Questões de Concurso Sobre algoritmos e estrutura de dados
Foram encontradas 3.122 questões
Em aprendizado de máquina, especialmente em algoritmos de árvores de decisão, é fundamental avaliar como os dados são organizados e classificados em diferentes níveis da árvore. Três conceitos-chave que auxiliam na construção e otimização dessas árvores são o gini impurity, a entropy e o information gain. A respeito desses conceitos, julgue os itens a seguir.
I Gini impurity mede a redução da entropy após a divisão de um conjunto de dados com base em um atributo.
II Entropy mede a quantidade de incerteza ou impureza no conjunto de dados.
III Information gain mede a probabilidade de uma nova instância ser classificada incorretamente, com base na distribuição de classes no conjunto de dados.
Assinale a opção correta.
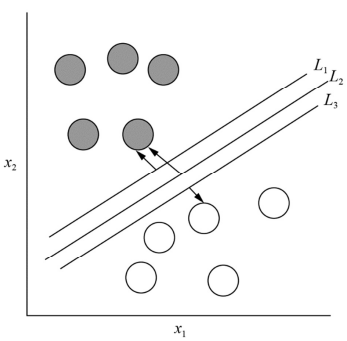
Considerando a figura precedente, assinale a opção correta em
relação ao algoritmo de SVM (support vector machine).
VAR1:= 7; VAR2:=8; VAR3:=9;
VAR4:=POP;
PUSH(VAR1);
PUSH(VAR2);
VAR1:=POP;
VAR2:=POP;
PUSH(VAR3);
PUSH(VAR1);
PUSH(VAR2);
PUSH(VAR4);
Assim, em quanto resulta o conteúdo da pilha?
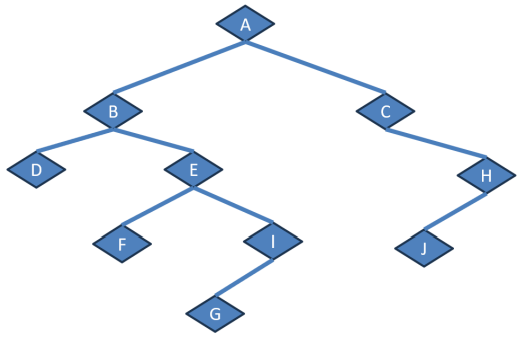
Que sequência obteremos, se executarmos o percurso em pós-ordem?
Nessa situação hipotética, a empresa possui dados do tipo
Diversas estruturas de dados, tais como árvores, pilhas, tabelas e filas, têm-se tornado comuns no universo dos programadores, e seu conhecimento se mostra fundamental em muitas áreas da computação, para os mais diferentes propósitos. Considerando as características das principais estruturas de dados conhecidas, assinale a opção correta.
I. Em uma lista não ordenada, os elementos devem estar organizados em ordem decrescente das respectivas chaves.
II. Uma lista encadeada é uma estrutura de dados, na qual os objetos estão organizados em ordem linear.
III. Em uma lista duplamente encadeada, cada elemento deve apontar para o elemento anterior e para o próximo.
Está correto o que se afirma em
I. Na fase de marcar (mark), o coletor percorre o grafo de objetos e marca todos aqueles que são alcançáveis.
II. Na fase de varrer (sweep), a memória ocupada pelos objetos marcados (na fase de marcação) é liberada.
III. Os objetos marcados (na fase de marcação) são realocados.
Está correto o que se afirma em
Relacione os métodos de agrupamento hierárquico e o K-means às suas principais características.
1. Agrupamento Hierárquico 2. K-means
( ) Seus resultados são altamente sensíveis ao número de clusters que deve ser pré-definido pelo usuário do algoritmo.
( ) Baseia-se em abordagens top-down ou bottom-up, isto é, com a divisão ou com a união sucessiva de clusters.
( ) Seus resultados costumam ser graficamente visualizados por dendrogramas, que podem ser seccionados de acordo com o número de clusters determinado pelo usuário do algoritmo.
( ) Avalia distâncias entre as instâncias de dados e os centroides dos clusters e atualiza a posição dos centroides dos clusters sucessivamente, até a convergência.
Assinale a opção que indica a relação correta, na ordem apresentada.
Com relação à análise de componentes principais, analise as afirmativas a seguir e assinale (V) para a verdadeiras e (F) para a falsa.
( ) Baseia-se na identificação dos autovetores da matriz de covariâncias dos dados, permitindo ao analista determinar direções de maiores variações nas instâncias de dados.
( ) Permite a seleção e a eliminação das dimensões referentes às direções de maiores variações nas instâncias de dados, que por sua vez contribuem com poucas informações úteis para a análise do conjunto de dados.
( ) É utilizada em compressão de dados, pois permite a representação dos dados em menos dimensões que são facilmente interpretáveis pelo analista, sem grandes perdas de informações.
As afirmativas são, respectivamente.
Analise o algoritmo a seguir.
|
algoritmo "IPERON" var X, Y, K : inteiro início X <- 13 Y <- 17 para K de 1 ate 3 faca X<-X+1 Y<- Y -1 escreva (X:3, Y:3) fimpara fimalgoritmo |
Após a execução, a saída gerada pelo algoritmo está indicada na seguinte opção de resposta:
Considere o algoritmo a seguir, apresentado na forma de uma pseudolinguagem e que implementa uma certa funcionalidade, para responder às questões de números 50 e 51.
Início
- as [
- asd Tipo TM = matriz[1..4, 1..4] de inteiros;
- asdas Inteiro: c, i, j, k;
- asda TM: Mat;
- asdas c ← 1;
- asdasd Para i de 1 até 4 faça
- asd[
- as Se (c é ímpar)
- asd[
- asas Então
- asd[ c ← c + 3*i;
- asd Para j de 1 até 4 faça
- ad[
- asdMat[i,j] ← i + j + c;
- a]
- ,]
- asas Senão
- ,[
- asasddc ← c + 2*i + 1
- asdasd; Para k de 1 até 4 faça
- [
- asdasdiiaMat[i,k] ← i + k - c;
- aaaad]
- aasa]
- aaa]
- ii,,]
- ,]
- Fim.
Considere a seguinte estrutura de dados do tipo pilha.
Considerando as operações usuais de empilhamento (PUSH) e desempilhamento (POP), com suas funcionalidades padrão, foram realizadas as seguintes operações, expressas na forma de uma pseudolinguagem:
X ← 10;
Y ← 20;
POP(Y);
PUSH(X);
POP(Y);
PUSH(Y);
PUSH(X);
Após a execução dessa sequência de operações, o novo conteúdo da pilha será, da base para o topo:
Considere o algoritmo a seguir, apresentado na forma de uma pseudolinguagem e que implementa uma certa funcionalidade, para responder às questões de números 50 e 51.
Início
- as [
- asd Tipo TM = matriz[1..4, 1..4] de inteiros;
- asdas Inteiro: c, i, j, k;
- asda TM: Mat;
- asdas c ← 1;
- asdasd Para i de 1 até 4 faça
- asd[
- as Se (c é ímpar)
- asd[
- asas Então
- asd[ c ← c + 3*i;
- asd Para j de 1 até 4 faça
- ad[
- asdMat[i,j] ← i + j + c;
- a]
- ,]
- asas Senão
- ,[
- asasddc ← c + 2*i + 1
- asdasd; Para k de 1 até 4 faça
- [
- asdasdiiaMat[i,k] ← i + k - c;
- aaaad]
- aasa]
- aaa]
- ii,,]
- ,]
- Fim.
Considere a seguinte estrutura de dados do tipo árvore.
Trata-se de uma árvore
Considere o algoritmo a seguir, apresentado na forma de uma pseudolinguagem e que implementa uma certa funcionalidade, para responder às questões de números 50 e 51.
Início
- as [
- asd Tipo TM = matriz[1..4, 1..4] de inteiros;
- asdas Inteiro: c, i, j, k;
- asda TM: Mat;
- asdas c ← 1;
- asdasd Para i de 1 até 4 faça
- asd[
- as Se (c é ímpar)
- asd[
- asas Então
- asd[ c ← c + 3*i;
- asd Para j de 1 até 4 faça
- ad[
- asdMat[i,j] ← i + j + c;
- a]
- ,]
- asas Senão
- ,[
- asasddc ← c + 2*i + 1
- asdasd; Para k de 1 até 4 faça
- [
- asdasdiiaMat[i,k] ← i + k - c;
- aaaad]
- aasa]
- aaa]
- ii,,]
- ,]
- Fim.
A comunicação entre funções de um programa com o restante do programa pode ser feita por meio de passagem e retorno de valores. O método em que uma cópia da variável é passada para a função, e que pode ser usada e também alterada dentro da função, porém sem que isso altere o conteúdo da variável original, é denominado
Considere o algoritmo a seguir, apresentado na forma de uma pseudolinguagem e que implementa uma certa funcionalidade, para responder às questões de números 50 e 51.
Início
- as [
- asd Tipo TM = matriz[1..4, 1..4] de inteiros;
- asdas Inteiro: c, i, j, k;
- asda TM: Mat;
- asdas c ← 1;
- asdasd Para i de 1 até 4 faça
- asd[
- as Se (c é ímpar)
- asd[
- asas Então
- asd[ c ← c + 3*i;
- asd Para j de 1 até 4 faça
- ad[
- asdMat[i,j] ← i + j + c;
- a]
- ,]
- asas Senão
- ,[
- asasddc ← c + 2*i + 1
- asdasd; Para k de 1 até 4 faça
- [
- asdasdiiaMat[i,k] ← i + k - c;
- aaaad]
- aasa]
- aaa]
- ii,,]
- ,]
- Fim.
O maior e o menor valor armazenados após a execução do algoritmo na matriz Mat são, respectivamente,
Considere o algoritmo a seguir, apresentado na forma de uma pseudolinguagem e que implementa uma certa funcionalidade, para responder às questões de números 50 e 51.
Início
- as [
- asd Tipo TM = matriz[1..4, 1..4] de inteiros;
- asdas Inteiro: c, i, j, k;
- asda TM: Mat;
- asdas c ← 1;
- asdasd Para i de 1 até 4 faça
- asd[
- as Se (c é ímpar)
- asd[
- asas Então
- asd[ c ← c + 3*i;
- asd Para j de 1 até 4 faça
- ad[
- asdMat[i,j] ← i + j + c;
- a]
- ,]
- asas Senão
- ,[
- asasddc ← c + 2*i + 1
- asdasd; Para k de 1 até 4 faça
- [
- asdasdiiaMat[i,k] ← i + k - c;
- aaaad]
- aasa]
- aaa]
- ii,,]
- ,]
- Fim.
Após a execução do algoritmo, o número de posições da matriz Mat que foram atualizadas é igual a
Quanto à construção de algoritmos e estrutura de dados, analise as assertivas abaixo.
I. As estruturas de dados permitem armazenar dados de forma adequada para serem processados no computador.
II. A eficiência de tempo e de espaço de armazenamento para o tipo de dados abstratos são questões relacionadas à implementação.
III. Um tipo de dado especifica um conjunto de valores e as operações que podem ser realizadas sobre tais valores.
É correto o que se afirma em
Quanto à construção de algoritmos e estrutura de dados, marque V para verdadeiro ou F para falso e, em seguida, assinale a alternativa que apresenta a sequência correta.
( ) O Método da Inserção pode ser mais eficiente do que algoritmos que tenham comportamento assintótico mais eficiente, desde que o arquivo contenha menos de 20 elementos.
( ) O Método Quicksort é o algoritmo mais eficiente para uma grande variedade de situações envolvendo ordenações.
( ) Para os casos em que os arquivos possuam milhares de elementos, é melhor utilizar o método da bolha para ordenar seus elementos.
( ) Para os casos de ordenação de arquivos com mais de 25 elementos, o algoritmo de Seleção garante até 20% de melhoria no desempenho da maioria das aplicações.
Quanto à construção de algoritmos e estrutura de dados, assinale a alternativa que obedece corretamente à condição de heap para um array A.