234310
Banco de Dados
Sobre Funções agregadas e Agrupamento, analise as assertivas e assinale a alternativa que aponta a(s) correta(s).
I. O agrupamento de tuplas em uma relação, a partir do valor de alguns de seus atributos não costuma ser uma necessidade frequente para aplicação de uma função de agregação.
II. O primeiro tipo de requisito que não pode ser expresso na álgebra relacional básica é para especificar as funções matemáticas agregadas em coleções de valores do banco de dados.
III. As funções mais comuns aplicadas em coleção de valores numéricos incluem SOMA, MÉDIA, MÁXIMO e MÍNIMO.
IV. Essas funções podem ser utilizadas em consultas de estatística simples, que resumem as informações das tuplas do banco de dados.
I. O agrupamento de tuplas em uma relação, a partir do valor de alguns de seus atributos não costuma ser uma necessidade frequente para aplicação de uma função de agregação.
II. O primeiro tipo de requisito que não pode ser expresso na álgebra relacional básica é para especificar as funções matemáticas agregadas em coleções de valores do banco de dados.
III. As funções mais comuns aplicadas em coleção de valores numéricos incluem SOMA, MÉDIA, MÁXIMO e MÍNIMO.
IV. Essas funções podem ser utilizadas em consultas de estatística simples, que resumem as informações das tuplas do banco de dados.
Ano: 2012
Banca:
AOCP
Órgão:
BRDE
Prova:
AOCP - 2012 - BRDE - Analista de Sistemas - Administrador de Banco de Dados |
Q234309
Banco de Dados
Sobre Junções (JOIN), analise as assertivas e assinale a alternativa que aponta a(s) correta(s).
I. A operação de junção é utilizada para combinar as tuplas relacionadas em duas relações dentro de uma única.
II. Junções podem ser criadas através do aninhamento das operações, ou podemos aplicar uma operação por vez e criar relação dos resultados intermediários.
III. Junções são muito importantes em banco de dados relacionais com mais de uma relação, porque nos permite processar os relacionamentos entre as relações.
IV. Na Junção apenas as combinações de tuplas que satisfazerem a condição de junção aparecerão no resultado, enquanto, no produto Cartesiano, todas as combinações de tuplas serão incluídas no resultado.
I. A operação de junção é utilizada para combinar as tuplas relacionadas em duas relações dentro de uma única.
II. Junções podem ser criadas através do aninhamento das operações, ou podemos aplicar uma operação por vez e criar relação dos resultados intermediários.
III. Junções são muito importantes em banco de dados relacionais com mais de uma relação, porque nos permite processar os relacionamentos entre as relações.
IV. Na Junção apenas as combinações de tuplas que satisfazerem a condição de junção aparecerão no resultado, enquanto, no produto Cartesiano, todas as combinações de tuplas serão incluídas no resultado.
Ano: 2012
Banca:
AOCP
Órgão:
BRDE
Prova:
AOCP - 2012 - BRDE - Analista de Sistemas - Administrador de Banco de Dados |
Q234308
Banco de Dados
Sobre Integridade de Entidade, Integridade Referencial e Chave Estrangeira em Entidade e Relacionamentos, analise as assertivas e assinale a alternativa que aponta a(s) correta(s).
I. A restrição de integridade de entidade estabelece que nenhum valor de chave primária pode ser null. Isso porque o valor da chave primária é usado para identificar as tuplas individuais em uma relação.
II. Todas as restrições de integridade deveriam ser especificadas no esquema do banco de dados relacional, caso queiramos impor essas restrições aos estados do banco de dados.
III. Ter valores null para chave primária implica não podermos identificar alguma tupla.
IV. A restrição de integridade referencial é classificada entre duas relações e é usada para manter a consistência entre as tuplas nas duas relações.
I. A restrição de integridade de entidade estabelece que nenhum valor de chave primária pode ser null. Isso porque o valor da chave primária é usado para identificar as tuplas individuais em uma relação.
II. Todas as restrições de integridade deveriam ser especificadas no esquema do banco de dados relacional, caso queiramos impor essas restrições aos estados do banco de dados.
III. Ter valores null para chave primária implica não podermos identificar alguma tupla.
IV. A restrição de integridade referencial é classificada entre duas relações e é usada para manter a consistência entre as tuplas nas duas relações.
Ano: 2012
Banca:
AOCP
Órgão:
BRDE
Prova:
AOCP - 2012 - BRDE - Analista de Sistemas - Administrador de Banco de Dados |
Q234307
Banco de Dados
Sobre Tipo Entidade Fraca, analise as assertivas e assinale a alternativa que aponta a(s) correta(s).
I. Tipo Entidade Fraca também são conhecidas por Entidades abstratas.
II. Tipo entidade que não tem seus próprios atributos-chave são chamados tipos entidade fraca.
III. Tipo entidade que não tem seus próprios relacionamentos são chamados tipo entidade fraca.
IV. Entidades, que pertençam a um tipo entidade fraca, são identificadas por estarem relacionadas a entidades específicas do outro tipo entidade.
I. Tipo Entidade Fraca também são conhecidas por Entidades abstratas.
II. Tipo entidade que não tem seus próprios atributos-chave são chamados tipos entidade fraca.
III. Tipo entidade que não tem seus próprios relacionamentos são chamados tipo entidade fraca.
IV. Entidades, que pertençam a um tipo entidade fraca, são identificadas por estarem relacionadas a entidades específicas do outro tipo entidade.
Ano: 2012
Banca:
AOCP
Órgão:
BRDE
Prova:
AOCP - 2012 - BRDE - Analista de Sistemas - Administrador de Banco de Dados |
Q234306
Banco de Dados
Sobre Grau de relacionamento, Nomes de papéis e Relacionamentos recursivos, analise as assertivas e assinale a alternativa que aponta a(s) correta(s).
I. O grau de um tipo relacionamento é o número de entidade que participa desse relacionamento.
II. Um tipo relacionamento de grau vinte é chamado de binário e um de grau trinta é ternário.
III. Os nomes de papéis são tecnicamente necessários em tipos relacionamentos em que todos os tipos entidades participantes são distintos.
IV. Cada tipo entidade que participa de um tipo relacionamento executa um papel particular no relacionamento. O nome do papel significa o papel que uma entidade participante de um tipo entidade executa em cada instância de relacionamento, e ajuda explicar o significado do relacionamento.
I. O grau de um tipo relacionamento é o número de entidade que participa desse relacionamento.
II. Um tipo relacionamento de grau vinte é chamado de binário e um de grau trinta é ternário.
III. Os nomes de papéis são tecnicamente necessários em tipos relacionamentos em que todos os tipos entidades participantes são distintos.
IV. Cada tipo entidade que participa de um tipo relacionamento executa um papel particular no relacionamento. O nome do papel significa o papel que uma entidade participante de um tipo entidade executa em cada instância de relacionamento, e ajuda explicar o significado do relacionamento.
Ano: 2012
Banca:
AOCP
Órgão:
BRDE
Prova:
AOCP - 2012 - BRDE - Analista de Sistemas - Administrador de Banco de Dados |
Q234305
Banco de Dados
Em Modelo de Entidade de Relacionamento, possuímos entidades e atributos. A esse respeito, analise as assertivas e assinale a alternativa que aponta a(s) correta(s).
I. O objeto básico de um MER é uma entidade, 'algo' do mundo real, com uma existência independente.
II. Uma entidade pode ser um objeto com uma existência física (por exemplo, uma pessoa, um carro, uma casa ou um funcionário) ou um objeto com uma existência conceitual (por exemplo, uma empresa, um trabalho ou um curso universitário).
III. Os valores dos atributos que descrevem cada entidade se tornarão a maior parte dos dados armazenados no banco de dados.
IV. Cada entidade tem atributos – propriedades particulares que a descrevem. Por exemplo, uma entidade empregada pode ser descrita pelo nome do empregado, idade, endereço, salário e trabalho (função).
I. O objeto básico de um MER é uma entidade, 'algo' do mundo real, com uma existência independente.
II. Uma entidade pode ser um objeto com uma existência física (por exemplo, uma pessoa, um carro, uma casa ou um funcionário) ou um objeto com uma existência conceitual (por exemplo, uma empresa, um trabalho ou um curso universitário).
III. Os valores dos atributos que descrevem cada entidade se tornarão a maior parte dos dados armazenados no banco de dados.
IV. Cada entidade tem atributos – propriedades particulares que a descrevem. Por exemplo, uma entidade empregada pode ser descrita pelo nome do empregado, idade, endereço, salário e trabalho (função).
Ano: 2012
Banca:
AOCP
Órgão:
BRDE
Prova:
AOCP - 2012 - BRDE - Analista de Sistemas - Administrador de Banco de Dados |
Q234304
Banco de Dados
Sobre a linguagem de SGBD, analise as assertivas e assinale a alternativa que aponta a(s) correta(s).
I. Alguns SGBDs fornecem uma linguagem chamada linguagem de manipulação de dados - data manipulation language (DML) .
II. Em vários SGBDs foi escolhido, nos quais não existem uma separação específica de níveis, uma linguagem chamada linguagem de definição de dados – Data Definition Language (DDL), que é usada pelo DBA e pelos projetistas de banco de dados para definir ambos os esquemas.
III. Nos SGBDs, em que uma clara separação é mantida entre níveis conceitual e interno, a DDL é usada para especificar somente o esquema conceitual. A linguagem de definição de Armazenamento – storage definition language (SDL), é utilizada para especificar o esquema interno.
IV. A grande maioria dos SGBDs não fornecem suporte a essa linguagem diretamente, com isso a utilização das mesmas se fazem somente através de uma linguagem de programação auxiliar, como java, c++ entre outras.
I. Alguns SGBDs fornecem uma linguagem chamada linguagem de manipulação de dados - data manipulation language (DML) .
II. Em vários SGBDs foi escolhido, nos quais não existem uma separação específica de níveis, uma linguagem chamada linguagem de definição de dados – Data Definition Language (DDL), que é usada pelo DBA e pelos projetistas de banco de dados para definir ambos os esquemas.
III. Nos SGBDs, em que uma clara separação é mantida entre níveis conceitual e interno, a DDL é usada para especificar somente o esquema conceitual. A linguagem de definição de Armazenamento – storage definition language (SDL), é utilizada para especificar o esquema interno.
IV. A grande maioria dos SGBDs não fornecem suporte a essa linguagem diretamente, com isso a utilização das mesmas se fazem somente através de uma linguagem de programação auxiliar, como java, c++ entre outras.
Ano: 2012
Banca:
AOCP
Órgão:
BRDE
Prova:
AOCP - 2012 - BRDE - Analista de Sistemas - Administrador de Banco de Dados |
Q234303
Sistemas Operacionais
Em gerência de memória, temos vários tipos de alocação. Analise as assertivas e assinale a alternativa que aponta a(s) correta(s) sobre alocação contígua simples.
I. A alocação contígua simples foi implementada nos primeiros sistemas operacionais desenvolvidos, porém ainda está presente em alguns sistemas monoprogramáveis.
II. Com a alocação contígua foi eliminado o conceito de partições de tamanho fixo.
III. Neste tipo de alocação, o tamanho das partições eram estabelecidas no momento da inicialização do sistema, em função do tamanho dos programas que executariam no ambiente.
IV. Na alocação contígua simples a memória principal é divida em duas partes: uma para o sistema operacional e outra para o programa do usuário.
I. A alocação contígua simples foi implementada nos primeiros sistemas operacionais desenvolvidos, porém ainda está presente em alguns sistemas monoprogramáveis.
II. Com a alocação contígua foi eliminado o conceito de partições de tamanho fixo.
III. Neste tipo de alocação, o tamanho das partições eram estabelecidas no momento da inicialização do sistema, em função do tamanho dos programas que executariam no ambiente.
IV. Na alocação contígua simples a memória principal é divida em duas partes: uma para o sistema operacional e outra para o programa do usuário.
Ano: 2012
Banca:
AOCP
Órgão:
BRDE
Prova:
AOCP - 2012 - BRDE - Analista de Sistemas - Administrador de Banco de Dados |
Q234302
Arquitetura de Computadores
Sobre Discos Magnéticos, analise as assertivas e assinale a alternativa que aponta a(s) correta(s).
I. Entre os diversos dispositivos de entrada/saída, os discos magnéticos merecem atenção especial, por serem o depositório de dados da grande maioria das aplicações comerciais. Como o fator tempo é crucial no acesso a esses dados, aspectos como desempenho e segurança devem ser considerados.
II. O tempo seek é o tempo de espera até que o setor desejado se posicione sob a cabeça de leitura/gravação.
III. Na realidade, um disco magnético é constituído por vários discos sobrepostos, unidos por um eixo vertical, girando a uma velocidade constante.
IV. O tempo necessário para ler/gravar um bloco de dados de/para o disco é função de três fatores: tempo de seek, latência e transferência.
I. Entre os diversos dispositivos de entrada/saída, os discos magnéticos merecem atenção especial, por serem o depositório de dados da grande maioria das aplicações comerciais. Como o fator tempo é crucial no acesso a esses dados, aspectos como desempenho e segurança devem ser considerados.
II. O tempo seek é o tempo de espera até que o setor desejado se posicione sob a cabeça de leitura/gravação.
III. Na realidade, um disco magnético é constituído por vários discos sobrepostos, unidos por um eixo vertical, girando a uma velocidade constante.
IV. O tempo necessário para ler/gravar um bloco de dados de/para o disco é função de três fatores: tempo de seek, latência e transferência.
Ano: 2012
Banca:
AOCP
Órgão:
BRDE
Prova:
AOCP - 2012 - BRDE - Analista de Sistemas - Administrador de Banco de Dados |
Q234301
Arquitetura de Computadores
Sobre Pipeline, analise as assertivas e assinale a alternativa que aponta as corretas.
I. A técnica de pipelining pode ser empregada em sistemas com um ou mais processadores, em diversos níveis, e tem sido a técnica de paralelismo mais utilizada para maior desempenho dos sistemas de computadores.
II. O conceito de processamento pipeline se assemelha muito a uma linha de montagem, onde uma tarefa é dividida em um sequência de sub tarefas, executadas em diferentes estágios, dentro da linha de produção.
III. O conceito de processamento pipeline só pode ser implementado dentro da arquitetura de processadores RISC.
IV. Nos sistemas operacionais antigos, o pipeline era bastante complicado, já que os programadores deveriam possuir conhecimento de hardware e programar em painéis através de fios.
I. A técnica de pipelining pode ser empregada em sistemas com um ou mais processadores, em diversos níveis, e tem sido a técnica de paralelismo mais utilizada para maior desempenho dos sistemas de computadores.
II. O conceito de processamento pipeline se assemelha muito a uma linha de montagem, onde uma tarefa é dividida em um sequência de sub tarefas, executadas em diferentes estágios, dentro da linha de produção.
III. O conceito de processamento pipeline só pode ser implementado dentro da arquitetura de processadores RISC.
IV. Nos sistemas operacionais antigos, o pipeline era bastante complicado, já que os programadores deveriam possuir conhecimento de hardware e programar em painéis através de fios.
Ano: 2012
Banca:
AOCP
Órgão:
BRDE
Prova:
AOCP - 2012 - BRDE - Analista de Sistemas - Administrador de Banco de Dados |
Q234300
Sistemas Operacionais
Sobre correção de um Deadlock, analise as assertivas e assinale a alternativa que aponta a(s) correta(s).
I. Após a detecção do deadlock, o sistema deverá corrigir o problema. Uma solução bastante utilizada pela maioria dos sistemas operacionais é, simplesmente, eliminar um ou mais processos envolvidos no deadlock e desalocar os recursos já garantidos por eles, quebrando assim a espera circular.
II. Um deadlock não tem correção, uma vez que o processo em execução aguarda um evento que nunca mais ocorrerá. O sistema operacional deve ser apto a identificar e eliminar um processo em deadlock.
III. Uma solução menos drástica envolve a liberação de apenas alguns recursos alocados aos processo para outros processos, até que o ciclo de espera termine.
IV. A eliminação dos processo envolvidos no deadlock e, consequentemente, a liberação de seus recursos podem não ser simples, dependendo do tipo do recurso envolvido.
I. Após a detecção do deadlock, o sistema deverá corrigir o problema. Uma solução bastante utilizada pela maioria dos sistemas operacionais é, simplesmente, eliminar um ou mais processos envolvidos no deadlock e desalocar os recursos já garantidos por eles, quebrando assim a espera circular.
II. Um deadlock não tem correção, uma vez que o processo em execução aguarda um evento que nunca mais ocorrerá. O sistema operacional deve ser apto a identificar e eliminar um processo em deadlock.
III. Uma solução menos drástica envolve a liberação de apenas alguns recursos alocados aos processo para outros processos, até que o ciclo de espera termine.
IV. A eliminação dos processo envolvidos no deadlock e, consequentemente, a liberação de seus recursos podem não ser simples, dependendo do tipo do recurso envolvido.
Ano: 2012
Banca:
AOCP
Órgão:
BRDE
Prova:
AOCP - 2012 - BRDE - Analista de Sistemas - Administrador de Banco de Dados |
Q234299
Sistemas Operacionais
Em sistemas operacionais, encontramos uma série de algoritmos de escalonamento para facilitar o gerenciamento de processador. Analise as assertivas e assinale a alternativa que aponta a(s) correta(s) sobre o escalonamento Shortest-Job- First e o escalonamento Preemptivo.
I. O escalonamento Shortest-Job-First associa cada processo (ou job) ao seu tempo de execução. Dessa forma, quando o processador está livre, o processo em estado de pronto que precisar de menos tempo de UCP para terminar seu processamento é selecionado para execução.
II. O escalonamento Shortest-Job-First favorece os processos que executam programas menores, além de reduzir o tempo médio de espera em relação ao FIFO.
III. O escalonamento preemptivo permite que o sistema dê atenção imediata a processos mais prioritários, como no caso de sistemas de tempo real, além de proporcionar melhores tempos de respostas em sistemas de tempo compartilhado.
IV. Um algoritmo de escalonamento é dito preemptivo quando o sistema pode interromper um processo em execução para que outro processo utilize o processador.
I. O escalonamento Shortest-Job-First associa cada processo (ou job) ao seu tempo de execução. Dessa forma, quando o processador está livre, o processo em estado de pronto que precisar de menos tempo de UCP para terminar seu processamento é selecionado para execução.
II. O escalonamento Shortest-Job-First favorece os processos que executam programas menores, além de reduzir o tempo médio de espera em relação ao FIFO.
III. O escalonamento preemptivo permite que o sistema dê atenção imediata a processos mais prioritários, como no caso de sistemas de tempo real, além de proporcionar melhores tempos de respostas em sistemas de tempo compartilhado.
IV. Um algoritmo de escalonamento é dito preemptivo quando o sistema pode interromper um processo em execução para que outro processo utilize o processador.
Ano: 2012
Banca:
AOCP
Órgão:
BRDE
Prova:
AOCP - 2012 - BRDE - Analista de Sistemas - Administrador de Banco de Dados |
Q234298
Sistemas Operacionais
Há um critério de escalonamento chamado Tempo de resposta. Sobre esse critério, analise as assertivas e assinale a alternativa que aponta a(s) correta(s).
I. Em sistemas interativos, o tempo de respostas é o tempo decorrido do momento da submissão de um pedido ao sistema até a primeira resposta produzida.
II. De uma maneira geral, qualquer algoritmo de escalonamento busca otimizar a utilização da UCP e o throughput, enquanto tenta diminuir os tempos de turnaround e de resposta. Dependendo do tipo do sistema, um critério pode ser mais enfatizado do que outros, como, por exemplo, nos sistemas interativos, onde o tempo de resposta deve ser mais considerado.
III. Tempo de resposta não é considerado um critério de escalonamento, uma vez que o tempo de resposta envolve muitos outros fatores em um sistema operacional.
IV. O tempo de resposta é o tempo total utilizado no processamento completo de uma determinada tarefa.
I. Em sistemas interativos, o tempo de respostas é o tempo decorrido do momento da submissão de um pedido ao sistema até a primeira resposta produzida.
II. De uma maneira geral, qualquer algoritmo de escalonamento busca otimizar a utilização da UCP e o throughput, enquanto tenta diminuir os tempos de turnaround e de resposta. Dependendo do tipo do sistema, um critério pode ser mais enfatizado do que outros, como, por exemplo, nos sistemas interativos, onde o tempo de resposta deve ser mais considerado.
III. Tempo de resposta não é considerado um critério de escalonamento, uma vez que o tempo de resposta envolve muitos outros fatores em um sistema operacional.
IV. O tempo de resposta é o tempo total utilizado no processamento completo de uma determinada tarefa.
Ano: 2012
Banca:
AOCP
Órgão:
BRDE
Prova:
AOCP - 2012 - BRDE - Analista de Sistemas - Administrador de Banco de Dados |
Q234297
Sistemas Operacionais
Sobre critérios de escalonamento em gerência de processador, analise as assertivas e assinale a alternativa que aponta a(s) correta(s).
I. Um algoritmo de escalonamento tem como principal função decidir qual dos processos prontos para execução deve ser alocado à UCP. Cada sistema operacional necessita de um algoritmo de escalonamento adequado a seu tipo de processamento.
II. Na maioria dos sistemas é desejável que o processador permaneça a maior parte do seu tempo ocupado. Uma utilização na faixa de 30% indica um sistema com uma carga de processamento baixa.
III. O throughput representa o número de processos (tarefas) executados em um determinado intervalo de tempo. Quanto maior o throughput, maior o número de tarefas executadas em função do tempo. A maximização do throughput é desejada na maioria dos sistemas.
IV. O tempo que um processo leva desde sua admissão no sistema até ao seu término, não levando em consideração o tempo de espera para alocação de memória, espera na fila de processos prontos para execução, processamento na UCP e operações E/S, chama-se Tempo de turnaround.
I. Um algoritmo de escalonamento tem como principal função decidir qual dos processos prontos para execução deve ser alocado à UCP. Cada sistema operacional necessita de um algoritmo de escalonamento adequado a seu tipo de processamento.
II. Na maioria dos sistemas é desejável que o processador permaneça a maior parte do seu tempo ocupado. Uma utilização na faixa de 30% indica um sistema com uma carga de processamento baixa.
III. O throughput representa o número de processos (tarefas) executados em um determinado intervalo de tempo. Quanto maior o throughput, maior o número de tarefas executadas em função do tempo. A maximização do throughput é desejada na maioria dos sistemas.
IV. O tempo que um processo leva desde sua admissão no sistema até ao seu término, não levando em consideração o tempo de espera para alocação de memória, espera na fila de processos prontos para execução, processamento na UCP e operações E/S, chama-se Tempo de turnaround.
Ano: 2012
Banca:
AOCP
Órgão:
BRDE
Provas:
AOCP - 2012 - BRDE - Analista de Sistemas - Desenvolvimento de Sistemas - (Prova TIPO 4)
|
AOCP - 2012 - BRDE - Analista de Sistemas - Administrador de Banco de Dados |
AOCP - 2012 - BRDE - Analista de Sistemas - Suporte |
AOCP - 2012 - BRDE - Analista de Projetos - Jurídica |
AOCP - 2012 - BRDE - Analista de Projetos - Agronomia |
AOCP - 2012 - BRDE - Analista de Projetos - Econômico-Financeira |
AOCP - 2012 - BRDE - Analista de Projetos - Engenharia |
Q234296
Atualidades
Sobre as políticas indigenistas oficiais e as políticas reivindicatórias dos grupos indígenas, no Brasil e em outros países da América do Sul, como o Peru e Bolívia, assinale a alternativa correta.
Ano: 2012
Banca:
AOCP
Órgão:
BRDE
Provas:
AOCP - 2012 - BRDE - Analista de Sistemas - Desenvolvimento de Sistemas - (Prova TIPO 4)
|
AOCP - 2012 - BRDE - Analista de Sistemas - Administrador de Banco de Dados |
AOCP - 2012 - BRDE - Analista de Sistemas - Suporte |
AOCP - 2012 - BRDE - Analista de Projetos - Jurídica |
AOCP - 2012 - BRDE - Analista de Projetos - Agronomia |
AOCP - 2012 - BRDE - Analista de Projetos - Econômico-Financeira |
AOCP - 2012 - BRDE - Analista de Projetos - Engenharia |
Q234294
Raciocínio Lógico
Considere a sequência infinita 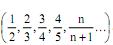
Qual é o seu limite quando n → ∞ ?
Qual é o seu limite quando n → ∞ ?