Questões de Concurso
Sobre data mining em banco de dados
Foram encontradas 451 questões
Quanto à mineração de dados e ao CRISP-DM (Cross-Industry Standard Process for Data Mining), julgue o item.
Compreensão dos dados e preparação dos dados são
fases do modelo CRISP-DM.
Quanto à mineração de dados e ao CRISP-DM (Cross-Industry Standard Process for Data Mining), julgue o item.
Listagens, saídas gráficas, tabelas de resumo ou
visualizações são formatos usados na apresentação dos
resultados da mineração de dados.
Quanto à mineração de dados e ao CRISP-DM (Cross-Industry Standard Process for Data Mining), julgue o item.
A mineração de dados é uma técnica que objetiva
adquirir conhecimento a partir dos dados, por meio da
detecção de vários tipos de padrões em grandes
volumes de dados.

Utilizando técnicas de Mineração de Dados, Maria encontrou a seguinte informação:
Se um cliente compra Cacau, a probabilidade de ele comprar chia é de 50%. Cacau => Chia, suporte = 50% e confiança = 66,7%.
Para explorar a base de dados do HortVega, Maria utilizou a técnica de Mineração de Dados:
Com relação a data warehouse e data mining, julgue o item a seguir.
A análise de cluster em data mining permite, por meio de
análise exploratória de dados, ordenar casos em clusters, de
modo que o grau de associação seja forte entre os membros
do mesmo cluster e fraco entre membros de clusters
diferentes.
A respeito de data warehouse, data mining e business intelligence, julgue o item subsequente.
Sistemas de data mining viabilizam a extração de novos
padrões significativos de informação que não seriam
necessariamente encontrados por meio de meras consultas ou
processamento de dados ou metadados no data warehouse.
Em um data warehouse que use uma arquitetura de três camadas, a mineração de dados interage diretamente com as fontes de dados.
Com referência aos conceitos e técnicas de mineração de dados, julgue o item seguinte.
Em um modelo para um aprendizado supervisionado dos
dados no formato de uma árvore de decisão, um algoritmo de
construção da árvore busca minimizar a informação
necessária para classificar os dados nas partições da árvore.
Com referência aos conceitos e técnicas de mineração de dados, julgue o item seguinte.
No aprendizado não supervisionado dos dados, usa-se uma
amostra para treinamento, e os registros são colocados em
agrupamentos semelhantes entre si quanto aos seus padrões.
Com referência aos conceitos e técnicas de mineração de dados, julgue o item seguinte.
Para encontrar regras de associação negativas de interesse,
como a identificação de padrões nos dados de um arquivo, a
hierarquia é uma técnica usada com base no conhecimento
prévio sobre um conjunto de atributos do arquivo.
A respeito de inteligência do negócio, julgue o item a seguir.
Os conceitos de data warehouse (DW) e data mining (DM)
são relacionados à inteligência de negócios; a principal
diferença entre eles é que o DW atua na análise dos eventos
do passado, enquanto o DM limita-se na predição dos
eventos futuros.
Com respeito a análise de componentes principais, mistura de gaussianas e agrupamento k-means, julgue o item que se segue.
Considere que, em uma análise de agrupamentos por meio de
mistura de gaussianas, três distribuições normais com médias 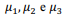 se referem, respectivamente, aos clusters 1, 2 e 3.
Nessa situação, pelo modelo de mistura de gaussianas, o
cluster 1 é constituído pelas observações mais próximas da
média
se referem, respectivamente, aos clusters 1, 2 e 3.
Nessa situação, pelo modelo de mistura de gaussianas, o
cluster 1 é constituído pelas observações mais próximas da
média 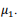
O ensemble denominado bagging tem como foco principal a redução do viés e não da variância, treinando-se os modelos em sequência, tal que os erros dos primeiros modelos treinados são utilizados para o ajuste nos pesos matemáticos dos próximos modelos.
Com relação a data warehouse e data mining, julgue o item subsequente.
A análise de data mining por padrão sequencial visa à
identificação de fatos que geram outros fatos, sempre
ocorrendo causa e consequência em momentos adjacentes.
Com relação a data warehouse e data mining, julgue o item subsequente.
A etapa de estratificação da técnica de árvore de decisão é
responsável por determinar as regras para a designação dos
casos identificados a uma categoria existente mais adequada
no data mining.