Questões de Concurso Público TCE-PA 2024 para Auditor de Controle Externo - Área Administrativa - Ciência de Dados
Foram encontradas 100 questões
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571744
Não definido
Modelos de aprendizagem de máquina são, em geral, avaliados
com métricas que indicam os quão poderosos e relevantes eles
são. Entre exemplos de métricas de avaliação utilizadas para
modelos de classificação binária, podemos citar:
• Taxa de precisão (razão entre verdadeiros positivos e o total dos verdadeiros positivos e falsos positivos); • Taxa de sensibilidade (razão entre verdadeiros positivos e o total dos verdadeiros positivos e falsos negativos, também conhecida por recall); e • Escore F1 (F1-score, também chamado de F-measure), que relaciona as taxas de precisão e de sensibilidade. Suponha a existência de um modelo de classificação binária cuja taxa de precisão é de 90,00% e cuja taxa de sensibilidade é de 75,00%. Utilize aproximação de duas casas decimais.
O escore F1 referente a esse modelo é
• Taxa de precisão (razão entre verdadeiros positivos e o total dos verdadeiros positivos e falsos positivos); • Taxa de sensibilidade (razão entre verdadeiros positivos e o total dos verdadeiros positivos e falsos negativos, também conhecida por recall); e • Escore F1 (F1-score, também chamado de F-measure), que relaciona as taxas de precisão e de sensibilidade. Suponha a existência de um modelo de classificação binária cuja taxa de precisão é de 90,00% e cuja taxa de sensibilidade é de 75,00%. Utilize aproximação de duas casas decimais.
O escore F1 referente a esse modelo é
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571745
Não definido
Diferentes técnicas de classificação são utilizadas em aprendizado
de máquina para organizar e categorizar dados de acordo com
características predefinidas.
Com respeito a técnicas de classificação em aprendizado de máquina, analise as afirmativas a seguir.
I. A regressão logística determina um hiperplano no espaço n- dimensional para separar as instâncias de dados de entrada em partições de acordo com suas classes. II. As máquinas de vetores de suporte (Support Vector Machines - SVM) consistem em uma abordagem probabilística, determinando uma distribuição de probabilidades de que uma nova instância de dados de entrada pertença as respectivas classes. III. O algoritmo K vizinhos mais próximos (K Nearest Neighbors - KNN) classifica uma nova instância de dados de entrada conforme a classe das instâncias mais próximas já observadas.
Está correto o que se afirma em
Com respeito a técnicas de classificação em aprendizado de máquina, analise as afirmativas a seguir.
I. A regressão logística determina um hiperplano no espaço n- dimensional para separar as instâncias de dados de entrada em partições de acordo com suas classes. II. As máquinas de vetores de suporte (Support Vector Machines - SVM) consistem em uma abordagem probabilística, determinando uma distribuição de probabilidades de que uma nova instância de dados de entrada pertença as respectivas classes. III. O algoritmo K vizinhos mais próximos (K Nearest Neighbors - KNN) classifica uma nova instância de dados de entrada conforme a classe das instâncias mais próximas já observadas.
Está correto o que se afirma em
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571746
Não definido
Modelos de previsão podem ser obtidos a partir do uso detécnicas de regressão. Dentre essas técnicas, pode-se citar atécnica de regressão polinomial.
Considere o conjunto de dados e a informação a seguir:
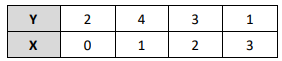
Informação: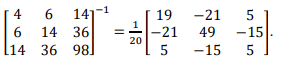
Deseja-se encontrar um modelo de regressão polinomial de 2ograu Y = α0 + α1 X + α2 X2 que melhor se encaixe nesse conjunto de dados.
Estimando-se pelo método dos mínimos quadrados, os valores deα0, α1 e α2 serão dados, respectivamente, por
Considere o conjunto de dados e a informação a seguir:
Informação:
Deseja-se encontrar um modelo de regressão polinomial de 2ograu Y = α0 + α1 X + α2 X2 que melhor se encaixe nesse conjunto de dados.
Estimando-se pelo método dos mínimos quadrados, os valores deα0, α1 e α2 serão dados, respectivamente, por
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571747
Não definido
Alguns algoritmos de aprendizado de máquina servem para
agrupar instâncias de dados em clusters, podendo ser utilizados
para tarefas como segmentação de imagens, ou segmentação
social (por exemplo, para agrupamento de clientes em uma
mesma categoria.
Dois dos mais populares algoritmos são o K-means e o DBSCAN. A respeito desses algoritmos, relacione-os com suas principais características:
1. K-means 2. DBSCAN
( ) Precisa da definição de um número inicial de agrupamentos. ( ) Mais robusto à ocorrência de outliers, por sua provável localização em regiões de baixa densidade de dados. ( ) Precisa da definição do número mínimo de vizinhos e do raio da vizinhança para determinar limites dos agrupamentos. ( ) Determina centróides dos agrupamentos e agrupa as instâncias de dados em função de uma métrica de distância entre as instâncias e os centróides.
Assinale a opção que indica a relação correta, na sequência apresentada.
Dois dos mais populares algoritmos são o K-means e o DBSCAN. A respeito desses algoritmos, relacione-os com suas principais características:
1. K-means 2. DBSCAN
( ) Precisa da definição de um número inicial de agrupamentos. ( ) Mais robusto à ocorrência de outliers, por sua provável localização em regiões de baixa densidade de dados. ( ) Precisa da definição do número mínimo de vizinhos e do raio da vizinhança para determinar limites dos agrupamentos. ( ) Determina centróides dos agrupamentos e agrupa as instâncias de dados em função de uma métrica de distância entre as instâncias e os centróides.
Assinale a opção que indica a relação correta, na sequência apresentada.
Ano: 2024
Banca:
FGV
Órgão:
TCE-PA
Prova:
FGV - 2024 - TCE-PA - Auditor de Controle Externo - Área Administrativa - Ciência de Dados |
Q2571748
Não definido
A análise de componentes principais (Principal Component
Analysis - PCA) é uma técnica de redução de dimensionalidade de
dados utilizada em diversas aplicações, tais como em compressão
de imagens e em processamento de linguagem natural.
Em relação à análise de componentes principais, avalie se as afirmativas a seguir são verdadeiras (V) ou falsas.
( ) Permite a identificação de correlações e de estruturas de menor dimensionalidade na distribuição espacial dos dados, caracterizadas pelas direções onde há maior variância. ( ) Envolve o cálculo de autovalores e autovetores de matrizes de covariâncias, determinando-se as componentes principais das distribuições de dados. ( ) É adequada para identificar correlações não-lineares entre os dados de um conjunto de alta dimensionalidade, projetando estruturas em espaços vetoriais de menores dimensões.
As afirmativas são, respectivamente,
Em relação à análise de componentes principais, avalie se as afirmativas a seguir são verdadeiras (V) ou falsas.
( ) Permite a identificação de correlações e de estruturas de menor dimensionalidade na distribuição espacial dos dados, caracterizadas pelas direções onde há maior variância. ( ) Envolve o cálculo de autovalores e autovetores de matrizes de covariâncias, determinando-se as componentes principais das distribuições de dados. ( ) É adequada para identificar correlações não-lineares entre os dados de um conjunto de alta dimensionalidade, projetando estruturas em espaços vetoriais de menores dimensões.
As afirmativas são, respectivamente,