Questões de Concurso
Sobre inteligencia artificial em engenharia de software
Foram encontradas 426 questões
Com relação aos conceitos de machine learning e deep learning, julgue o item.
Para que os algoritmos de deep learning sejam capazes
de analisar dados não estruturados, é imprescindível
que haja algum tipo de pré-processamento do conjunto
de dados a ser analisado.
Com relação aos conceitos de machine learning e deep learning, julgue o item.
Entre as técnicas de machine learning, a random forest é
capaz de solucionar problemas de classificação e de
regressão, por meio da construção e dos treinamentos
de árvores de decisão.
Com relação aos conceitos de machine learning e deep learning, julgue o item.
Um dos tipos de sistema machine learning é a
aprendizagem supervisionada, que é caracterizada pela
aprendizagem de padrões com base na entrada (dados
de treinamento) e que não apresenta um feedback
explícito quanto a esse aprendizado.
Com relação aos conceitos de machine learning e deep learning, julgue o item.
Os sistemas de machine learning podem ser empregados
em situações em que os softwares tradicionais não
conseguem resolver os problemas ou que suas soluções
não são consideradas como satisfatórias.
I. Inteligência Artificial (IA) é a parte da Ciência da Computação que se destina a desenvolver sistemas capazes de resolver um problema de uma maneira tal que seja considerada inteligente quando executada por um ser humano.
II. Redes Neurais é uma técnica de IA que utiliza redes de computadores interconectados em núcleos neurais.
III. A computação cognitiva, baseada em redes neurais e deep learning, está aplicando conhecimento de ciências cognitivas para desenvolver sistemas que simulem processos do pensamento humano.
IV. Para provar que é inteligente pelo teste de Turing, um sistema (máquina) deve se comportar como um ser humano.
Está CORRETO o que se afirma, apenas, em:
Com respeito a machine learning aplicado, julgue o próximo item.
Suponha que a palavra amor ocorra 1.000 vezes no último
livro escrito por certo autor, que escreveu, no total, 10 livros.
Nesse caso, se a palavra amor for encontrada em todos os
livros desse autor, então o valor do TF-IDF (term frequencyinverse document frequency) referente à palavra amor no
último livro escrito será igual a 1/1.000.
Com respeito a machine learning aplicado, julgue o próximo item.
O CBOW é um modelo de aprendizado de máquina
desenhado para prever contexto com base em determinada
palavra.
Com respeito a machine learning aplicado, julgue o próximo item.
Stop-words constituem um conjunto de palavras que
proporcionam pouca informação para o significado de uma
frase.
Com respeito a machine learning aplicado, julgue o próximo item.
Mask RCNN (region-based convolutional neural network) é
um método para segmentação de objetos e instâncias que se
baseia em detecção, enquanto o método SSAP (single-shot
instance segmentation) se baseia em pixels.
Julgue o próximo item, relativos a redes neurais artificiais (RNA).
Uma rede neural convolucional é composta por camadas
convolucionais, unidades de processamento não linear e
camadas de subamostragem (pooling); ela possui como
característica a habilidade em explorar correlações temporais
e espaciais nos dados.
Julgue o próximo item, relativos a redes neurais artificiais (RNA).
Em RNA, o uso de early stopping, ainda que não evite o
overfitting, permite calcular com mais precisão a
classificação nos dados de validação e, assim, melhorar a
acurácia do treinamento.
Julgue o próximo item, relativos a redes neurais artificiais (RNA).
Rede neural recorrente é uma arquitetura similar à
feedforward; a diferença é que a cada nova camada oculta
(hidden layer) é acrescentada outra camada recorrente à
arquitetura conectada à camada anterior, duplicando assim a
quantidade de camadas.
Julgue o próximo item, relativos a redes neurais artificiais (RNA).
O algoritmo de backpropagation consiste das fases de
propagação e de retro propagação: na primeira, as entradas
são passadas através da rede e as previsões de saída são
obtidas; na segunda, se calcula o termo de correção dos
pesos e, por conseguinte, a atualização dos pesos.
Julgue o próximo item, relativos a redes neurais artificiais (RNA).
As funções de ativação são elementos importantes nas redes
neurais artificiais; essas funções introduzem componente não
linear nas redes neurais, fazendo que elas possam aprender
mais do que relações lineares entre as variáveis dependentes
e independentes, tornando-as capazes de modelar também
relações não lineares.
Julgue o próximo item, relativos a redes neurais artificiais (RNA).
Em RNA formada unicamente de perceptron, uma pequena
alteração nos pesos de um único perceptron na rede pode
ocasionar grandes mudanças na saída desse perceptron;
mesmo com a inserção das funções de ativação, não é
possível controlar o nível da mudança, por isso, essas redes
são voltadas para a resolução de problemas específicos, tais
como regressão e previsão de séries temporais.
Com respeito a análise de componentes principais, mistura de gaussianas e agrupamento k-means, julgue o item que se segue.
Considere a tabela abaixo que mostra as distâncias entre cada observação de um conjunto de dados hipotético e os vetores médios (centroides) do cluster correspondente ao final da aplicação do algoritmo de agrupamento k-means. Com base nessa tabela, infere-se que o cluster 1 é constituído pelas observações 2, 5 e 10.
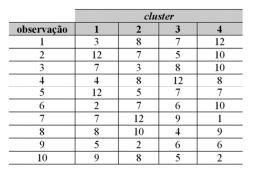
Com respeito a análise de componentes principais, mistura de gaussianas e agrupamento k-means, julgue o item que se segue.
Se a matriz de variância-covariância referente a três variáveis for
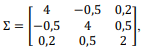
e se o menor autovalor dessa matriz for igual a 1,84, então as
duas primeiras componentes principais explicam 81,6% da
variação total referente a essas variáveis.
As máquinas de vetores de suporte (SVMs) são originalmente utilizadas para a classificação de dados em duas classes, ou seja, na geração de dicotomias. Nas SVMs com margens rígidas, conjuntos de treinamento linearmente separáveis podem ser classificados. Acerca das características das SVMs com margens rígidas, julgue o item a seguir.
Um conjunto linearmente separável é composto por
exemplos que podem ser separados por pelo menos um
hiperplano. As SVMs lineares buscam o hiperplano
ótimo segundo a teoria do aprendizado estatístico, definido
como aquele em que a margem de separação entre as classes
presentes nos dados é minimizada.
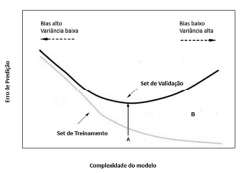
Julgue o próximo item, considerando o gráfico precedente, que representa as regiões de overfitting e de underfitting, permitindo uma avaliação do relacionamento da complexidade do modelo de aprendizagem de máquina adotado, com o erro de predição.
Quando se verifica um alto erro no treinamento com valor
próximo ao erro na validação, percebido na região à
esquerda do ponto A, tem-se um clássico problema de
underfitting, caracterizado pelo alto valor do bias.