Questões de Concurso
Sobre estrutura de dados em algoritmos e estrutura de dados
Foram encontradas 1.408 questões
“tipo abstrato de dados que armazena elementos de maneira hierárquica. Com exceção do elemento do topo, cada elemento da estrutura tem um elemento pai e zero ou mais elementos filhos” (GOODRICH; TAMASSIA, 2007, p. 247). Tal definição se aplica a:
80 84 55 76 72
Considerando os valores exibidos, qual árvore foi recebida como parâmetro?
A Figura a seguir exibe o conteúdo de três pilhas: P1, P2 e P3.
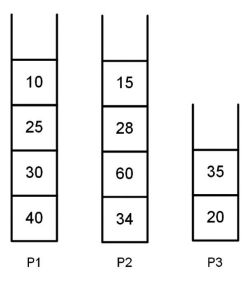
Admita que um método Java, chamado exibePilha, receba essas três pilhas como parâmetros e execute os seguintes passos:
1. Cria duas pilhas auxiliares, A1 e A2, inicialmente vazias;
2. Remove um elemento de P1 e o insere em A1. Em seguida, remove um elemento de P2 e o insere em A1. Repete esses dois procedimentos até que P1 e P2 fiquem, ambas, vazias;
3. Remove um elemento de P3 e o insere em A1. Repete esse procedimento até que P3 fique vazia;
4. Remove um elemento de A1 e o insere em A2. Repete esse procedimento até que A1 fique vazia;
5. Remove um elemento de A2 e o exibe no console. Repete esse procedimento 4 vezes.
O que será exibido no console, quando o método exibePilha for executado, tendo P1, P2 e P3 sido passadas como
parâmetros?
Quadro I - DEFINIÇÕES
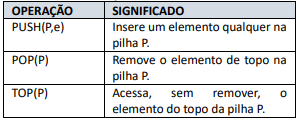
Quadro II - OPERAÇÕES

Tendo como ponto de partida uma pilha SUL inicialmente vazia e a sequência de operações indicadas no quadro II - OPERAÇÕES, ao final das operações o elemento que se encontra no topo da pilha é

A estrutura equivalente que gera o mesmo resultado, sem a ajuda de uma variável auxiliar AUX, está indicada na seguinte alternativa:
PUSH 1 PUSH 2 POP PUSH 3 POP PUSH 4 POP PUSH 5
Após a realização de todas essas operações, o número de elementos na pilha e o valor armazenado no topo da pilha serão, respectivamente,
Início [ Tipo MAT = matriz[1..3,1..3] de inteiros; MAT: M; Inteiro: i, j, X, Y; X ← 0; Y ← 0; Para i de 1 até 3 faça [ Para j de 1 até 3 faça [ Se i = j Então M[i,j] ← i + j + 1; Senão M[i,j] ← i + 2*j + 1; ] ] Para i de 1 até 3 faça [ X ← X + M[i,i]; Y ← Y + M[1,i]; ] Imprima (X+Y); ] Fim.
Ao final do algoritmo é impressa a soma (X+Y) que é igual a
I - Uma fila de prioridade armazena uma coleção de elementos priorizados que suporta a inserção de elementos arbitrários, mas suporta a exclusão de elementos em ordem de prioridade, ou seja, o elemento com prioridade mais alta pode ser removido a qualquer momento.
II - Uma fila é uma coleção de elementos que são inseridos e removidos com o princípio de que “o último que entra é o primeiro que sai”. É possível inserir elementos a qualquer momento, mas somente o elemento inserido mais recentemente pode ser removido a qualquer momento.
III - Uma pilha é uma coleção de elementos que são inseridos e removidos com o princípio de que “o primeiro que entra é o primeiro que sai”. Os elementos podem ser inseridos a qualquer momento, mas somente o elemento que está na fila há mais tempo pode ser removido em um dado momento.
Quais estão corretas?
I. É preciso inicializar a lista antes de inserir algum elemento. II. A inclusão de um elemento em uma lista encadeada simples pode ser realizada somente de duas maneiras: no início e no final da lista. III. Um elemento de uma lista encadeada simples pode ser excluído no início e no final da lista. IV. Um elemento de uma lista encadeada simples não pode ser excluído quando está no meio da lista. V. Uma lista encadeada está vazia se ela aponta para nulo.
São verdadeiros somente os seguintes:
I. Não é necessário inicializar a lista antes de inserir algum elemento. II. A inclusão de um elemento em uma lista encadeada simples pode ser realizada somente no início da lista. III. Um elemento de uma lista encadeada simples pode ser excluído somente no final da lista. IV. Um elemento de uma lista encadeada simples pode ser excluído quando está no meio da lista. V. Uma lista encadeada está vazia se o elemento inicial aponta para nulo.
Assinale a alternativa correta.
Considere a figura a seguir representando um vetor e os passos de um método de ordenação interna.
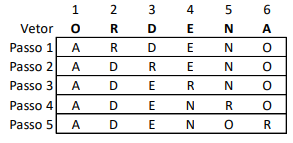
Analise as afirmativas referentes ao método de ordenação interna utilizado para ordenar o vetor:
I – O método apresentado é baseado no princípio da distribuição.
II – O método apresentado requer O(n2) comparações.
III – O método apresentado é um exemplo de ordenação por seleção.
Estão CORRETAS as afirmativas:
Analise as afirmativas referentes às estruturas de dados básicas:
I – Uma lista linear é uma sequência de zero ou mais itens x1, x2, ..., xn, em que xi é de um determinado tipo e n representa o tamanho da lista linear.
II – Uma pilha é uma lista linear em que todas as inserções, retiradas e geralmente todos os acessos, são feitos em apenas um extremo da lista.
III – Uma fila é uma lista linear em que todas as inserções são realizadas em um extremo da lista e todos os acessos e retiradas são realizados no mesmo extremo da lista.
Estão CORRETAS as afirmativas:
"Existem diversas Estruturas de Dados utilizadas na programação, quatro exemplos principais são: ______"
Assinale a alternativa que preencha corretamente a lacuna.