Questões de Concurso
Para técnico de planejamento e pesquisa - estruturas tecnológica produtiva e regional
Foram encontradas 254 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383227
Banco de Dados
Sistemas Gerenciadores de Bancos de Dados, SGBD,
via de regra, permitem acesso às suas funcionalidades
por meio de interfaces interativas e, também, por meio de
programas de apoio ou comandos específicos. O SGBD
PostgreSQL possui um conjunto de programas de apoio.
O programa a ser utilizado para realizar o backup de um
banco de dados ou de um esquema, no PostgreSQL, é o
pg_dump.
Nesse contexto, considere o seguinte comando:
pg_dump -a -Fp Alfa > Beta
Esse comando gera um backup
Nesse contexto, considere o seguinte comando:
pg_dump -a -Fp Alfa > Beta
Esse comando gera um backup
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383226
Banco de Dados
Nas últimas décadas, a automatização e a inserção de
máquinas agrícolas transformaram profundamente o
panorama do trabalho nas áreas rurais [...] e, em menos de 50 anos, a produtividade do agronegócio brasileiro aumentou 400%. [...]
Esses resultados vieram com a adoção da tecnologia nos processos cotidianos, e também com o investimento em pesquisas [...]. Agora, o agronegócio pode estar diante de um novo salto de produtividade; big data e machine learning são ferramentas que estão ganhando espaço e que podem, novamente, transformar o cenário do campo.
Disponível em: https://summitagro.estadao.com.br/tendencias-e- -tecnologia/como-big-data-e-machine-learning-sao-aplicados-no- -agronegocio/. Acesso em: 5 jan. 2024. Adaptado.
A utilização da plataforma paralela de processamento MapReduce aplica-se adequadamente como um framework de processamento de Big Data, visando à escalabilidade para as aplicações.
Nesse contexto, uma característica inerente à MapReduce é a
Esses resultados vieram com a adoção da tecnologia nos processos cotidianos, e também com o investimento em pesquisas [...]. Agora, o agronegócio pode estar diante de um novo salto de produtividade; big data e machine learning são ferramentas que estão ganhando espaço e que podem, novamente, transformar o cenário do campo.
Disponível em: https://summitagro.estadao.com.br/tendencias-e- -tecnologia/como-big-data-e-machine-learning-sao-aplicados-no- -agronegocio/. Acesso em: 5 jan. 2024. Adaptado.
A utilização da plataforma paralela de processamento MapReduce aplica-se adequadamente como um framework de processamento de Big Data, visando à escalabilidade para as aplicações.
Nesse contexto, uma característica inerente à MapReduce é a
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383225
Banco de Dados
Sistemas de bancos de dados apresentam benefícios e
desafios potencializados quando é possível adotar uma
solução de gerência distribuída, coordenada por um sistema de banco de dados distribuído.
Nesse contexto, uma importante questão de projeto refere-se à
Nesse contexto, uma importante questão de projeto refere-se à
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383224
Banco de Dados
O Banco Nossa Caixa é o primeiro banco do hemisfério sul a implantar o GDPS (Processamento Paralelo em Locais Geograficamente Distantes, na sigla em
inglês), sistema que processa, simultaneamente, todos os dados da instituição em dois locais fisicamente
separados. A tecnologia garante o armazenamento e
a continuidade do funcionamento de todos os canais
de atendimento e de negócios do banco, ainda que a
operação de um dos equipamentos responsáveis por
essas funções seja interrompida por um blecaute ou incêndio, por exemplo. O banco investiu R$ 80 milhões
no projeto, que levou quatro anos desde a concepção
até a implantação.
Do Banco Nossa Caixa
Disponível em: https://www.saopaulo.sp.gov.br/ultimas-noticias/ nossa-caixa-usa-sistema-pioneiro-de-processamento-de-dados/. Acesso em: 5 jan. 2024.
No modelo de arquitetura Massively Parallel Processor, MPP, extensibilidade e escalabilidade são características comuns e vantajosas no armazenamento e no processamento de dados paralelos.
Nesse contexto, qual modelo de processamento se enquadra à arquitetura MPP?
Do Banco Nossa Caixa
Disponível em: https://www.saopaulo.sp.gov.br/ultimas-noticias/ nossa-caixa-usa-sistema-pioneiro-de-processamento-de-dados/. Acesso em: 5 jan. 2024.
No modelo de arquitetura Massively Parallel Processor, MPP, extensibilidade e escalabilidade são características comuns e vantajosas no armazenamento e no processamento de dados paralelos.
Nesse contexto, qual modelo de processamento se enquadra à arquitetura MPP?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383223
Banco de Dados
Apesar de existirem diversas aplicações reais em que há
necessidade de ingestão periódica de dados, em algumas
a ingestão em lote pode não ser vantajosa, como, por
exemplo, em
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383222
Banco de Dados
Para melhorar o processamento de grandes volumes de
dados através de computação paralela ou distribuída,
pode-se utilizar sharding, técnica que divide os dados em
partes menores, chamadas shards. Essas partes são normalmente armazenadas em diferentes nós, ou sítios, de
processamento em um sistema distribuído.
O sharding é necessário para garantir a
O sharding é necessário para garantir a
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383221
Banco de Dados
Existem várias abordagens para a ingestão de dados,
sendo cada uma delas adequada para determinado tipo
de necessidade e de cenário.
No caso da ingestão de dados em tempo real, streaming, os dados são
No caso da ingestão de dados em tempo real, streaming, os dados são
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383220
Banco de Dados
O Ecossistema Spark tem componentes que oferecem
funcionalidades específicas que o tornam uma ferramenta
versátil e eficiente para o processamento de grandes
volumes de dados, a análise em tempo real, o aprendizado
de máquina e muito mais. Essa integração e flexibilidade
são algumas das razões pelas quais o Spark se tornou
uma ferramenta amplamente utilizada em aplicações
de Big Data. Os componentes da Plataforma Spark
pertencem a dois grupos principais: os componentes
básicos e os componentes especializados, que provêm
funcionalidades mais avançadas. Dentre os componentes
básicos, podemos destacar o Spark Core, também
conhecido como “coração” do Ecossistema, e que é
responsável pelas tarefas consideradas essenciais.
O componente Spark Core
O componente Spark Core
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383219
Sistemas Operacionais
No contexto da ciência de dados em cloud computing, e
considerando-se as soluções de Plataforma como Serviço
(PaaS), as de Infraestrutura como Serviço (IaaS) e as de
Software como Serviço (SaaS), constata-se que
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa -Ciência de Dados |
Q2383218
Banco de Dados
O processo de ingestão de dados é normalmente dividido
em três etapas principais:
1 - Extração, ou coleta, de dados das fontes disponíveis;
2 - Transformação dos dados coletados para que atendam às necessidades específicas de processamento e análise; e
3 - Carga dos dados em algum repositório de destino, como um banco de dados relacional ou um data lake.
Essas três etapas podem variar dependendo de os dados serem estruturados ou não.
Nesse contexto, verifica-se que, na etapa de
1 - Extração, ou coleta, de dados das fontes disponíveis;
2 - Transformação dos dados coletados para que atendam às necessidades específicas de processamento e análise; e
3 - Carga dos dados em algum repositório de destino, como um banco de dados relacional ou um data lake.
Essas três etapas podem variar dependendo de os dados serem estruturados ou não.
Nesse contexto, verifica-se que, na etapa de
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Infraestrutura de Tecnologia da Informação |
Q2383217
Banco de Dados
Em um diagrama de entidades e relacionamentos (DER), as entidades são representadas por meio de retângulos, e os
relacionamentos, por meio de losangos. No DER, um retângulo representa um conjunto de entidades. Tanto as entidades quanto os relacionamentos podem possuir atributos. Todas as entidades em um DER precisam possuir um atributo
especial, denominado atributo identificador. Nesse contexto, considere que uma entidade PESQUISADOR, em um DER,
representa um conjunto de pessoas que são pesquisadores.
Nesse caso, o atributo identificador da entidade PESQUISADOR
Nesse caso, o atributo identificador da entidade PESQUISADOR
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Infraestrutura de Tecnologia da Informação |
Q2383216
Banco de Dados
Considere que, em um banco de dados preparado para persistir dados de apoio à realização de estudos na área agropecuária, existem duas tabelas:
IMÓVEL (cod-sncr, denominacao, cod-mun, area-total)
MUNICÍPIO (cod-mun, uf, qtd-imoveis)
A chave primária de um imóvel é o seu código no Sistema Nacional de Cadastro Rural (SNCR), e a de um município é o seu código, segundo o IBGE. A coluna IMÓVEL.cod-mun é chave estrangeira e referencia MUNICÍPIO.cod-mun.
Uma aplicação, ou sistema, realiza regularmente a seguinte transação nesse banco de dados:
Início da transação
Inserção dos dados de um novo imóvel na tabela IMÓVEL
Atualização de qtd-imoveis na tabela MUNICÍPIO
Commit
Nesse exemplo, a propriedade de atomicidade de uma transação garantirá que
IMÓVEL (cod-sncr, denominacao, cod-mun, area-total)
MUNICÍPIO (cod-mun, uf, qtd-imoveis)
A chave primária de um imóvel é o seu código no Sistema Nacional de Cadastro Rural (SNCR), e a de um município é o seu código, segundo o IBGE. A coluna IMÓVEL.cod-mun é chave estrangeira e referencia MUNICÍPIO.cod-mun.
Uma aplicação, ou sistema, realiza regularmente a seguinte transação nesse banco de dados:
Início da transação
Inserção dos dados de um novo imóvel na tabela IMÓVEL
Atualização de qtd-imoveis na tabela MUNICÍPIO
Commit
Nesse exemplo, a propriedade de atomicidade de uma transação garantirá que
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Infraestrutura de Tecnologia da Informação |
Q2383215
Banco de Dados
Considere que, em um banco de dados, há uma tabela com dados de indústrias, contendo os seguintes atributos:
INDUSTRIA (cnpj, razao-social, capital-social, qtd-alteracoes)
Nessa tabela, a chave primária é o atributo cnpj.
Foi criada a seguinte stored procedure, codificada segundo a sintaxe do PostgreSQL:

Ao ser executada, essa procedure
INDUSTRIA (cnpj, razao-social, capital-social, qtd-alteracoes)
Nessa tabela, a chave primária é o atributo cnpj.
Foi criada a seguinte stored procedure, codificada segundo a sintaxe do PostgreSQL:
Ao ser executada, essa procedure
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Infraestrutura de Tecnologia da Informação |
Q2383214
Banco de Dados
Considere que um modelo conceitual de dados foi criado, por meio da utilização de um Diagrama de Entidades e Relacionamentos (DER), contendo as entidades UF e EMPRESA, e um relacionamento entre essas duas entidades denominado
GERACAO. O objetivo é representar a potência instalada total, em kW, por cada empresa em cada UF. Em uma UF, pode
haver várias empresas com geração de energia, e cada empresa pode gerar energia em várias UF.
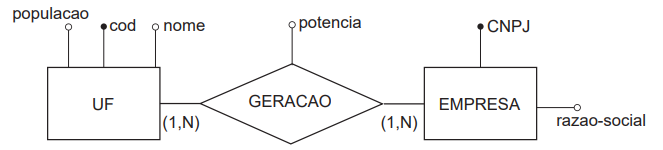
O atributo identificador na entidade UF é cod; o atributo identificador na entidade EMPRESA é CNPJ.
Foram criadas tabelas, segundo o Modelo Relacional, derivadas do DER apresentado.
O conjunto de tabelas corretamente derivadas do DER apresentado nas quais as chaves primárias encontram-se sublinhadas é
O atributo identificador na entidade UF é cod; o atributo identificador na entidade EMPRESA é CNPJ.
Foram criadas tabelas, segundo o Modelo Relacional, derivadas do DER apresentado.
O conjunto de tabelas corretamente derivadas do DER apresentado nas quais as chaves primárias encontram-se sublinhadas é
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Infraestrutura de Tecnologia da Informação |
Q2383213
Banco de Dados
A tabela PESSOA, criada segundo os conceitos do Modelo Relacional para a realização de estudos na área da saúde,
possui os seguintes atributos:
PESSOA (CPF, nome, sexo, idade, RG, renda, município-residência, UF-residência)
A chave primária dessa tabela é o atributo CPF.
Nesse contexto, considere as seguintes dependências funcionais (DF) definidas para alguns dos atributos da tabela PESSOA:
CPF → nome
CPF → renda
CPF → município-residência
Município-residência → UF-residência
RG → nome
Considerando-se a definição da primeira, da segunda e da terceira formas normais, 1FN, 2FN e 3FN, respectivamente, a tabela PESSOA NÃO está na
PESSOA (CPF, nome, sexo, idade, RG, renda, município-residência, UF-residência)
A chave primária dessa tabela é o atributo CPF.
Nesse contexto, considere as seguintes dependências funcionais (DF) definidas para alguns dos atributos da tabela PESSOA:
CPF → nome
CPF → renda
CPF → município-residência
Município-residência → UF-residência
RG → nome
Considerando-se a definição da primeira, da segunda e da terceira formas normais, 1FN, 2FN e 3FN, respectivamente, a tabela PESSOA NÃO está na
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Infraestrutura de Tecnologia da Informação |
Q2383212
Banco de Dados
O IBGE é responsável no Brasil pela Classificação Nacional de Atividades Econômicas (código CNAE). Considere que
um órgão de atuação nacional, que possui infraestrutura de Tecnologia de Informação e Comunicação (TIC) em todos os
estados brasileiros, deseja realizar um censo de pequenas e médias empresas em 10 estados do Brasil. Para guardar os
dados dessas empresas, foi criado um banco de dados distribuído (BDD) relacional com particionamento horizontal, também conhecido como sharding em muitos SGBDs NoSQL, utilizando como critério de distribuição a UF onde se localiza
a sede da empresa, de tal modo que as empresas do Rio de Janeiro têm seus dados guardados na infraestrutura de TIC
desse órgão no Rio de Janeiro.
Com os dados distribuídos dessa forma,
Com os dados distribuídos dessa forma,
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Infraestrutura de Tecnologia da Informação |
Q2383211
Programação
Em se tratando da persistência de dados, os bancos de dados orientados a documentos se mostram adequados para
representar e armazenar dados que possuem características comuns, mas que também possuem características distintas
entre si. Um dos formatos muito utilizados para representação de dados em um banco de dados orientados a documentos
é o formato Javascript Object Notation (JSON).
Nesse contexto, considere o exemplo em JSON apresentado a seguir, que representa dados de um livro da área de banco de dados:

No exemplo apresentado, observa-se que
Nesse contexto, considere o exemplo em JSON apresentado a seguir, que representa dados de um livro da área de banco de dados:
No exemplo apresentado, observa-se que
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Infraestrutura de Tecnologia da Informação |
Q2383210
Banco de Dados
Considere que um banco de dados foi criado para dar apoio à avaliação de instrumentos e políticas de gestão de trânsito no Brasil, nos últimos cinco anos. Os dados foram organizados e persistidos nas três seguintes tabelas, definidas de
acordo com modelo relacional de dados: SINISTRO, com dados dos acidentes de trânsito; MUNICIPIO, com dados de
municípios; e RODOVIA, com dados de rodovias estaduais e federais.
SINISTRO (cod-sinistro, data-e-hora, localizacao, cod-rodovia, cod-municipio, quantidade-de-vitimas)
RODOVIA (cod-rodovia, nome, estadual-ou-federal)
MUNICIPIO (cod-municipio, uf, quantidade-de-habitantes)
Os atributos que formam as chaves primárias de cada tabela estão sublinhados.
Na tabela SINISTRO, há duas chaves estrangeiras: cod-rodovia, que indica onde ocorreu o sinistro, caso ele tenha ocorrido em uma rodovia, e cod-municipio, que indica em que municipio ocorreu o sinistro.
Nesse contexto, considere o seguinte comando SQL:
SELECT S.cod-rodovia, S.data-e-hora, quantidade-de-vitimas FROM SINISTRO S WHERE S.cod-rodovia IN ( SELECT R.cod-rodovia FROM RODOVIA R WHERE R.estadual-ou-federal = 'federal') AND EXISTS ( SELECT * FROM MUNICIPIO M WHERE M.cod-municipio = S.cod-municipio AND M.quantidade-de-habitantes < 50000)
Os resultados produzidos pela execução desse comando apresentam o código da rodovia, a data e hora e a quantidade de vítimas de sinistros ocorridos em
SINISTRO (cod-sinistro, data-e-hora, localizacao, cod-rodovia, cod-municipio, quantidade-de-vitimas)
RODOVIA (cod-rodovia, nome, estadual-ou-federal)
MUNICIPIO (cod-municipio, uf, quantidade-de-habitantes)
Os atributos que formam as chaves primárias de cada tabela estão sublinhados.
Na tabela SINISTRO, há duas chaves estrangeiras: cod-rodovia, que indica onde ocorreu o sinistro, caso ele tenha ocorrido em uma rodovia, e cod-municipio, que indica em que municipio ocorreu o sinistro.
Nesse contexto, considere o seguinte comando SQL:
SELECT S.cod-rodovia, S.data-e-hora, quantidade-de-vitimas FROM SINISTRO S WHERE S.cod-rodovia IN ( SELECT R.cod-rodovia FROM RODOVIA R WHERE R.estadual-ou-federal = 'federal') AND EXISTS ( SELECT * FROM MUNICIPIO M WHERE M.cod-municipio = S.cod-municipio AND M.quantidade-de-habitantes < 50000)
Os resultados produzidos pela execução desse comando apresentam o código da rodovia, a data e hora e a quantidade de vítimas de sinistros ocorridos em
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Infraestrutura de Tecnologia da Informação |
Q2383209
Banco de Dados
As relações entre países podem assumir várias formas, como, por exemplo, as de natureza econômica, política ou militar.
Em muitos casos, essas relações são formalizadas por meio de tratados internacionais que podem envolver dois ou mais
países. As relações que os países têm entre si são de particular interesse da área de estudo denominada Relações Internacionais.
Uma forma bastante adequada de modelar relacionamentos entre objetos em um banco de dados é utilizar um modelo de grafos, um dos modelos populares dos chamados bancos de dados NoSQL. Nesse modelo, os dados são representados por meio de nós e relacionamentos, ou arestas. Dois dos tipos de grafos comuns, implementados por gerenciadores de banco de dados, são o Resource Description Framework (RDF) e o Labeled Property Graph (LPG).
A respeito desses tipos de grafos, verifica-se que as(os)
Uma forma bastante adequada de modelar relacionamentos entre objetos em um banco de dados é utilizar um modelo de grafos, um dos modelos populares dos chamados bancos de dados NoSQL. Nesse modelo, os dados são representados por meio de nós e relacionamentos, ou arestas. Dois dos tipos de grafos comuns, implementados por gerenciadores de banco de dados, são o Resource Description Framework (RDF) e o Labeled Property Graph (LPG).
A respeito desses tipos de grafos, verifica-se que as(os)
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Infraestrutura de Tecnologia da Informação |
Q2383208
Banco de Dados
Segundo os resultados apresentados pela Pesquisa Anual de Comércio (PAC) realizada em 2021 pelo IBGE, o
Brasil possuía cerca de 1.039.000 empresas comerciais
da área varejista, com cerca de 7.413.000 pessoas trabalhando nessas empresas em 31/12 daquele ano. Uma organização criou e populou um banco de dados relacional
para a realização de estudos nessa área, com as tabelas
EMPRESA, FUNCIONÁRIO, PRODUTO e VENDA, entre
outras.
Nesse contexto, considere que, quando um determinado comando SELECT, que realiza acesso aos dados logicamente relacionados das quatro tabelas citadas, é executado no contexto apresentado, ele possui um alto tempo de resposta. Foi, então, avaliado que, dentre outras medidas, o desempenho da execução desse comando precisa ser aprimorado.
Nesse caso, é necessário observar se no plano de execução desse comando há
Nesse contexto, considere que, quando um determinado comando SELECT, que realiza acesso aos dados logicamente relacionados das quatro tabelas citadas, é executado no contexto apresentado, ele possui um alto tempo de resposta. Foi, então, avaliado que, dentre outras medidas, o desempenho da execução desse comando precisa ser aprimorado.
Nesse caso, é necessário observar se no plano de execução desse comando há