Questões de Concurso Público BANESE 2021 para Técnico Bancário III - Área de Informática - Desenvolvimento
Foram encontradas 120 questões
Quanto aos principais riscos incorridos pelas instituições financeiras bancárias, julgue o item subsequente.
As instituições não alocam capital para a cobertura do risco
de liquidez.
Considerando as novas inovações promovidas pelo open banking e pelo sistema de pagamentos do PIX, julgue o próximo item.
Os dados pertencem às instituições financeiras, razão por que
tais instituições podem, com o consentimento do cliente,
comercializá-los com terceiras partes.
Considerando as novas inovações promovidas pelo open banking e pelo sistema de pagamentos do PIX, julgue o próximo item.
O PIX consiste na plataforma pública na qual os bancos
fazem transações diretas e instantâneas com clientes e
usuários.
Considerando as novas inovações promovidas pelo open banking e pelo sistema de pagamentos do PIX, julgue o próximo item.
O open banking reduz a exposição ao risco operacional.
Acerca do Sistema Gerenciador de Banco de Dados (SGBD), julgue o item a seguir.
Tabelas lógicas são usadas para representar o modelo
hierárquico das estruturas de relação.
Acerca do Sistema Gerenciador de Banco de Dados (SGBD), julgue o item a seguir.
Os sistemas de banco de dados são classificados em modelo
relacional e modelo estruturado.
Acerca do Sistema Gerenciador de Banco de Dados (SGBD), julgue o item a seguir.
A confiabilidade (reliability) refere-se à propriedade de um
sistema estar acessível e operacional quando necessário e
retornar os resultados esperados.
Acerca do Sistema Gerenciador de Banco de Dados (SGBD), julgue o item a seguir.
O balanceamento de carga pode ser feito por meio de
appliances (hardware que implementam funcionalidades
específicas na rede) ou por software.
Acerca do Sistema Gerenciador de Banco de Dados (SGBD), julgue o item a seguir.
Uma das técnicas utilizadas para a otimização de um banco
de dados é a utilização de pool de conexões.
No que se refere a técnicas de modelagem e aplicações de data warehousing, julgue o item seguinte.
Um data warehousing transforma dados operacionais em
informação voltada à tomada de decisão estratégica. As
consultas realizadas são executadas e processadas nos
provedores de informação originais.
No que se refere a técnicas de modelagem e aplicações de data warehousing, julgue o item seguinte.
ETL é um tipo de data integration com capacidades
analíticas sofisticadas que permite que os dados sejam
analisados a partir de visões multidimensionais complexas e
elaboradas. Além disso, esse sistema possibilita alterar e
analisar grandes quantidades de dados em várias perspectivas
diferentes.
No que se refere a técnicas de modelagem e aplicações de data warehousing, julgue o item seguinte.
A modelagem multidimensional é a técnica de modelagem
de banco de dados para o auxílio às consultas do data
warehousing nas mais diferentes perspectivas. A visão
multidimensional permite o uso mais intuitivo para o
processamento analítico online.
Com respeito ao pacote reticulate da linguagem R, que propicia uma interface com os módulos, classes e funções do Python, julgue o item a seguir.
O código seguinte permite importar o módulo math para utilização no ambiente R.
library(reticulate)
math <- use_python("math")
Com respeito ao pacote reticulate da linguagem R, que propicia uma interface com os módulos, classes e funções do Python, julgue o item a seguir.
Para executar o código Python codigo.py no ambiente R, pode-se utilizar o seguinte código R.
library(reticulate)
py_read("codigo.py")
No que se refere ao pacote NumPy do Python, julgue o item subsequente.
O código a seguir retorna o valor do desvio padrão amostral do conjunto de dados {1,2,2,3,5}.
import numpy
x = numpy.array([1,2,2,3,5])
numpy.std(x,ddof=1)
No que se refere ao pacote NumPy do Python, julgue o item subsequente.
Considerando a matriz de dados  , o código a seguir
retorna as medianas dos valores encontrados na primeira
coluna, {1,2,3}, e na segunda coluna, {2,2,3}.
, o código a seguir
retorna as medianas dos valores encontrados na primeira
coluna, {1,2,3}, e na segunda coluna, {2,2,3}.
import numpy
y = numpy.array([[1, 2], [2, 2], [3, 3]])
numpy.median(y, axis=0)
Com relação aos pacotes Matplotlib e NumPy, julgue o seguinte item.
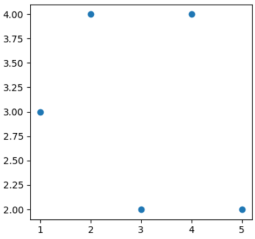
Considerando o conjunto de dados formado por pares de pontos {(1,3), (2,4), (3,2), (4,4), (5,2)}, o código a seguir produz um gráfico de dispersão na forma ilustrada na figura anterior.
import numpy
import matplotlib.pyplot as plt
x = numpy.array([1,2,3,4,5])
y = numpy.array([3,4,2,4,2])
plt.scatter(x, y)
plt.show()
Com relação aos pacotes Matplotlib e NumPy, julgue o seguinte item.
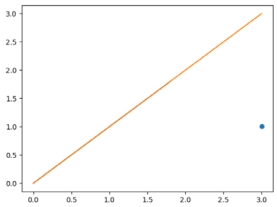
A figura anterior é gerada pelo seguinte código.
import numpy
import matplotlib.pyplot as plt
y = numpy.array([[0, 0], [1, 1], [2, 2], [1,3]])
plt.plot(y)
plt.show()
Considerando a estimação de uma média populacional μ e do desvio padrão populacional σ com base em uma amostra aleatória simples de tamanho n, julgue o item que se segue.
O desvio padrão amostral é um estimador viciado (ou
tendencioso) para a estimação de σ .
Considerando a estimação de uma média populacional μ e do desvio padrão populacional σ com base em uma amostra aleatória simples de tamanho n, julgue o item que se segue.
O erro padrão da média amostral é igual a σ.