Questões de Concurso
Sobre análise multivariada em estatística
Foram encontradas 140 questões
No que se refere a modelagem estatística de dados, julgue o item subsecutivo.
O modelo de árvore de decisão é utilizado quando a resposta é binária, como, por exemplo, prever se um cliente fará ou não determinada compra com base em seu histórico de compras.
A respeito de inteligência artificial, de tipos de análise de dados e de Big Data, julgue o item que se segue.
Modelos discriminativos classificam dados conhecidos em categorias, enquanto modelos generativos preveem características completas a partir de um rótulo, explorando probabilidades conjuntas.
Considerando os problemas citados, analise as afirmativas a seguir.
I. Em uma tabela binária esparsa, que representa uma base de dados de transações de clientes, em que as colunas representam cada produto e as linhas cada transação, verifica-se que, frequentemente, três das colunas apresentam simultaneamente o valor 1 para vários registros. Este tipo de análise é um problema de detecção de valores discrepantes.
II. A identificação de consumidores que são similares entre si, para uso no contexto de aplicação de promoções orientadas, constitui um problema de segmentação de dados.
III. O problema de classificação de dados pode ser considerado como supervisionado, pelo fato das relações entre as classes definidas e os demais atributos dos dados serem “aprendidas” pelo modelo.
Está correto o que se afirma em
A lógica fuzzy é uma extensão da lógica booleana. Embora as técnicas de controle possam ser implementadas por modelos matemáticos, as implementações baseadas na lógica fuzzy apresentam um melhor desempenho.
Qual é o aspecto fundamental da lógica fuzzy?
xA = [2, −2, 0, 1,] e xB = [−4, 0, 2, −4].
Os valores da similaridade de cosseno e da distância de Manhattan entre essas duas instâncias são, respectivamente:
O professor instruiu o aluno de iniciação científica em
química a apresentar, em seu relatório semestral, a média
dos valores obtidos de densidade do ferro, seguido de
um indicador que representasse a exatidão da medida.
No campo da estatística, a exatidão pode ser expressa
pelo seguinte cálculo:
Em uma pesquisa sobre caraterísticas de condenados em uma determinada Vara Federal, uma amostra aleatória de condenados de tamanho n foi tomada e investigou-se nos respectivos processos suas características. Os resultados observados recebiam avaliação dos psicólogos em notas em uma escala até 7 pontos. As notas se referem às características: C1, C2, C3, C4 e C5. Os resultados foram tabulados e a matriz de correlação R construída. Após ser aplicada a Análise Fatorial na matriz R, obtiveram-se os resultados tabelados a seguir:
Análise Fatorial
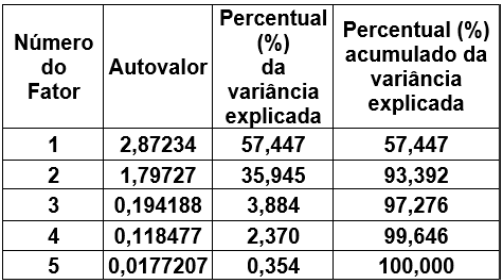
Pesos dos fatores após rotação Varimax
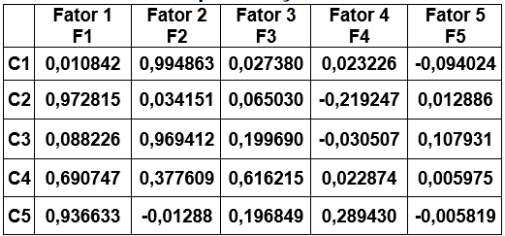
Então, é correto afirmar que
Tendo como referência as informações precedentes, julgue o item subsecutivo, a respeito de fundamentos de estatística.
Se uma amostra de hidrocarbonetos contém 5% de isoctano
em quantidade de matéria analisada pelo método descrito,
então a área sob o pico cromatográfico do isoctano terá valor
superior a 10 unidades arbitrárias.
Na análise por PCA, a primeira componente principal de um conjunto de dados representa a
O alemão Walter Christaller (1893-1969) almejou responder a questões que ainda hoje desafiam os pesquisadores: o que explica o tamanho, a distribuição e o número de cidades? Em seu livro Die zentralen Örte in Süddeutschland, Christaller seguiu a tradição geométrica alemã para esboçar as simples regras que permitiriam responder a essa pergunta e chegou à teoria dos lugares centrais. Ele buscou determinar o formato das áreas de mercado em que todos os consumidores são atendidos e, ao mesmo tempo, a distância em relação às firmas é minimizada. Para se chegar à distribuição espacial dos lugares centrais, são necessários três princípios, sendo que um deles é o da minimização das distâncias entre os centros, que faz com que os ofertantes de bens de ordem imediatamente inferior se localizem no ponto médio da linha que une os centros de ordem superior.
MONASTERIO, L.; CAVALCANTE, L. Fundamentos do pensamento econômico regional. In: CRUZ, B. et al. (org.). Economia regional e urbana. Teorias e métodos com ênfase no Brasil. Brasília, DF: Ipea, 2011, p.56. Adaptado.
Nesse texto sobre a teoria dos lugares centrais, é descrito o princípio
Quanto maior a escala da urbanização, maiores tendem a ser os ganhos de produtividade das firmas. Do mesmo modo, a maior diversidade de bens e serviços ofertados, de interações sociais e econômicas e de serviços públicos disponíveis para consumo da coletividade torna-se um diferencial de grande significado para a localização empresarial. Para o Brasil, no processo de desconcentração produtiva, mostrou-se que a localização de firmas industriais adquiriu um comportamento fortemente associado a economias de aglomeração dadas pelo estoque de infraestrutura e mão de obra qualificada: o tecido industrial tornou-se concentrado — e desconcentrou concentradamente — em uma grande porção do território entre o Sul e o Sudeste. Consideradas, de um lado, as motivações e lógicas do setor privado e os estímulos do mercado mundial e do território inercial do desenvolvimento brasileiro e, de outro lado, as motivações e os esforços governamentais, em sentido amplo, para atuação sobre novas geografias econômicas nacionais, identificam-se cinco tipos preferenciais de territórios predominantemente impactados e redefinidos pela potência das forças em atuação.
MONTEIRO NETO, A.; SILVA, R.; SEVERIAN, D. O território das atividades industriais no Brasil: a força das economias de aglomeração e urbanização. In: MONTEIRO NETO, A. (org.). Brasil, Brasis: reconfigurações territoriais da indústria no século XXI. Brasília, DF: Ipea, 2021, p. 256-258. Adaptado.
Na tipologia mencionada acima, encontram-se rearranjos territoriais que se prestam à análise das formas de aglomeração e os que concorrem para a desaglomeração.
Considerando-se especificamente os vetores que levam à concentração produtiva, identificam-se territórios predominantemente impactados e (re)definidos por
I. Na execução do algoritmo K-means, é possível que a alocação de observações aos clusters não mude entre duas iterações sucessivas.
II. O uso de duas medidas de similaridade distintas pode produzir dois dendrogramas diferentes ao se aplicar um algoritmo de agrupamento aglomerativo para o mesmo conjunto de dados.
III. Em uma análise envolvendo duas variáveis, considere que, após a primeira iteração do algoritmo K-Means aplicado para agrupar sete observações em três clusters, C1, C2 e C3, obteve-se a seguinte configuração: C1={(2,2), (4,4), (6,6)}; C2={(0,4), (4,0)} e C3={(5,5), (9,9)}. Então, os respectivos centroides que darão seguimento à próxima iteração serão C1=(4,4), C2=(2,2) e C3=(7,7).
Está correto o que se afirma em