Questões de Concurso
Sobre inteligencia artificial em engenharia de software
Foram encontradas 426 questões
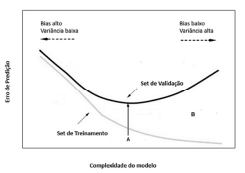
Julgue o próximo item, considerando o gráfico precedente, que representa as regiões de overfitting e de underfitting, permitindo uma avaliação do relacionamento da complexidade do modelo de aprendizagem de máquina adotado, com o erro de predição.
Considerando que a variância é um erro de sensibilidade para
pequenas flutuações no conjunto de treinamento, infere-se
que um baixo nível de variância pode fazer que o algoritmo
associado a um modelo de aprendizado de máquina perca as
relações relevantes entre os atributos de entrada e a variável
de saída, caracterizando o erro de overfitting, percebido na
região à direita do ponto A.
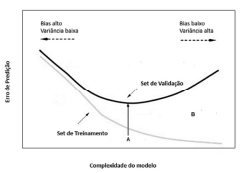
Julgue o próximo item, considerando o gráfico precedente, que representa as regiões de overfitting e de underfitting, permitindo uma avaliação do relacionamento da complexidade do modelo de aprendizagem de máquina adotado, com o erro de predição.
O Set de Treinamento é usado para qualificar o desempenho
do modelo, enquanto o Set de Validação é utilizado para
criar o modelo de aprendizado de máquina.
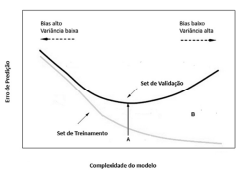
Julgue o próximo item, considerando o gráfico precedente, que representa as regiões de overfitting e de underfitting, permitindo uma avaliação do relacionamento da complexidade do modelo de aprendizagem de máquina adotado, com o erro de predição.
A região do gráfico entre as duas curvas, indicada pela letra
B, mostra a região de erro de generalização para o modelo de
aprendizado de máquina.
As métricas de avaliação de desempenho de um modelo de aprendizado de máquina, que é um componente integrante de qualquer projeto de ciência de dados, destinam-se a estimar a precisão da generalização de um modelo sobre os dados futuros (não vistos ou fora da amostra). Dentre as métricas mais conhecidas, estão a matriz de confusão, precisão, recall, pontuação, especificidade e a curva de características operacionais do receptor (ROC).
Acerca das características específicas dessas métricas, julgue o próximo item.
As curvas ROC a seguir mostram a taxa de especificidade
(verdadeiros positivos) versus a taxa de sensibilidade (falsos
positivos) do modelo adotado; a linha tracejada é a linha de
base da métrica de avaliação e define uma adivinhação
aleatória.
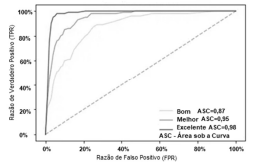
Acerca das características específicas dessas métricas, julgue o próximo item.
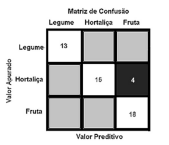
A matriz de confusão a seguir apresenta três rótulos de classe; os elementos diagonais representam o número de pontos para os quais o rótulo previsto é igual ao rotulo verdadeiro, enquanto qualquer coisa fora da diagonal teve um rótulo atribuído erroneamente pelo classificador. Quanto menores forem os valores diagonais da matriz de confusão, melhor o modelo adotado.
A Inteligência Artificial (IA) apoia o desenvolvimento de soluções tecnológicas capazes de realizar atividades similares às capacidades cognitivas humanas. Como exemplo, a plataforma Sinapses, desenvolvida pelo Tribunal de Justiça do Estado de Rondônia (TJRO) e adaptada para uso nacional, gerencia o treinamento supervisionado de modelos de IA.
Em soluções de IA, a tecnologia que possui a capacidade de melhorar o desempenho na realização de alguma tarefa por meio da experiência usando dados de treinamento, podendo ser supervisionado ou não, é o(a):
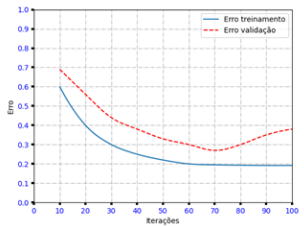
O classificador em questão foi treinado em um conjunto de dados particionado (holdout) em 60%/30%/10% (treinamento/validação/ teste). Entretanto, os especialistas envolvidos consideraram o modelo obtido insatisfatório após analisarem o gráfico.
Considerando essas informações, duas técnicas que poderiam ser utilizadas para contornar o problema encontrado são:
Das alternativas abaixo, aquela que lista apenas os modelos compatíveis com essa estratégia de caching é:
Para pesos w1 = 2, w2 = 3 e viés w0 = 1, a região de classificação é uma reta que passa nos pontos:
A respeito de inteligência artificial, julgue o item seguinte.
Aplicações de reconhecimento de voz fazem a transcrição de
um áudio para texto diretamente, sem a necessidade de
nenhum modelo intermediário.
A respeito de inteligência artificial, julgue o item seguinte.
Um dos desafios do processamento de linguagem natural
(PLN) é a polissemia, ou seja, a característica de palavras e
frases poderem ter mais de um significado.
A respeito de inteligência artificial, julgue o item seguinte.
Redes neurais do tipo LSTM (long short-term memory)
mantêm o nível de precisão independentemente do tamanho
do modelo utilizado.
A respeito de inteligência artificial, julgue o item seguinte.
Cada unidade de uma rede neural artificial possui um valor e
um peso, no seu nível mais básico, para indicar sua
importância relativa.
A respeito de inteligência artificial, julgue o item seguinte.
Uma das vantagens da técnica de árvore de decisão para
regressão é evitar a propagação de erros, mesmo que uma
divisão ocorra indevidamente.
A respeito de inteligência artificial, julgue o item seguinte.
A classificação Naive Bayes parte da suposição de que as
variáveis envolvidas em machine learning são independentes
entre si.
Com relação a noções de vírus, valor da informação, procedimentos de backup e aplicativos de segurança, julgue o item a seguir.
O valor da informação é uma função do contexto da
organização, da finalidade de utilização, do processo
decisório e dos resultados das decisões