Questões de Concurso
Foram encontradas 5.859 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2024
Banca:
FGV
Órgão:
INPE
Prova:
FGV - 2024 - INPE - Tecnologista Pleno I - Desenvolvimento ou Aprimoramento de Sistema de Assimilação de Dados nas Componentes do Sistema Terrestre e de Aplicações para Monitoramento do Processo de Assimilação |
Q2518311
Banco de Dados
A integração de técnicas de inteligência artificial e aprendizado de
máquina com assimilação de dados pode aumentar a confiabilidade
das previsões por introduzir modelos orientados a dados obtidos por
meio de observações. A performance dos modelos de aprendizado
de máquina pode ser medida por algumas métricas, como por
exemplo a métrica Mean Absolute Error (MAE).
Considere um modelo de regressão usado para prever valores de uma variável, conforme a tabela a seguir.
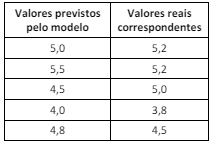
O MAE para o conjunto de dados representado na tabela será
Considere um modelo de regressão usado para prever valores de uma variável, conforme a tabela a seguir.
O MAE para o conjunto de dados representado na tabela será
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 8 - TI / Sistemas e Desenvolvimento - Tarde |
Q2518088
Banco de Dados
William está trabalhando com a base de dados de uma clínica,
onde estão presentes as entidades descritas a seguir.
Paciente (Id: Integer PK, Nome: Varchar(50)) Medico (Id: Integer PK, Nome: Varchar(50)) Atendimento (Id: Integer PK, IdPaciente: Integer FK(Paciente), IdMedico: Integer FK(Medico), Data: Date)
Para que William obtenha os nomes dos pacientes que foram tratados por todos os médicos, a instrução SQL a ser utilizada é:
Paciente (Id: Integer PK, Nome: Varchar(50)) Medico (Id: Integer PK, Nome: Varchar(50)) Atendimento (Id: Integer PK, IdPaciente: Integer FK(Paciente), IdMedico: Integer FK(Medico), Data: Date)
Para que William obtenha os nomes dos pacientes que foram tratados por todos os médicos, a instrução SQL a ser utilizada é:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 8 - TI / Sistemas e Desenvolvimento - Tarde |
Q2518067
Banco de Dados
A analista Letícia realizou a seguinte consulta em Structured
Query Language (SQL):
WITH RECURSIVE anos (n) AS (
SELECT 2020 UNION ALL SELECT n + 1 FROM anos WHERE n < 2025
)
SELECT * FROM anos
Logo após, Letícia realizou outra consulta em SQL:
SELECT 2024 FROM anos
O sistema gerenciador de banco de dados usado por Letícia suporta o recurso Common Table Expression do SQL. As consultas efetuadas por Letícia retornaram, respectivamente:
WITH RECURSIVE anos (n) AS (
SELECT 2020 UNION ALL SELECT n + 1 FROM anos WHERE n < 2025
)
SELECT * FROM anos
Logo após, Letícia realizou outra consulta em SQL:
SELECT 2024 FROM anos
O sistema gerenciador de banco de dados usado por Letícia suporta o recurso Common Table Expression do SQL. As consultas efetuadas por Letícia retornaram, respectivamente:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517662
Banco de Dados
Observe o script SQL a seguir.

O resultado JSON da execução do script apresentado é:
Ano: 2024
Banca:
FGV
Órgão:
CVM
Prova:
FGV - 2024 - CVM - Analista CVM - Perfil 7 - Ciência de Dados - Tarde |
Q2517658
Banco de Dados
As demandas de dados pelos analistas e cientistas de dados da
CVM estão aumentando a cada dia. Para atendê-las com
agilidade, é necessário obter dados de diversas fontes
heterogêneas no seu formato original para posterior seleção e
processamento sob demanda.
Para armazenar dados estruturados, não estruturados e semiestruturados, deve-se implementar um(a):
Para armazenar dados estruturados, não estruturados e semiestruturados, deve-se implementar um(a):