Questões de Concurso
Sobre modelos lineares em estatística
Foram encontradas 578 questões
I. É utilizado para testar a homocedasticidade das variâncias dos erros. II. A rejeição da hipótese nula do teste é baseada na distribuição F. III. Antes de realizar testes paramétricos, como o teste t de Student, ele é usado para garantir que as suposições subjacentes desses testes estão sendo atendidas.
Está correto o que se afirma em
I. A nota média do aluno cresce linearmente com relação a sua idade.
II. A nota média do aluno cresce linearmente com relação a sua renda familiar per capita.
III. A média da nota do aluno difere entre os dois sexos.
IV. O efeito linear da renda familiar per capita na nota não é o mesmo para qualquer idade, e vive-versa.
V. O efeito linear do sexo do aluno na nota é o mesmo para qualquer idade e renda familiar per capita.
Considerando as conclusões anteriores, marque a alternativa que corresponde a uma possível representação da estrutura do modelo final apresentado ao diretor-geral.
y = β0 + β1x +∈
Dado: ∈ representa o erro aleatório.
De acordo com esse modelo,
Em uma análise dos resultados das urnas eleitorais, decidiu-se verificar quais variáveis estão mais relacionadas ao voto em candidatos de direita ou de esquerda. Os votos para os candidatos de direita e de esquerda foram analisados em separado para as 27 unidades da federação (UF), tendo como variáveis explicativas a idade (x1) e os anos de estudo (x2) dos eleitores. Em cada UF, foram analisados os votos de y eleitores e as estatísticas descritivas das variáveis utilizadas são mostradas na tabela a seguir.
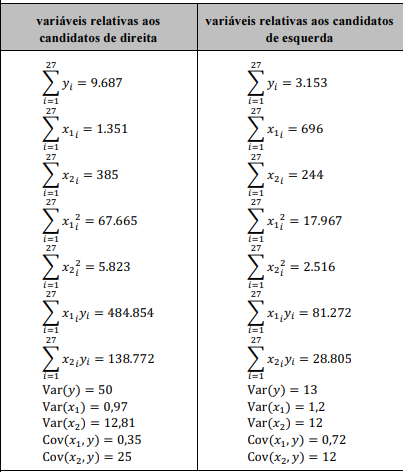
Com base nessas informações, julgue o próximo item.
Os resíduos do modelo 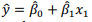 para os votantes em
candidatos de direita pode ser corretamente calculado
fazendo-se
para os votantes em
candidatos de direita pode ser corretamente calculado
fazendo-se 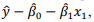 , onde
, onde 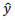 é o valor estimado de y,
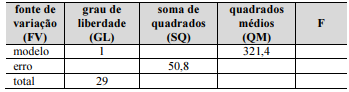
é o valor estimado de y, 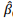 0 é o coeficiente linear estimado do modelo e 1 é o
coeficiente linear estimado do modelo.
0 é o coeficiente linear estimado do modelo e 1 é o
coeficiente linear estimado do modelo.
Em uma análise dos resultados das urnas eleitorais, decidiu-se verificar quais variáveis estão mais relacionadas ao voto em candidatos de direita ou de esquerda. Os votos para os candidatos de direita e de esquerda foram analisados em separado para as 27 unidades da federação (UF), tendo como variáveis explicativas a idade (x1) e os anos de estudo (x2) dos eleitores. Em cada UF, foram analisados os votos de y eleitores e as estatísticas descritivas das variáveis utilizadas são mostradas na tabela a seguir.
Com base nessas informações, julgue o próximo item.
Como a Cov(x2, y) > 0 para a quantidade de votos em
candidatos de esquerda, então, para o modelo de regressão
linear simples de y em que apenas a varável x2 fosse
considerada, necessariamente o coeficiente angular referente
à variável x2 seria maior que zero.
Em uma análise dos resultados das urnas eleitorais, decidiu-se verificar quais variáveis estão mais relacionadas ao voto em candidatos de direita ou de esquerda. Os votos para os candidatos de direita e de esquerda foram analisados em separado para as 27 unidades da federação (UF), tendo como variáveis explicativas a idade (x1) e os anos de estudo (x2) dos eleitores. Em cada UF, foram analisados os votos de y eleitores e as estatísticas descritivas das variáveis utilizadas são mostradas na tabela a seguir.
Com base nessas informações, julgue o próximo item.
Se, para os votantes em candidatos de direita, o valor daestatística F do modelo y = β0 + β1x2 + ∈ tiver valor iguala 640, então o valor da estatística t para a variável x2 terávalor superior a 30, onde β0 é o coeficiente linear domodelo, β1 é o coeficiente linear do modelo e ∈ é o erro.
Em uma análise dos resultados das urnas eleitorais, decidiu-se verificar quais variáveis estão mais relacionadas ao voto em candidatos de direita ou de esquerda. Os votos para os candidatos de direita e de esquerda foram analisados em separado para as 27 unidades da federação (UF), tendo como variáveis explicativas a idade (x1) e os anos de estudo (x2) dos eleitores. Em cada UF, foram analisados os votos de y eleitores e as estatísticas descritivas das variáveis utilizadas são mostradas na tabela a seguir.
Com base nessas informações, julgue o próximo item.
Se as variáveis x1 e x2 fossem incluídas simultaneamente no
modelo e o coeficiente angular referente à variável x2 fosse
maior que zero, mas não significativo para um nível de
significância de 5%, então, nesse caso, as estimativas dos
coeficientes linear e angular referentes à variável x1 seriam
as mesmas do modelo em que apenas a variável x1 estivesse
presente.
Em uma análise dos resultados das urnas eleitorais, decidiu-se verificar quais variáveis estão mais relacionadas ao voto em candidatos de direita ou de esquerda. Os votos para os candidatos de direita e de esquerda foram analisados em separado para as 27 unidades da federação (UF), tendo como variáveis explicativas a idade (x1) e os anos de estudo (x2) dos eleitores. Em cada UF, foram analisados os votos de y eleitores e as estatísticas descritivas das variáveis utilizadas são mostradas na tabela a seguir.
Com base nessas informações, julgue o próximo item.
Se a quantidade de votos fosse considerada apenas aquela da
variável x2, então o coeficiente linear dos votantes em
candidatos de esquerda seria maior que o coeficiente linear
dos votantes em candidatos de direita.
Em uma análise dos resultados das urnas eleitorais, decidiu-se verificar quais variáveis estão mais relacionadas ao voto em candidatos de direita ou de esquerda. Os votos para os candidatos de direita e de esquerda foram analisados em separado para as 27 unidades da federação (UF), tendo como variáveis explicativas a idade (x1) e os anos de estudo (x2) dos eleitores. Em cada UF, foram analisados os votos de y eleitores e as estatísticas descritivas das variáveis utilizadas são mostradas na tabela a seguir.
Com base nessas informações, julgue o próximo item.
A variação na quantidade de votos de candidatos de direita é
mais bem explicada por meio da variável x2 que por meio da
variável x1.
Em uma análise dos resultados das urnas eleitorais, decidiu-se verificar quais variáveis estão mais relacionadas ao voto em candidatos de direita ou de esquerda. Os votos para os candidatos de direita e de esquerda foram analisados em separado para as 27 unidades da federação (UF), tendo como variáveis explicativas a idade (x1) e os anos de estudo (x2) dos eleitores. Em cada UF, foram analisados os votos de y eleitores e as estatísticas descritivas das variáveis utilizadas são mostradas na tabela a seguir.
Com base nessas informações, julgue o próximo item.
O coeficiente angular da variável x1 dos votantes em
candidatos de direita é maior que o coeficiente angular da
variável x1 dos votantes em candidatos de esquerda.
Em uma análise dos resultados das urnas eleitorais, decidiu-se verificar quais variáveis estão mais relacionadas ao voto em candidatos de direita ou de esquerda. Os votos para os candidatos de direita e de esquerda foram analisados em separado para as 27 unidades da federação (UF), tendo como variáveis explicativas a idade (x1) e os anos de estudo (x2) dos eleitores. Em cada UF, foram analisados os votos de y eleitores e as estatísticas descritivas das variáveis utilizadas são mostradas na tabela a seguir.
Com base nessas informações, julgue o próximo item.
Se as variáveis x1 e x2 fossem incluídas simultaneamente no
modelo utilizado para explicar a quantidade de votos em
candidatos de direita, então o erro teria 24 graus de
liberdade.
O coeficiente angular estimado foi de -0,10, com erro padrão igual a 0,01. O valor da soma dos quadrados totais foi 32.
A variância residual do modelo foi de:
Diversos fatores podem influenciar o tempo que um processo leva para ser julgado. Para tentar explicar isso, um analista de um tribunal selecionou algumas variáveis e concluiu que a quantidade de atores envolvidos (X) impacta a variabilidade do tempo que um processo leva até ser julgado. A tabela de análise de variância a seguir mostra os resultados dessa modelagem.
Com base nessas informações e sabendo que existe uma correlação positiva entre as variáveis e que Var(X) = 2,35, julgue o item a seguir.
Diversos fatores podem influenciar o tempo que um processo leva para ser julgado. Para tentar explicar isso, um analista de um tribunal selecionou algumas variáveis e concluiu que a quantidade de atores envolvidos (X) impacta a variabilidade do tempo que um processo leva até ser julgado. A tabela de análise de variância a seguir mostra os resultados dessa modelagem.
Com base nessas informações e sabendo que existe uma correlação positiva entre as variáveis e que Var(X) = 2,35, julgue o item a seguir.
• Soma de Quadrados Total = 5.000;
• Soma de Quadrados dos Resíduos = 1.800;
• Graus de Liberdade Total = 40; e,
• Graus de Liberdade da Regressão = 4.
Com base nesses resultados, marque V para as afirmativas verdadeiras e F para as falsas.
( ) A estimativa não-viesada para σ é igual a 50.
( ) A amostra é composta por n = 40 observações.
( ) O modelo apresenta um total de p = 4 variáveis explicativas.
( ) A raiz quadrada do coeficiente de determinação R² é igual a 0,80.
( ) Sabendo que a região crítica (RC) do teste F associado ao problema é RC = {Fobs > 2,63} para 95% de confiança, onde Fobs representa o valor observado da estatística de teste, conclui-se que pelo menos uma das variáveis explicativas incluídas no modelo é significativa para explicar a variável dependente, com 5% de significância.
A sequência está correta em
Um analista do Ministério Público supõe que existe uma relação linear entre duas variáveis não negativas: o número de denúncias de infrações ambientas (y) e o acesso à informação e comunicação (x) de diferentes regiões administrativas. Para verificar sua hipótese, realizou um estudo e obteve o seguinte diagrama de dispersão:
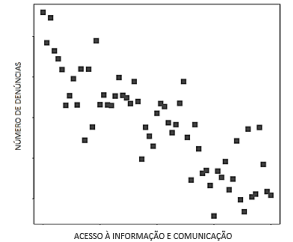
Considere que r seja o coeficiente de correlação linear amostral entre as variáveis e que b seja o coeficiente de inclinação no ajuste da reta de regressão y = a + bx aos dados observados. Com base nessas informações, é correto afirmar que:
Y = αX + β + e
pelo método de mínimos quadrados usual e mostrou as seguintes estimativas dos coeficientes: α = 3,4 e b = 0,5; além disso, obteve-se um coeficiente de correlação amostral igual a 0,9.
Com base nesses dados, avalie se as afirmativas a seguir estão corretas.
I. A porcentagem da variação total dos dados que é explicada pela regressão é menor do que 60%. II. A reta de regressão obtida ajusta bem o modelo. III. O intercepto α = 3,4 mostra que a valor grandes de x correspondem valores grandes de y.
Está correto o que se afirma em