Questões de Concurso
Sobre python em programação
Foram encontradas 732 questões
Considere o seguinte código Python 3:
x = { 'f' : 1, 'g' : 2, 'h' : 1, 'i' : 2, 'j' : 3 }
x = list ( x. values () )
x = set (x)
x = sorted (x)
print (x)
Qual será o valor impresso pelo código?
minha_lista = ['Jair', 'Samuel', 'Jailton', 'Marcos', 'Pedro'] minha_lista.sort(key=len) # a função len "número de caracteres"
# será aplicada a cada elemento da lista
print(minha_lista)
A ordem de saída será
Considere o trecho de código-fonte a seguir, escrito na linguagem de programação Python. mat = [
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]
]
A estrutura criada pelo código-fonte
import torch import torch.nn.functional as F
input = torch.randn(3, 5, requires_grad=True)
target = torch.tensor([1, 2, 0])
loss_fn = F.nll_loss loss = loss_fn(F.log_softmax(input, dim=1), target)
print(loss)
Ao ser executado, o trecho do script acima irá:
import numpy as np
a = np.arange(16).reshape(8,2).T print(a.shape, a.ndim, a[0][1])
Ao ser executado, o código acima imprime na saída padrão:

Para o código ser executado adequadamente, em coerência com o que se quer imprimir, assinale a alternativa que apresenta o que pode ser usado no lugar de “ARGUMENTO”.

Sobre sua saída, pode-se dizer que será impresso:
Acerca do tratamento e da qualidade dos dados, julgue o item que se segue.
A linguagem de programação Python é bastante utilizada no
tratamento de dados devido à sua flexibilidade e vasta
coleção de bibliotecas, permitindo a realização de
manipulações complexas nos dados, a criação de modelos
estatísticos e a automação de tarefas, além de suportar a
integração com diferentes fontes de dados.
Um analista está trabalhando em um projeto sobre o desempenho de micro e pequenas empresas no Brasil. Os dados utilizados no projeto incluem informações como faturamento anual, número de empregados e distribuição geográfica por estado. O objetivo desse projeto é criar visualizações que facilitem a análise dessas informações e identifiquem tendências regionais e setoriais.
Considerando a situação hipotética apresentada e o volume e a
complexidade dos dados utilizados, assinale a opção em que é
descrita a abordagem mais apropriada para a criação de
visualizações eficientes e informativas, utilizando-se 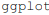 em R ou
em R ou 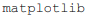 em Python.
em Python.
Assinale a opção em que é apresentado o código escrito em
Python ou em R que, se executado, gerará um scatter plot para a
visualização da relação entre quantidade de vendas e receita
gerada por determinado produto, destacando a tendência linear
entre essas variáveis.
Assinale a opção correta a respeito da implantação de um modelo
de classificação de árvore de decisão em Python.

Assinale a opção que corresponde à correta execução do código
precedente, escrito em Python.

Considerando o código precedente, escrito em Python, assinale a
opção que corresponde à sua correta execução.
O seguinte código Python utiliza o algoritmo KNN
(k-nearest neighbors) para classificação, em que o parâmetro 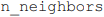 define o número de vizinhos que o classificador
KNN irá considerar para realizar a previsão.
define o número de vizinhos que o classificador
KNN irá considerar para realizar a previsão.

Com base no código precedente, é correto afirmar que, caso o
valor de fosse alterado de 3 para 4, o modelo

Qual é a saída correta desse código?

Assinale a alternativa que apresenta a saída do código.

Assinale a opção que corresponde ao resultado da execução do código precedente, desenvolvido em Python.
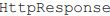 contendo o
conteúdo da página solicitada ou uma exceção como
contendo o
conteúdo da página solicitada ou uma exceção como 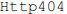 é
denominada
é
denominada