Questões de Concurso
Comentadas sobre data mining em banco de dados
Foram encontradas 416 questões
Com relação à técnica de clustering (agrupamento) em tarefas de Data Mining, analise a lista das notas de uma turma de alunos.
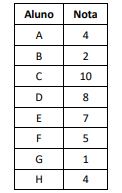
À luz do emprego do algoritmo K-means, assinale a distribuição
dos alunos, de acordo com suas notas, em quatro grupos, G0, G1,
G2 e G3.
No que se refere à qualidade e visualização de dados, julgue o item a seguir.
A discretização de frequência igual divide os dados de modo
que cada intervalo tenha aproximadamente o mesmo número
de valores.
No que se refere à qualidade e visualização de dados, julgue o item a seguir.
O tratamento de dados ausentes é prescindível, pois muitos
algoritmos de aprendizado de máquina funcionam bem com
dados incompletos.
No que se refere à qualidade e visualização de dados, julgue o item a seguir.
Matching, ou correspondência de dados, é o processo de
identificação de registros que se referem ao mesmo item na
mesma fonte de dados.
No que se refere à qualidade e visualização de dados, julgue o item a seguir.
Outliers podem ser resultantes de erros de medição, entrada
de dados ou processamento de dados, ou amostragem não
representativa.
No que se refere à qualidade e visualização de dados, julgue o item a seguir.
Para a identificação de outliers, deve-se calcular o intervalo
interquartil (IQR) e identificar dados que estão a mais de 1,5
vezes o IQR abaixo do primeiro quartil ou acima do terceiro
quartil.
A respeito de análise exploratória de dados, julgue o item a seguir.
Um dado anômalo, ou outlier, é um valor que se destaca
significativamente dos demais em um conjunto de dados e
pode ser identificado visualmente por meio do gráfico boxplot.
A respeito de análise exploratória de dados, julgue o item a seguir.
Na análise exploratória de dados, é comum categorizar os
valores não numéricos como variáveis qualitativas, que
podem ser subdivididas em discreta, como raça e cor, e em
ordinal, como tamanho de uma roupa ou classe social.
No que se refere a deep learning e mineração de dados, julgue o item subsecutivo.
A mineração de dados é comumente classificada por sua
capacidade de realizar determinadas tarefas, entre as quais
está a estimação, que, embora similar à classificação, é usada
quando o registro é identificado por um valor numérico e não
um categórico.
Considere as seguintes afirmações sobre ETL (Extrac, Transform e Load), OLAP (Online Analytical Processing) e Data Mining:
I – Em sistemas data warehouse, a aplicação é mais voltada para inserir e atualizar dados, devido ao carregamento de dados com o ETL. Já em sistemas transacionais, utilizam-se mais consultas, conforme site https://www.oracle.com/br/database/what-is-a-data-warehouse/;
II – OLAP são softwares que permitem a tomada de decisões e inteligência de negócios e agregam recursos de busca de dados, armazenagem e gerência, conforme site: https://cetax.com.br/o-que-eolap/.
III – ETL não possui suporte a SQL (structured query language), pois utiliza somente DSL (decision support language).
Assinale a alternativa CORRETA:
Utilize a figura a seguir (Fig3), que representa uma sequência de comandos em SQL, para resolver as questões de número 54 e 55.
Fig3
create table cliente
{
seq VARCHAR2(6) not null,
nome VARCHAR2(50) not null,
cpf VARÇHAR2(11) not null,
data nasc date,
dependentes numeric(2),
estcivil VARCHAR2(1)
);
arter table cliente
ADD CONSTRAINT cliente pk PRIMARY KEY (cpf)
ADD CONSTRAINT seq un unique (seq) enable
ADD CONSTRAIKT est ck check (estcivil in ('C','S','D','V')) enable
ADD CONSTRAINT cpf ch check (REGEXP LIKE(cpf, '^[[digit: ]]{11}$')) enable;
Como se chama o processo de explorar grandes quantidades de dados à procura de anomalias, padrões e correlações consistentes, tais como regras de associação ou sequências temporais, para detectar relacionamentos sistemáticos entre variáveis, detectando assim novos subconjuntos de dados?
No que se refere a modelagem dimensional, mineração de dados e big data, julgue o item subsequente.
No modelo CRISP-DM, a fase de preparação dos dados é caracterizada por atividades como análise da qualidade dos dados,
exploração dos dados, geração dos primeiros insights e formulação de hipóteses.
( ) Em um sistema BigData, o pipeline de dados implementa as etapas necessárias para mover dados de sistemas de origem, transformar esses dados com base nos requisitos e armazenar os dados em um sistema de destino, incluindo todos os processos necessários para transformar dados brutos em dados preparados que os usuários podem consumir.
( ) Dentre os métodos de manipulação de valores ausentes, em processamento massivo e paralelo, consta a normalização numérica, que se refere ao processo de ajustar os dados para que estejam em uma escala comparável, geralmente entre 0 e 1.
( ) A demanda crescente por medidas de criptografia ponta a ponta (da produção ao backup) tornam menos eficazes e relevantes tecnologias legadas, como a deduplicação de dados (data deduplication), que busca ajudar a otimizar o armazenamento e melhorar o desempenho de um sistema ao estabelecer processo de identificar e eliminar dados duplicados em um sistema.
As afirmativas são, respectivamente,