Questões de Algoritmos e Estrutura de Dados - Estrutura de Dados para Concurso
Foram encontradas 1.370 questões
As Estruturas de Dados definem a forma como os dados serão armazenados na memória do computador. Duas das estruturas de dados mais utilizadas na computação são a Pilha e a Fila. Considere as afirmativas abaixo que comparam as estruturas de Pilha e Fila:
I - A estrutura chamada Pilha é descrita como uma estratégia LIFO - last in, first out (o último que entra é o primeiro que sai), isto é, os elementos da pilha só podem ser retirados na ordem inversa à ordem que foram introduzidos.
II - A estrutura chamada Fila é descrita como uma estratégia FIFO - first in, first out (o primeiro que entra é o primeiro que sai), isto é, os elementos da pilha só podem ser retirados na mesma ordem em que foram inseridos.
III - Uma estrutura que recebe dos dados 10, 20, 30, 40 e 50 nessa ordem e só permite a sua retirada na ordem 50, 40, 30, 20 e 10 é um exemplo de uma Pilha.
IV - Uma estrutura que recebe dos dados 10, 20, 30, 40 e 50 nessa ordem e só permite a sua retirada na ordem 50, 40, 30, 20 e 10 é um exemplo de uma Fila.
V - Um programa que usa apenas estruturas de Pilha recebe os dados 1, 2, 3, 4 e 5 nessa ordem e imprime os dados na ordem 1, 2, 3, 4 e 5 pode ter sido implementado com duas estruturas de Pilha consecutivas.
As afirmativas CORRETAS são:
De acordo com os aspectos construtivos de uma árvore de decisão, julgue o item a seguir.
A entropia de uma árvore de decisão aborda o aspecto da quantidade de informações que está associada às respostas que podem ser obtidas às perguntas formuladas, representando o grau de incerteza associado aos dados.
Uma árvore de decisão representa um determinado número de caminhos possíveis de decisão e os resultados de cada um deles, apresentando muitos pontos positivos, ou seja, são fáceis de entender e interpretar. Elas têm processo de previsão completamente transparente e lidam facilmente com diversos atributos numéricos, assim como atributos categóricos, podendo até mesmo classificar dados sem atributos definidos.
De acordo com os aspectos construtivos de uma árvore de decisão, julgue o item a seguir.
Se o processo adotado para a construção de árvores de
decisão for determinístico, uma forma de obtenção de
árvores aleatórias, que compõem as florestas aleatórias, pode
ser realizada por meio do bootstrap dos dados, em que cada
árvore é treinada com base no resultado de bootstrap_sample
(inputs).
Considere a lista duplamente encadeada exibida a seguir.
(1, 3, 0, “Verde”)
(2, 4, 3, “Azul”)
(3, 2, 1, “Amarelo”)
(4, 0, 2, “Vermelho”)
Cada elemento pertencente à lista é representado por uma quádrupla, com o seguinte formato:
(<id>, <id do anterior>, <id do seguinte>, <conteúdo>).
A ordem do conteúdo dos componentes, segundo a instância da lista apresentada, é:
Com relação a tipos abstratos de dados, julgue o próximo item.
Uma pilha oferece as operações pop para inserir um
elemento da pilha e push para remover o elemento no seu
início.
Na estrutura do tipo pilha, a mais simples das estruturas de dados, a operação de inserção de um elemento é denominada concatenação.
A estrutura de dados do tipo fila utiliza o conceito de FIFO, ou seja, os elementos são atendidos, sequencialmente, na ordem em que são armazenados.
Acerca dos Algoritmos e Estrutura de Dados, julgue o item seguinte.
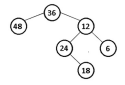
Considerando a árvore binária da figura abaixo, o resultado das consultas dos nós dessa árvore a em pré-ordem é: 18, 24, 6, 12, 48, 36.
A = “Há pessoas que choram por saber que as rosas têm espinho” B = “Há outras que sorriem por saber que os espinhos têm rosas”
A submatriz da matriz de TF-IDF desses dois documentos correspondente aos termos “Rosas”, “Choram” e “Sorriem”, nessa ordem, é:
A partição que apresenta o menor erro de classificação quando feita na raiz (primeiro nível) de uma árvore de decisão é: