Questões de Concurso
Sobre inteligencia artificial em engenharia de software
Foram encontradas 426 questões
Analisando a matriz de confusão, o desenvolvedor constatou que os verdadeiros positivos eram 14169, que os verdadeiros negativos eram 15360, os falsos positivos eram 1501, e os falsos negativos eram
Uma simulação é a imitação da operação de um sistema do mundo real com o objetivo de avaliá-lo. Auxiliam a análise de sistemas difíceis de abordar com a utilização de métodos analíticos. A simulação computacional permite ao experimentador analisar e comparar certos cenários de forma rápida e eficiente.
Hines et al. 2006, p. 516 (com adaptações).
Com relação ao assunto abordado no fragmento do texto acima, julgue o próximo item.
Nas redes de crenças bayesianas, as variáveis são representadas por nós com arcos que indicam as probabilidades condicionais. Entre outras aplicações, essas redes servem para prever eventos tais como falhas em transações antes que elas ocorram e para estimar correlações entre eventos.
Analise o diagrama simplificado e esquematizado abaixo:
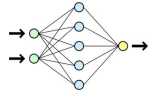
Assinale a alternativa correta sobre qual rede
se refere o diagrama.
Analise a rede neural exibida a seguir.
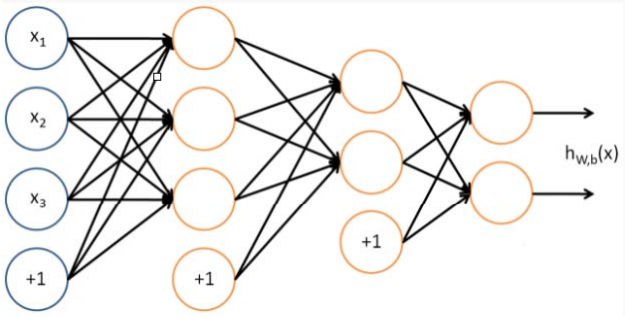
Sobre essa rede, analise as afirmativas a seguir.
I. Não possui camadas intermediárias (hidden layers).
II. Admite três sinais de entrada (input units) além do intercept term.
III. É apropriada para aplicações de deep learning.
Está correto o que se afirma em
Julgue o item que se segue acerca de engenharia de software e inteligência computacional.
São exemplos de técnicas de inteligência computacional
os algoritmos genéticos, as redes neurais e a lógica
nebulosa (fuzzy).
Julgue o item que se segue acerca de engenharia de software e inteligência computacional.
Inteligência computacional é um conjunto de métodos
e(ou) técnicas que procura desenvolver sistemas
dotados de comportamento semelhante a certos
aspectos do comportamento inteligente.
Essa tendência é denominada.
Julgue o próximo item, referente ao processamento de linguagem natural.
A saída do Word2Vec consiste em vetores densos de baixa
dimensão que representam palavras em um espaço contínuo,
onde cada palavra é mapeada para um vetor numérico no
qual cada dimensão captura uma característica da palavra.
Julgue o próximo item, a respeito de PNL (processamento de linguagem natural).
Do ponto de vista computacional, pode-se dividir o PLN em
algumas etapas; na etapa do pré-processamento de texto, este
é dividido em unidades menores, que podem ser palavras,
frases ou subpalavras, o que facilita a análise e a
compreensão textual.
Julgue o próximo item, a respeito de PNL (processamento de linguagem natural).
No PLN, após o processamento inicial, podem ser realizadas
análises no conjunto de dados, as quais estão relacionadas
aos três níveis de reconhecimento e análise: morfológico,
sintático e semântico.
No processamento de linguagem natural, é preciso realizar transformações de textos em números, geralmente vetores ou matrizes, de forma que sirvam de entrada para os algoritmos computacionais de aprendizado de máquina.
Sobre esses algoritmos de extração de características de textos, assinale a afirmativa incorreta.
O algoritmo k-means é utilizado para realizar o agrupamento de dados e opera por meio de refinamento interativo.
A redução de dimensionalidade é uma técnica que reduz a quantidade de atributos que descrevem um objeto, mantendo a integridade dos dados originais.