Questões de Concurso Sobre estatística
Foram encontradas 11.637 questões
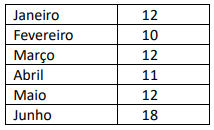
Nessa situação hipotética, a moda do conjunto de dados apresentados na tabela é igual a:
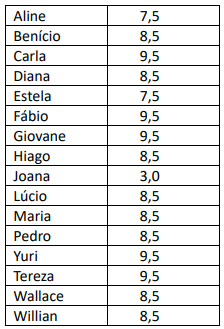
Qual a média aritmética das notas da turma, excluindo a nota de Joana que foi a pior nota?

No que se refere a mediana dos tempos dos alunos na competição universitária, assinale a alternativa correta.
I. Responsável pela coleta, organização, descrição e resumo dos dados observados.
II. A partir de um determinado conjunto de dados, a Estatística Descritiva busca organizá-los em tabelas (ou gráficos) e estabelecer um sumário por meio de medidas descritivas como a média, os valores mínimo e máximo, o desvio padrão, entre outras.
III. A estatística se divide em três grandes ramos: estatística descritiva (também chamada de indutiva), estatística probabilística, estatística inferencial (também chamada de dedutiva).
Um estudo tem o objetivo de verificar se existe independência entre tipos de crimes e regiões de um país. A seguinte Tabela de Contingência mostra os números observados em uma amostra aleatória de tamanho n = 789 casos registrados nas regiões.
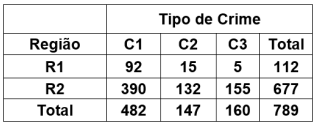
Sabe-se que 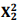 = 27,91 e P( > 27,91) = 0,0000.
Então, é correto afirmar que as frequências
esperadas das células (C1, R2) e (C3, R1), o
valor-p e a decisão quanto à relação entre Tipo de
Crime e Região, do teste da hipótese de
independência entre Tipo de Crime e Região,
serão:
= 27,91 e P( > 27,91) = 0,0000.
Então, é correto afirmar que as frequências
esperadas das células (C1, R2) e (C3, R1), o
valor-p e a decisão quanto à relação entre Tipo de
Crime e Região, do teste da hipótese de
independência entre Tipo de Crime e Região,
serão:
Supondo que [X1, X2 , ... , Xn] seja uma amostra aleatória da variável aleatória X com distribuição Poisson
com parâmetro θ, ou seja, P(θ), é correto afirmar que
A forma geral de representar uma classe de séries temporais não estacionárias é o modelo utorregressivo integrado médias móveis de ordem (p, d, q), ou seja, ARIMA(p, d, q), em que p é o grau do polinômio aracterístico da parte autorregressiva Φ(B), q é o grau do polinômio característico da parte média móveis θ(B) e d é o grau de diferenciação ▽d, ou seja, Φ(B)▽dZt = θ(B)at em que ⊽dZt = ωt. Desse modo, tem-se Φ(B)ωt = θ(B)at que é um modelo ARMA(p, q).
A uma determinada série temporal, ajustou-se um
modelo da classe ARIMA(p, d, q), e os resultados
do ajuste estão expostos a seguir:
Modelo ARIMA ajustado à série temporal
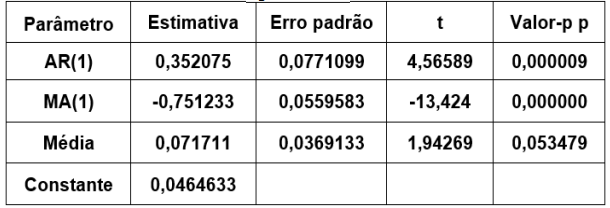
Então, é correto afirmar, com aproximação de três
(03) casas decimais, que
Considere a seguinte série temporal:
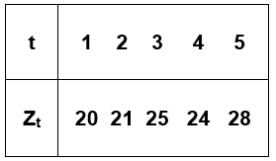
É correto afirmar que a média, a variância e a
autocorrelação de defasagem 2 dessa série
temporal, assumindo o estimador de máxima
verossimilhança para a variância, são,
respectivamente:
Os seguintes gráficos correspondem a
determinada série temporal e foram obtidos em
uma análise exploratória antes de ajustar um
modelo de previsão:
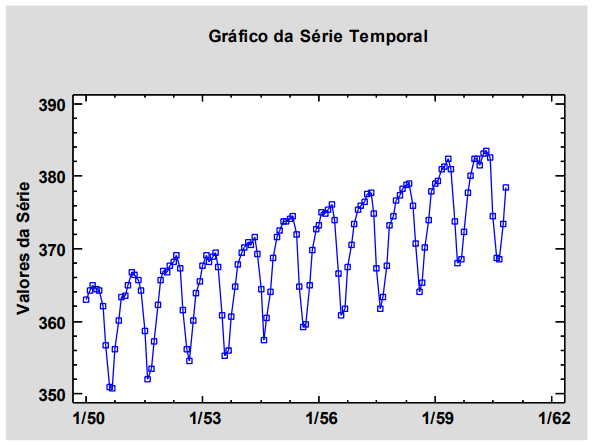
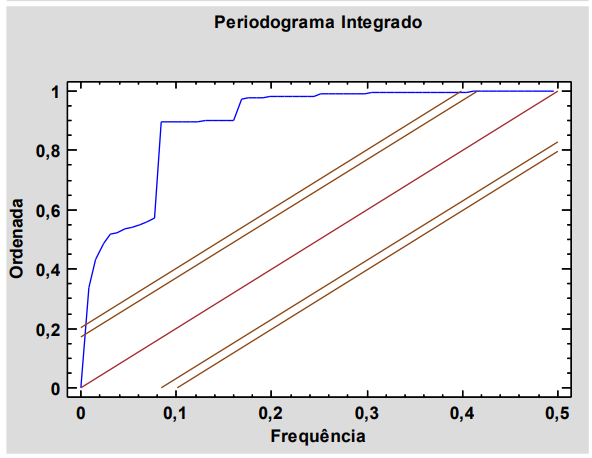
Observando os gráficos, é correto afirmar que
Seja a amostra aleatória de tamanho pequeno [X1, X2, ... , X10] de uma variável aleatória X com distribuição de probabilidade normal com média μ e variância σ2, então, as estatísticas x̄–μ/σ/√10, x̄–μ/s/√10, x̄–μ/σ e x̄–μ/s têm quais distribuições, respectivamente?
Em uma amostra aleatória com n = 25, observações da variável aleatória X que representam uma característica quantitativa foram obtidas por um estatístico que precisa estimar a média μ e o desvio-padrão σ da população (distribuição) de onde a amostra foi tomada por intervalo de nível 95% deconfiança. A análise dos dados forneceu os seguintes resultados: média amostral x̄ = 21,980 e desvio-padrão amostral s = 2,11877. O teste de Shapiro-Wilk, para verificar a Normalidade dos dados, resultou em W = 0,972867 e valor-p p = 0,721053; o escore t24,0,975 = 2,0639 e os escores X224;0,975 = 39,3641 e X224;0,025 = 12,4012.
Então, é correto afirmar que os intervalos de confiança para a média μ e o desvio-padrão σ são, respectivamente,
Se a variável aleatória X tem distribuição normal
com média μ e variância σ2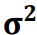 , ou seja, X ⁓ N(μ, σ2), s2 =
, ou seja, X ⁓ N(μ, σ2), s2 = 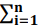 (xi–x̄)2/n–1 (variância amostral) é a estimativa
de σ2 com base em uma amostra com n
observações, [x1, x2, ... , xn]. Assim, a variável T = X – μ/s tem distribuição t de Student com n – 1
graus de liberdade, ou seja, T ~ tn-1. Nesse
caso, sabendo que P(T ≤ 2) = 0,968027 e P(T ≥ -2) = 0,031973, é correto afirmar que
(xi–x̄)2/n–1 (variância amostral) é a estimativa
de σ2 com base em uma amostra com n
observações, [x1, x2, ... , xn]. Assim, a variável T = X – μ/s tem distribuição t de Student com n – 1
graus de liberdade, ou seja, T ~ tn-1. Nesse
caso, sabendo que P(T ≤ 2) = 0,968027 e P(T ≥ -2) = 0,031973, é correto afirmar que
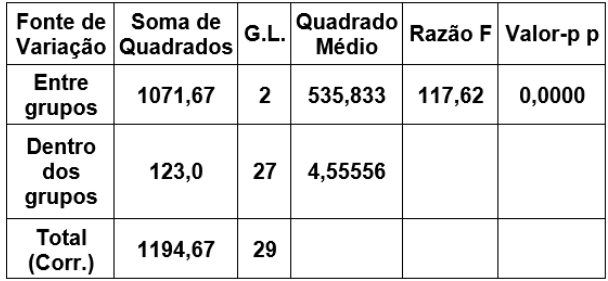
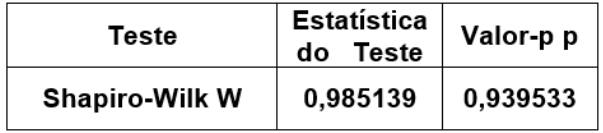
Um estatístico conduziu um experimento para verificar se existem diferenças estatisticamente significativas entre os resultados quantitativos de três procedimentos aplicados em amostras independentes. Os resultados obtidos com o experimento são:
Tabela da Análise da Variância – ANOVA
Teste de Levene para hipótese de variâncias iguais

Teste de Normalidade para os resíduos da ANOVA
Teste de Kruskal-Wallis para hipótese de medianas iguais
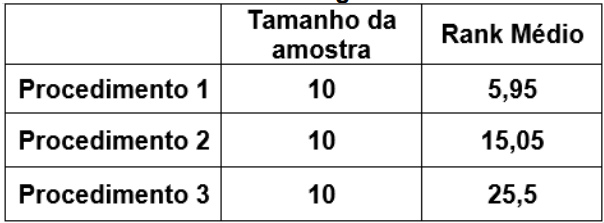
Estatística do Teste = 24,8078 Valor-p p =
0,0000041025
Então, é correto afirmar, em relação ao nível de
significância de 5%, que
A Razão das Chances é definida pela razão entre a probabilidade de sucesso e a probabilidade de insucesso, ou seja, p/1–p. Então, assumindo y = β0 + β1X1 + ... + βp-1Xp-1 = X' β , tem-se no Modelo Logístico p = p(X) = p(X1, X2, ... , Xp-1) = ey/ey+1 = 1/1+e-y= 1/1+e-x'β. Portanto, a Razão das Chances no Modelo Logístico é
O estatístico que trata da análise de dados
referentes à Justiça Federal necessita conduzir
um estudo que requer informações sobre
determinada característica quantitativa, X, dos
processados em determinada Vara Federal. Um
dos objetivos é construir um intervalo de 95% de
confiança para o valor médio da característica
quantitativa do grupo de processados, com erro
de amostragem ou precisão de 0,5 σ, meio
desvio-padrão. Ele tomou, então, uma amostra
aleatória piloto de tamanho n0 = 5 que forneceu as
seguintes estatísticas amostrais, média e
variância, para a característica: x̄0 = 127,6 e S = 1290,8. A respeito das informações
anteriores, sabe-se que é possível assumir o
modelo de distribuição normal para a
característica quantitativa do grupo de
processados, que é finito com N = 2000 indivíduos
e com variância desconhecida. Assim,
conhecendo o escore da distribuição t de t4 (0,975) = 2,78, é correto afirmar que o tamanho
definitivo da amostra n é
= 1290,8. A respeito das informações
anteriores, sabe-se que é possível assumir o
modelo de distribuição normal para a
característica quantitativa do grupo de
processados, que é finito com N = 2000 indivíduos
e com variância desconhecida. Assim,
conhecendo o escore da distribuição t de t4 (0,975) = 2,78, é correto afirmar que o tamanho
definitivo da amostra n é
O estatístico de uma Vara Federal necessita verificar se a idade média dos condenados por prevaricação e a dos condenados por corrupção passiva são iguais. Para isso tomou amostras aleatórias de tamanhos: n1 = 15 de condenados por prevaricação e n2 = 20 condenados por corrupção passiva. As amostras forneceram as estatísticas: média amostral x̄1 = 25 anos e desvio-padrão amostral s1 = 2 anos do grupo da prevaricação e x̄2 = 31 anos e desvio-padrão amostral s2 = 3,5 anos do grupo da corrupção passiva. Verificou-se, aplicando os testes, que as amostras eram provenientes de distribuição normal, mas com variâncias desconhecidas e diferentes. Então, foi aplicado o teste adequado à situação e obteve-se, para a estatística do teste, o valor