Questões de Concurso
Para técnico de planejamento e pesquisa - estruturas tecnológica produtiva e regional
Foram encontradas 254 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383287
Engenharia de Software
No aprendizado não supervisionado, os dados de treinamento não têm rótulos. O objetivo é agrupar instâncias
semelhantes em clusters. Nesse contexto, suponha que
se deseja executar um algoritmo de agrupamento para
tentar detectar grupos de visitantes semelhantes em um
blog. Em nenhum momento é informado ao algoritmo a
que grupo um visitante pertence, mas ele encontra essas conexões sem ajuda. Por exemplo, o algoritmo pode
notar que 40% dos visitantes são homens que adoram
histórias em quadrinhos e, geralmente, leem o blog à noite, enquanto 20% são jovens amantes de ficção científica
que visitam o blog durante os fins de semana, e assim
por diante. Deseja-se, nesse caso, usar um algoritmo de
agrupamento hierárquico para subdividir cada grupo em
grupos menores, o que pode ajudar a direcionar as postagens do blog para cada grupo específico.
Nesse cenário, qual é o algoritmo mais apropriado para fazer o agrupamento desejado?
Nesse cenário, qual é o algoritmo mais apropriado para fazer o agrupamento desejado?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383286
Algoritmos e Estrutura de Dados
A biblioteca Scikit-Learn emprega o algoritmo Classification And Regression Tree (CART) para treinar Árvores de Decisão.
O algoritmo CART baseia-se na recursividade e na estratégia de divisão binária para construir uma árvore de decisão.
Inicialmente, a árvore é representada por um único nó, que contém todos os dados de treinamento. A cada passo, o
algoritmo busca a melhor maneira de dividir o conjunto de dados. A recursividade continua até que uma condição de
parada seja atendida, como atingir uma profundidade máxima da árvore. Uma vez construída a árvore, a fase de predição
ocorre ao percorrer a estrutura da árvore de acordo com as condições estabelecidas nos nós, levando a uma predição
(inferência) para uma determinada entrada.
Considerando-se que n corresponde ao número de features e m ao número de instâncias, qual é a complexidade computacional assintótica de predição para árvores de decisão treinadas com o algoritmo CART?
Considerando-se que n corresponde ao número de features e m ao número de instâncias, qual é a complexidade computacional assintótica de predição para árvores de decisão treinadas com o algoritmo CART?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383285
Engenharia de Software
As árvores de decisão são um modelo de aprendizado de máquina que opera por meio da construção de uma estrutura
em forma de árvore para tomar decisões e que oferece uma compreensão clara da lógica de decisão e da hierarquia de
características que contribuem para as predições finais. Elas são versáteis e podem ser usadas tanto para tarefas de
classificação quanto para as de regressão.
Nesse contexto, considere a construção de uma árvore de regressão usando a classe DecisionTreeRegressor do ScikitLearn e seu treinamento em um conjunto de dados quadrático com max_depth=2, conforme mostrado a seguir:
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor(max_depth=2)
tree_reg.fit(X, y)
A árvore resultante é representada na Figura a seguir.
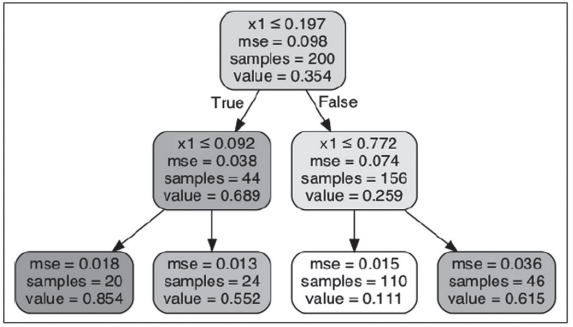
GÉRON, A. Hands-on machine learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniquesto Build Intelligent Systems. 2 ed. Sebastopol, CA: O’Reilly Media, Inc.: 2019, p. 183.
Considerando-se o cenário apresentado e que se deseja fazer uma predição para uma nova instância, com x1 = 0.6, qual será o valor predito?
Nesse contexto, considere a construção de uma árvore de regressão usando a classe DecisionTreeRegressor do ScikitLearn e seu treinamento em um conjunto de dados quadrático com max_depth=2, conforme mostrado a seguir:
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor(max_depth=2)
tree_reg.fit(X, y)
A árvore resultante é representada na Figura a seguir.
GÉRON, A. Hands-on machine learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniquesto Build Intelligent Systems. 2 ed. Sebastopol, CA: O’Reilly Media, Inc.: 2019, p. 183.
Considerando-se o cenário apresentado e que se deseja fazer uma predição para uma nova instância, com x1 = 0.6, qual será o valor predito?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383284
Estatística
Em uma nota técnica publicada em 2022 pelo Ipea, sobre
população em situação de rua, foi utilizada a técnica de
análise de componente principal (PCA).
Na análise por PCA, a primeira componente principal de um conjunto de dados representa a
Na análise por PCA, a primeira componente principal de um conjunto de dados representa a
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383283
Engenharia de Software
Em uma nota técnica do Ipea sobre emprego público nos
governos subnacionais brasileiros, no ano de 2016, aparece menção sobre o fato de as bases utilizadas possuirem outliers, ou valores atípicos.
A construção de um modelo preditivo a partir dos dados dessas bases, usando árvores aleatórias, Random Forests,
A construção de um modelo preditivo a partir dos dados dessas bases, usando árvores aleatórias, Random Forests,
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383282
Estatística
Alguns trabalhos publicados como notas técnicas pelo
Ipea se utilizam do método de classificação denominado
de Bayes Ingênuo.
No contexto do classificador Bayesiano Ingênuo, Naive Bayes, a ingenuidade do modelo é caracterizada pela(o)
No contexto do classificador Bayesiano Ingênuo, Naive Bayes, a ingenuidade do modelo é caracterizada pela(o)
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383281
Engenharia de Software
Um cientista de dados está utilizando máquinas de vetor
de suporte (SVM) em um projeto de classificação, pois
deseja evitar o overfitting do modelo aos dados de treinamento.
Qual das seguintes técnicas auxilia a prevenir o overfitting em SVM?
Qual das seguintes técnicas auxilia a prevenir o overfitting em SVM?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383280
Engenharia de Software
Em um projeto de classificação de textos, um modelo de
machine learning foi aplicado em um conjunto de teste
e apresentou os seguintes resultados: uma precisão de
80% e uma revocação de 70%.
Com base nessas informações e considerando-se apenas a parte inteira da porcentagem, qual é o F1 Score desse modelo?
Com base nessas informações e considerando-se apenas a parte inteira da porcentagem, qual é o F1 Score desse modelo?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383279
Engenharia de Software
Um pesquisador possui um conjunto de dados consistindo
em características diversas, features, e suas respectivas
classificações, labels. Ele deseja dividir esse conjunto de
dados em conjuntos distintos, para treinamento e para
teste, com o objetivo de validar a eficácia de um modelo
de aprendizado de máquina.
Nesse contexto, qual função do SciKit-learn ele deve utilizar para realizar essa divisão de maneira eficiente e adequada?
Nesse contexto, qual função do SciKit-learn ele deve utilizar para realizar essa divisão de maneira eficiente e adequada?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383278
Engenharia de Software
Uma cientista de dados percebeu que, ao processar alguns documentos, seria melhor remover palavras que
aparecem em quase todo texto, as stop-words.
Para começar sua lista de stop-words, ela pode escolher listar todos os
Para começar sua lista de stop-words, ela pode escolher listar todos os
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383277
Engenharia de Software
O método de POS-tagging, ou Part of Speech tagging, é
uma tarefa do processamento de linguagem natural em
que
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383276
Engenharia de Software
Em redes convolucionais, o tamanho do passo normalmente é menor que o tamanho do filtro.
Se o tamanho do passo for maior que o tamanho do filtro, é possível que
Se o tamanho do passo for maior que o tamanho do filtro, é possível que
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383275
Engenharia de Software
Na arquitetura de redes neurais, diferentes funções de
ativação são utilizadas nas camadas de neurônios para
aplicar transformações não lineares aos dados. Uma dessas funções é a ReLU, conhecida por sua eficácia em diversos modelos de aprendizado profundo.
Ao implementar a função ReLU, um pesquisador deve seguir a fórmula:
Ao implementar a função ReLU, um pesquisador deve seguir a fórmula:
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383274
Algoritmos e Estrutura de Dados
No gráfico XY, são apresentados pontos que representam duas propriedades de elementos de duas classes, R e S. Os
pontos da classe R, representados como círculos, são [(3,5),(3,4),(2,3)], enquanto os pontos da classe S, representados
como quadrados, são [(4,3),(4,2),(4,1),(3,1),(2,2)]. É necessário classificar pontos novos, de acordo com o algoritmo K-NN,
com K=3, considerando a distância euclidiana.
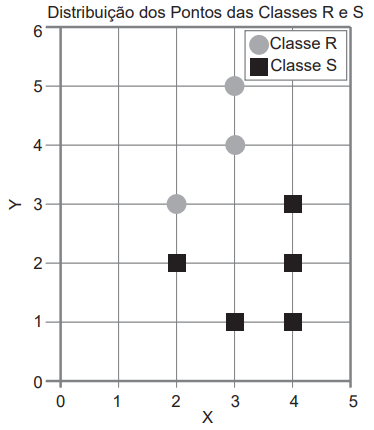
Nesse contexto, as classes dos pontos [(3,2),(3,3) e (4,4)] são, respectivamente:
Nesse contexto, as classes dos pontos [(3,2),(3,3) e (4,4)] são, respectivamente:
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383273
Engenharia de Software
Em processamento de linguagem natural, o modelo
Skip-Gram é uma técnica popular para treinar word
embeddings.
O treinamento do modelo Skip-Gram destaca-se de outras técnicas, como o Continuous Bag of Words (CBOW), por ter a seguinte característica:
O treinamento do modelo Skip-Gram destaca-se de outras técnicas, como o Continuous Bag of Words (CBOW), por ter a seguinte característica:
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383272
Algoritmos e Estrutura de Dados
Um pesquisador iniciante em aprendizado de máquina
trabalhava com um modelo de classificação binário com
as duas classes equilibradas. Inicialmente, ele fez a avaliação de seu modelo, separando 20% dos dados disponíveis para a avaliação, e o treinou com 80% dos dados,
fazendo o processo apenas uma vez. Depois, a pedido
de seu chefe, ele trocou a forma de avaliação, separando o conjunto de dados em 10 partes e escolhendo, em
10 rodadas, uma parte diferente para avaliação e as outras para treinamento.
Essas duas formas de avaliar um modelo são conhecidas, respectivamente, como
Essas duas formas de avaliar um modelo são conhecidas, respectivamente, como
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383271
Engenharia de Software
Na avaliação de um modelo criado por aprendizado de
máquina em um experimento que buscava identificar textos de opinião sobre o desempenho da economia, separando-os dos que não forneciam opinião alguma, só fatos
e dados, foi encontrada a seguinte matriz de confusão:
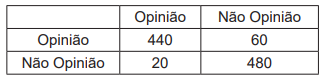
Considerando-se que, nessa matriz, as linhas indicam a resposta correta e as colunas indicam a previsão, a acurácia é de
Considerando-se que, nessa matriz, as linhas indicam a resposta correta e as colunas indicam a previsão, a acurácia é de
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383270
Estatística
Ao criar um índice para um corpus de notícias políticas,
um pesquisador decidiu usar o modelo vetorial com a medida TF-IDF.
Descobriu, porém, que essa medida pode ser calculada de várias formas, com a característica comum de calcular o peso de cada termo a partir da ideia de que esse termo
Descobriu, porém, que essa medida pode ser calculada de várias formas, com a característica comum de calcular o peso de cada termo a partir da ideia de que esse termo
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383269
Estatística
Uma pesquisa recente estudou a distribuição de renda familiar per capita, em salários mínimos (s.m.), de duas comunidades, Alfa e Beta, com, aproximadamente, o mesmo número de habitantes. Considerando-se e a base dos
logaritmos naturais ou neperianos, na comunidade Alfa,
verificou-se que tal renda pode ser bem aproximada por
uma variável aleatória contínua (v.a.c.) X com função densidade de probabilidade (f.d.p.) da forma f(X = x) = r ex,
0 ≤ x ≤ 1 s.m.; já para a comunidade Beta, constatou-
-se que a renda em estudo seguia aproximadamente a
distribuição de uma variável aleatória contínua (v.a.c.) Y
com função densidade de probabilidade (f.d.p.) da forma
g(Y = y) = s y ey, 0 ≤ y ≤ 1 s.m.
Um técnico deve decidir por apenas uma das duas comunidades para receber um programa assistencial, qual seja, aquela que possua o maior número de habitantes com renda familiar per capita até meio salário mínimo.
Nesses termos, o técnico deverá optar pela comunidade:
Dado √e ≅ 1,645
Um técnico deve decidir por apenas uma das duas comunidades para receber um programa assistencial, qual seja, aquela que possua o maior número de habitantes com renda familiar per capita até meio salário mínimo.
Nesses termos, o técnico deverá optar pela comunidade:
Dado √e ≅ 1,645
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383268
Estatística
O Quadro abaixo fornece informações sobre o índice de vendas no varejo por estado em agosto de 2023.

Um analista de dados resolveu verificar se há presença de outliers nesse conjunto de índices e decidiu fazer isso por meio de um Box Plot dos dados fornecidos.
Com base na técnica escolhida pelo analista, quantos índices podem ser enquadrados como outliers?
Um analista de dados resolveu verificar se há presença de outliers nesse conjunto de índices e decidiu fazer isso por meio de um Box Plot dos dados fornecidos.
Com base na técnica escolhida pelo analista, quantos índices podem ser enquadrados como outliers?