Questões de Concurso Sobre banco de dados
Foram encontradas 15.698 questões
Julgue o item seguinte, a respeito de banco de dados distribuído e orientado a objetos.
Em um banco de dados distribuído, os servidores de banco
envolvidos não precisam, necessariamente, possuir a mesma
configuração de hardware.

Tendo como referência o modelo lógico precedente, julgue o item a seguir.
O comando GRANT DELETE ON Hospital TO ebserh;
tem a finalidade de conceder o privilégio de remoção da tabela
Hospital ao usuário ebserh.
Tendo como referência o modelo lógico precedente, julgue o item a seguir.
O comando SELECT nome FROM Hospital WHERE
UF ‘SP’; permite mostrar os nomes dos hospitais
localizados na UF (unidade da federação) SP.
Tendo como referência o modelo lógico precedente, julgue o item a seguir.
Após as tabelas serem implementadas, a inserção de um registro na tabela Universidade pode ser realizada corretamente por meio do comando a seguir.
INSERT INTO Universidade VALUES
(00.038.174/0001-43, ‘Universidade de
Brasília’, ‘Graduação e Pós-Graduação’);
Tendo como referência o modelo lógico precedente, julgue o item a seguir.
Para que o modelo em questão seja implementado no sistema
gerenciador de banco de dados relacional, deve-se criar,
primeiramente, a tabela Universidade e, posteriormente, a
tabela Hospital.
Tendo como referência o modelo lógico precedente, julgue o item a seguir.
A partir do modelo apresentado, infere-se que um hospital
pode estar vinculado a várias universidades, pois a tabela
Hospital apresenta cardinalidade (0, n).
Com relação a banco de dados, julgue o item seguinte.
As soluções de big data focalizam dados que já existem,
descartam dados não estruturados e disponibilizam os dados
estruturados.
Com relação a banco de dados, julgue o item seguinte.
Na SQL (structured query language), existem funções de
agregação com diferentes capacidades; como, por exemplo, a
função AVG, que é responsável pelo cálculo da média dos
valores de determinado campo.
Com relação a banco de dados, julgue o item seguinte.
Diferentemente dos bancos de dados transacionais, a
modelagem de bancos de dados multidimensionais é
caracterizada pelo uso de tabelas fato e tabelas periféricas, que
armazenam, respectivamente, a transação e as dimensões.
Com relação a banco de dados, julgue o item seguinte.
Após um banco de dados ser criado, o administrador executa
uma série de tarefas para dar permissão de acesso aos usuários
que necessitam ler e gravar informações na base de dados. A
responsabilidade de gerir os acessos ao banco de dados é do
sistema gerenciador de banco de dados (SGBD).
Com relação a banco de dados, julgue o item seguinte.
Em normalização, a primeira forma normal é caracterizada por
uma tabela com a existência obrigatória de uma chave primária
e uma chave estrangeira.
Julgue o item que se segue, a respeito de arquitetura e tecnologias de sistemas de informação.
A descoberta de novas regras e padrões em conjuntos de dados
fornecidos, ou aquisição de conhecimento indutivo, é um dos
objetivos de data mining.
Julgue o item que se segue, a respeito de arquitetura e tecnologias de sistemas de informação.
Usualmente, os data warehouses dão apoio a análises de série
temporal e de tendências, as quais requerem maior volume de
dados históricos do que os que geralmente são mantidos em
bancos de dados transacionais.
Considere as Tabelas abaixo.
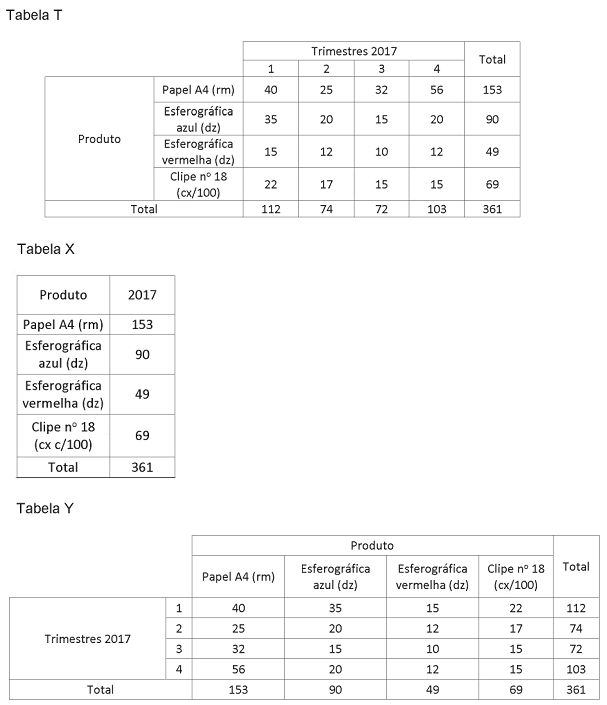
O funcionário responsável pelo controle do material de expediente de determinada agência preparou a Tabela T com o registro do consumo de alguns itens mais relevantes e apresentou-a ao seu chefe. Esse, então, solicitou que o funcionário montasse mais duas tabelas com formas diferentes de apresentação desses dados. Dadas as instruções para a realização da tarefa, o resultado foi consolidado nas Tabelas X e Y.
Considerando-se o conceito de OLAP, quais foram as operações realizadas de T para X e de T para Y, respectivamente?
Um modelo teórico do MapReduce pode ser resumido em duas funções, map e reduce. Essas funções são representadas na literatura, genericamente, com uma notação na forma:
Entrada genérica -> Saída genérica
A proposta original de MapReduce considerava que a função reduce teria o modelo:
reduce(k2,list(v2)) -> list(v3)
Enquanto implementações de terceiros usam o modelo:
reduce(k2,list(v2)) -> list(k3,v3)
O modelo para a função map, porém, é sempre o mesmo.
Qual é esse modelo?
As tabelas a seguir compõem um banco de dados simplificado de um banco comercial, onde o campo sublinhado indica a chave primária. É possível que uma conta tenha vários clientes, e que um cliente tenha várias contas.
Cliente(idCliente,nomeCliente)
Conta(idConta,ultimoSaldo)
ContaCliente(idConta,idCliente)
Que comando SQL lista todos os nomes de clientes com mais de R$ 2.000,00 na conta?
Um desenvolvedor precisava construir um modelo estrela para produzir um data warehouse sobre as transferências eletrônicas disponíveis (TED) feitas pelos correntistas do banco.
Que tabelas seriam adequadas para representar as dimensões desse modelo?
HiveQL é uma linguagem de consulta, semelhante ao SQL, para Hive. Uma das suas características interessantes é ter uma extensão que permite distribuir consultas entre reducers em um script do tipo map-reduce.
Se for necessário simultaneamente distribuir as consultas e garantir a ordenação ou o agrupamento das chaves distribuídas, deve-se usar a extensão
Um banco de dados possui um modelo conceitual cuja descrição é feita pelo diagrama E-R a seguir.
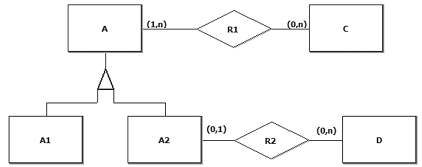
Admita-se que o estado desse banco de dados seja definido, em parte, pelos seguintes conjuntos:
A={a1 ,a2 ,a3 ,a4 ,a5 ,a6 }
A1={a2 ,a3 ,a4 }
A2={a1 ,a5 ,a6 }
C={c1 ,c2 }
D={d1 ,d2 ,d3 ,d4 }
Os elementos desses conjuntos representam instâncias das entidades presentes no diagrama E-R do banco de dados em questão.
As relações que completam o estado desse banco de dados, sem que nenhuma regra de cardinalidade ou generalização
seja violada, são