Questões de Concurso
Sobre amostragem em estatística
Foram encontradas 1.261 questões
Suponha que uma amostra aleatória simples x1, x2, ..., x25 de
tamanho 25 seja observada para se testar 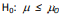 versus
versus 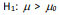 de uma variável populacional suposta normalmente
distribuída com média
de uma variável populacional suposta normalmente
distribuída com média 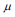 e variância
e variância 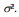 Faça
Faça 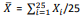 e
e 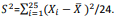
Nesse caso, a estatística T de teste usual, que tem distribuição t-Student com 24 graus de liberdade sob 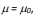 , é dada por
, é dada por
Uma amostra de idades de 52 crianças e adolescentes foi obtida e resultou nos seguintes dados (já ordenados)

A distância interquartil das idades é igual a
Uma empresa do ramo de turismo procurou um analista de mercado para realizar uma pesquisa de satisfação do seu serviço. Supondo que o nível de significância adotado pelo analista foi de 5% e que o tamanho da amostra foi de 2401 indivíduos, assinale a opção que indica o erro amostral utilizado na pesquisa.
Dado: 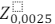 = 1,96.
= 1,96.
Com a intenção de estimar um parâmetro θ desconhecido, foram
propostos dois estimadores 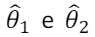 que satisfazem
que satisfazem 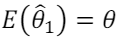 e
e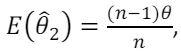 onde n é o número de amostras.
onde n é o número de amostras.
Considere que foi proposto um novo estimador 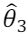 o qual é definido
pela seguinte equação:
o qual é definido
pela seguinte equação: 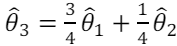 .
.
O estimador será tendencioso para estimar 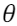 , com um viés igual
a
, com um viés igual
a
Com relação à inferência de conclusões sobre uma população específica a partir de uma investigação baseada em amostragem, analise as afirmativas a seguir.
I. No processo experimental, incidentes como a concepção inadequada do procedimento experimental são considerados fontes de erro aleatório.
II. A utilização da amostragem aleatória permite a avaliação do
grau de precisão dos resultados a partir dos próprios dados
obtidos.
III. A garantia da confiabilidade dos resultados depende
exclusivamente do dimensionamento criterioso da amostra.
Está correto o que se afirmar em
Uma fábrica de produção de peças realiza o controle estatístico de seu processo por meio do monitoramento dos gráficos de controle da média e da amplitude e considerando amostras de tamanho 4. Com o processo sob controle verificou-se que a média era igual a 5cm e o desvio-padrão igual a 1cm. Sabe-se que em um determinado momento a média do processo se deslocou para 5,76cm e que não houve aumento na variabilidade.
Consideração: Suponha que os gráficos adotem limites de 3 desvios-padrão e considere que P(Z ≤ 5) = 1 e P(Z ≤ 0,52) = 0,70.
Assinale a opção que indica a probabilidade de detectar em até duas amostras esse deslocamento por meio do gráfico de controle da média.
Deseja-se realizar um teste de hipótese para investigar se duas marcas de balanças eletrônicas fazem a medição do peso com a mesma homogeneidade. Suponha que as amostras das duas balanças foram selecionadas de duas populações normais independentes.
Dessa forma, a estatística do teste apropriada para a realização desse teste de hipótese é a
Uma empresa do ramo de turismo procurou um analista de mercado para realizar uma pesquisa de satisfação do seu serviço. Supondo que o nível de significância adotado pelo analista foi de 5% e que o tamanho da amostra foi de 2401 indivíduos, assinale a opção que indica o erro amostral utilizado na pesquisa.
Dado: 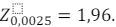
Sabe-se que λ tem distribuição Gama com parâmetros α e β e que Y = ∑i Xi.
Então, a distribuição a posteriori de λ é
1. norma L1 das componentes do vetor;
2. norma L2 das componentes do vetor;
3. soma dos valores absolutos (módulos) dos desvios de cada componente do vetor em relação à mediana de todos;
4. raiz quadrada da soma dos quadrados dos desvios em relação à sua média, isto é, o numerador do desvio padrão.
A respeito da comparação entre os valores assumidos por essas medidas, a única afirmativa correta é:
Avalie se as seguintes condições são necessárias para a consistência do estimador de MQO.
I. A distribuição de probabilidade dos erros do modelo deve ser uma distribuição Normal.
II. A correlação entre as variáveis explicativas do modelo e o termo de erro deve convergir para zero.
III. Os erros do modelo devem ter média igual a zero.
Está correto o que se apresenta em
A conclusão a que se pode chegar com base na ciência estatística é:
Observação: Considere a estatística teste utilizada como sendo exatamente igual a 2,58 para o grau de confiança desejado.

Tendo como referência as informações precedentes, julgue o próximo item.
Na amostragem aleatória estratificada, cada estrato constitui
uma unidade amostral.
Com relação aos questionários como técnica de coleta de dados, analise as afirmativas a seguir.
I. A técnica de questões de escolha múltipla é facilmente tabulável e proporciona uma exploração em profundidade quase tão boa quanto a de perguntas abertas.
II. A combinação de respostas múltiplas com as respostas abertas possibilita mais informações sobre o assunto, sem prejudicar a tabulação.
III. Questionários atingem maior número de pessoas simultaneamente, obtêm respostas mais rápidas e exatas e abrangem uma área geográfica mais ampla.
Marque a opção que indica a(s) afirmativa(s) CORRETA(S).
As técnicas de amostragem, tal como o planejamento amostral, são amplamente utilizadas nas pesquisas científicas e de opinião para se conhecer alguma característica da população.
Foi realizada uma pesquisa com 200 estudantes de uma população de 10 mil. O grupo de alunos dessa instituição era composto de 30% de calouros, 30% de estudantes do segundo ano, 20% do terceiro e 20% do último. Foram selecionados, de modo aleatório, 60 estudantes, dos 3 mil calouros; 60, dos 3 mil do segundo ano; 40, dos 2 mil do terceiro e 40, dos 2 mil do último.
A técnica demonstrada pelo exemplo descrito refere-se à
amostragem
O conceito se refere à técnica de amostragem do tipo:
Uma distribuição Binomial realiza 100 ensaios.
O valor máximo que a variância dessa variável pode assumir é: