Questões de Concurso Público Petrobras 2022 para Ciência de Dados
Foram encontradas 120 questões

Considerando a figura precedente, que mostra desenhos esquemáticos das distribuições das quantidades de cargas perdidas nos anos de 2020 e 2021, segundo o tipo de carga transportada por uma mineradora, julgue o item que se segue.
No que se refere à distribuição da quantidade de carga do
tipo B perdida em 2021, observa-se que o valor da perda
mínima foi superior a Q1 -1,5Dq, no qual Q1 representa o
primeiro quartil e Dq denota o intervalo interquartil da
distribuição em tela.
Considerando a figura precedente, que mostra desenhos esquemáticos das distribuições das quantidades de cargas perdidas nos anos de 2020 e 2021, segundo o tipo de carga transportada por uma mineradora, julgue o item que se segue.
Na distribuição da quantidade de carga do tipo A perdida em
2020, observa-se que o primeiro quartil foi superior a
100 kg, enquanto o terceiro quartil foi inferior a 50 kg.
Considerando a figura precedente, que mostra desenhos esquemáticos das distribuições das quantidades de cargas perdidas nos anos de 2020 e 2021, segundo o tipo de carga transportada por uma mineradora, julgue o item que se segue.
No desenho esquemático referente à distribuição da
quantidade de carga do tipo C perdida em 2020, os dois
pontos exteriores representam as observações destoantes das
demais, que podem ou não podem ser considerados outliers.
Considerando a figura precedente, que mostra desenhos esquemáticos das distribuições das quantidades de cargas perdidas nos anos de 2020 e 2021, segundo o tipo de carga transportada por uma mineradora, julgue o item que se segue.
Suponha que os valores das quantidades de carga perdida sejam submetidos a uma normalização numérica com base no critério do Z-score da forma
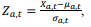
em que Xa,t denota a quantidade de carga do tipo t perdida no ano a, μa,t representa a quantidade média de carga do tipo t perdida no ano a, e σa,t , refere-se ao desvio padrão da distribuição da quantidade de carga do tipo t perdida no ano a. Como resultado dessa normalização, a média da soma
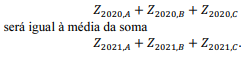
Com respeito a métodos para imputação de dados, julgue o seguinte item.
O método de imputação K-NN (k-nearest neighbours) leva
em consideração os padrões de similaridade presentes no
conjunto de dados para predizer os valores faltantes. No
entanto, a escolha da função de distância para a aplicação
desse método, como, por exemplo, HEOM (heterogeneous
euclidean-overlap metric) ou HVDM (heterogeneous value
difference metric), pode influenciar significativamente nos
resultados da imputação.