Questões de Concurso Sobre engenharia de software
Foram encontradas 12.234 questões
Julgue o item a seguir.
Em programação, a modularização é um conceito
ultrapassado, sendo mais comum em projetos antigos e
raramente utilizada em projetos modernos de
desenvolvimento de software. As funções e
procedimentos, que dividem o código em blocos
menores, não são mais considerados práticas eficientes
para a manutenção e escalabilidade de aplicações.
Acerca dos tipos de computadores, do Microsoft Word 2016 e do aprendizado de máquina, julgue o item.
O aprendizado de máquina pode ser definido como
uma técnica de ciência de dados que permite que os
computadores usem os dados existentes para prever
futuros comportamentos, resultados e tendências.
Acerca dos tipos de computadores, do Microsoft Word 2016 e do aprendizado de máquina, julgue o item.
O aprendizado não supervisionado é uma área da
inteligência artificial que envolve o uso de algoritmos
para encontrar padrões ocultos em conjuntos de
dados rotulados.
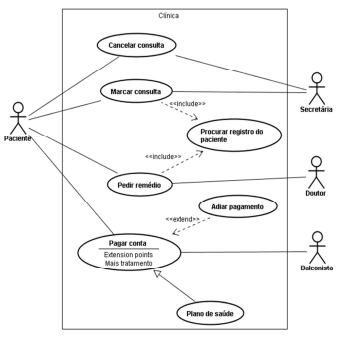
Com relação ao caso de uso acima, que está descrito em UML, assinale a opção correta.
Nesse cenário, qual é o algoritmo mais apropriado para fazer o agrupamento desejado?
Nesse contexto, considere a construção de uma árvore de regressão usando a classe DecisionTreeRegressor do ScikitLearn e seu treinamento em um conjunto de dados quadrático com max_depth=2, conforme mostrado a seguir:
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor(max_depth=2)
tree_reg.fit(X, y)
A árvore resultante é representada na Figura a seguir.
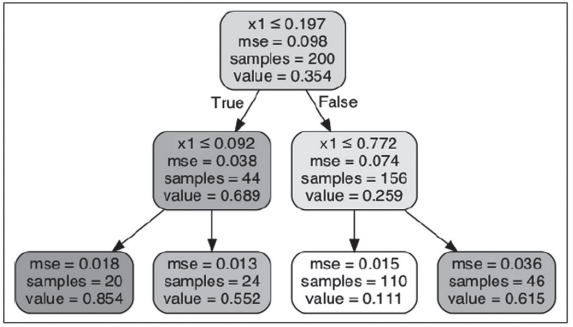
GÉRON, A. Hands-on machine learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniquesto Build Intelligent Systems. 2 ed. Sebastopol, CA: O’Reilly Media, Inc.: 2019, p. 183.
Considerando-se o cenário apresentado e que se deseja fazer uma predição para uma nova instância, com x1 = 0.6, qual será o valor predito?
A construção de um modelo preditivo a partir dos dados dessas bases, usando árvores aleatórias, Random Forests,
Qual das seguintes técnicas auxilia a prevenir o overfitting em SVM?
Com base nessas informações e considerando-se apenas a parte inteira da porcentagem, qual é o F1 Score desse modelo?
Nesse contexto, qual função do SciKit-learn ele deve utilizar para realizar essa divisão de maneira eficiente e adequada?
Para começar sua lista de stop-words, ela pode escolher listar todos os
Se o tamanho do passo for maior que o tamanho do filtro, é possível que
Ao implementar a função ReLU, um pesquisador deve seguir a fórmula: