Questões de Concurso
Sobre modelos lineares em estatística
Foram encontradas 575 questões
Acerca da avaliação de modelos de classificação, julgue o item que se segue.
Um modelo de classificação que apresenta alta revocação é
útil em contextos em que seja crucial identificar a maior
quantidade possível de casos positivos, mesmo que isso
resulte em um número maior de falsos positivos.
Acerca da avaliação de modelos de classificação, julgue o item que se segue.
A matriz de confusão, em problemas de classificação
multiclasses, é uma tabela com duas linhas e duas colunas;
na diagonal principal dessa matriz quadrada, estão os valores
corretos e, na matriz secundária, os erros cometidos pelo
modelo.
Acerca da avaliação de modelos de classificação, julgue o item que se segue.
A acurácia é uma métrica adequada para a avaliação de
modelos quando não há desbalanceamento de classes, pois
reflete com precisão a capacidade geral do modelo de fazer
previsões corretas em todas as classes.
Um modelo de regressão linear múltipla com dez coeficientes foi ajustado pelo método de mínimos quadrados ordinários, tendo produzido um coeficiente de determinação (R2) igual a 80%.
Nessa hipótese, caso o tamanho da amostra utilizado para esse ajuste tenha sido igual a 46, então o valor correspondente do coeficiente conhecido como “R2 ajustado” deve ter sido igual a
Em um modelo de regressão linear simples na forma y = ax + b + ∈, x representa a variável regressora, y denota a variável resposta e ∈ é um erro aleatório com média zero e variância 100.
Nessa hipótese, considerando-se que â denote o estimador de mínimos quadrados ordinários do coeficiente produzido por uma amostra aleatória de tamanho igual a 101 e que o desvio padrão amostral da variável regressora seja igual a 2, é correto afirmar que o desvio padrão de â será igual a
Um analista pretende ajustar um modelo de regressão linear simples com um intercepto e um coeficiente angular β, utilizando uma amostra de tamanho igual a 402.
Nessa situação, se a razão t correspondente à estimativa de β a ser obtida pelo método de mínimos quadrados ordinários for igual a 20, então o coeficiente de explicação (ou determinação) R2 proporcionado pelo modelo em tela será igual a
Considere o conjunto de dados e a informação a seguir:
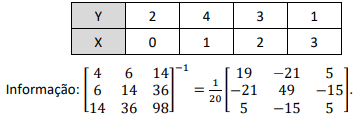
Deseja-se encontrar um modelo de regressão polinomial de 2º grau Y = a0 + a1 X + a2 X2 que melhor se encaixe nesse conjunto de dados.
Estimando-se pelo método dos mínimos quadrados, os valores de a0, a1 e a2 serão dados, respectivamente, por
Entre exemplos de métricas de avaliação utilizadas para modelos de classificação binária, é correto citar
• a taxa de precisão (razão entre verdadeiros positivos e o total dos verdadeiros positivos e falsos positivos);
• a taxa de sensibilidade (razão entre verdadeiros positivos e o total dos verdadeiros positivos e falsos negativos, também conhecida por recall); e
• o escore F1 (F1-score, também chamado de F-measure), que relaciona as taxas de precisão e de sensibilidade.
Suponha a existência de um modelo de classificação binária cuja taxa de precisão é de 90,00% e cuja taxa de sensibilidade é de 75,00%. Utilize aproximação de duas casas decimais.
O escore F1 referente a esse modelo é
Julgue o item a seguir.
Julgue o item a seguir.
A análise de covariância multivariada, utilizando um modelo linear generalizado misto, é uma abordagem estatística robusta para avaliar a relação entre múltiplas variáveis dependentes e independentes, levando em consideração a estrutura de correlação entre as variáveis dependentes e a presença de efeitos aleatórios nos dados.
Considere o conjunto de dados e a informação a seguir:
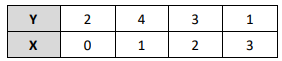
Informação:
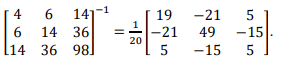
Deseja-se encontrar um modelo de regressão polinomial de 2ograu Y = α0 + α1 X + α2 X2 que melhor se encaixe nesse conjunto de dados.
Estimando-se pelo método dos mínimos quadrados, os valores deα0, α1 e α2 serão dados, respectivamente, por
Ao se considerar um modelo linear de dados transformados para encontrar as constantes α e β do modelo de regressão não-linear y = αeβx que melhor se ajusta aos dados (x1, y1),...,(xn, yn), a soma dos quadrados dos resíduos que deve ser minimizada é dada por:
A respeito de um modelo de regressão logística para uma variável resposta Y considerando a função de ligação canônica
associada ao modelo Bernoulli, chamada de logit, é INCORRETO afirmar que:
Determinado Ministério Público Estadual coletou dados nas 53 comarcas do Estado com o intuito de estudar a relação entre
o tempo médio (Y), em dias, gasto na triagem inicial de denúncias de abuso recebidas pela comarca e duas variáveis
explicativas: o número de servidores lotados no setor responsável por avaliar as denúncias na comarca (X1); e o número de
municípios atendidos pela comarca (X2). Considere o ajuste do modelo de regressão linear múltipla Yi = β0 + β1X1i + β2X2i + ɛi , onde i = 1,..., 53 e ɛ1,..., ɛ53 são erros independentes com ɛi⁓N(0, σ2) para todo i. Os seguintes resultados
foram obtidos pelo método de máxima verossimilhança: 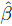 0 = 21, 5, 1 = – 2,8 e 2 = 3,5. Adicionalmente, tem-se que SQRegressão = 346,5 e SQResíduos = 185, 5. Com base nessas informações, é correto afirmar que:
0 = 21, 5, 1 = – 2,8 e 2 = 3,5. Adicionalmente, tem-se que SQRegressão = 346,5 e SQResíduos = 185, 5. Com base nessas informações, é correto afirmar que:
Assinale-a.
Uma indústria contratou um engenheiro de qualidade para realizar um experimento completamente aleatorizado com o intuito de avaliar se o tipo de equipamento usado na fabricação de certo produto tinha influência no tempo total de fabricação.
Os resultados estão dispostos na tabela a seguir.
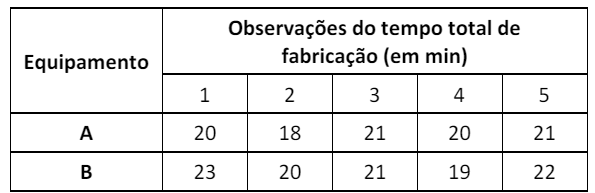
Para a realização desse experimento, o engenheiro elaborou um teste de hipótese.
Considerando que
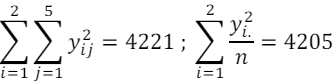
o valor calculado da estatística do teste é
Sabe-se que os modelos estatísticos de regressão foram construídos com base em algumas suposições.
Dessa forma, assinale a opção que apresenta a suposição que se aplica aos modelos de regressão múltipla e não está presente nos modelos de regressão simples.
Se a estimativa obtida para o parâmetro Φ1 foi 0,8, a estimativa do parâmetro Φ0 foi:
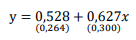
O intervalo de 95% de confiança associado ao impacto de x sobre y é (considere apenas 3 casas decimais):